 大数据的CURD与查询优化
大数据的CURD与查询优化





 本文探讨了大数据背景下CURD操作的特点,并指出查询比数据修改更为频繁。文章提出通过预编译批量查询加上利用物化视图及即时查询处理增量数据变化的方法来优化传统Oracle数据库的性能。
本文探讨了大数据背景下CURD操作的特点,并指出查询比数据修改更为频繁。文章提出通过预编译批量查询加上利用物化视图及即时查询处理增量数据变化的方法来优化传统Oracle数据库的性能。
When talking about Big data, most people think of data in the volume perspective, which is essentially true, but there are also other dimensions such as data variaty and data relationships.
Just like other alternative solutions in the internet industry, CURD is the basic operations for data, then we also know that queries happen much more offen then data modifications. In terms of storage, the data is centralized, while in terms of usage, data can be analysised from different angles.
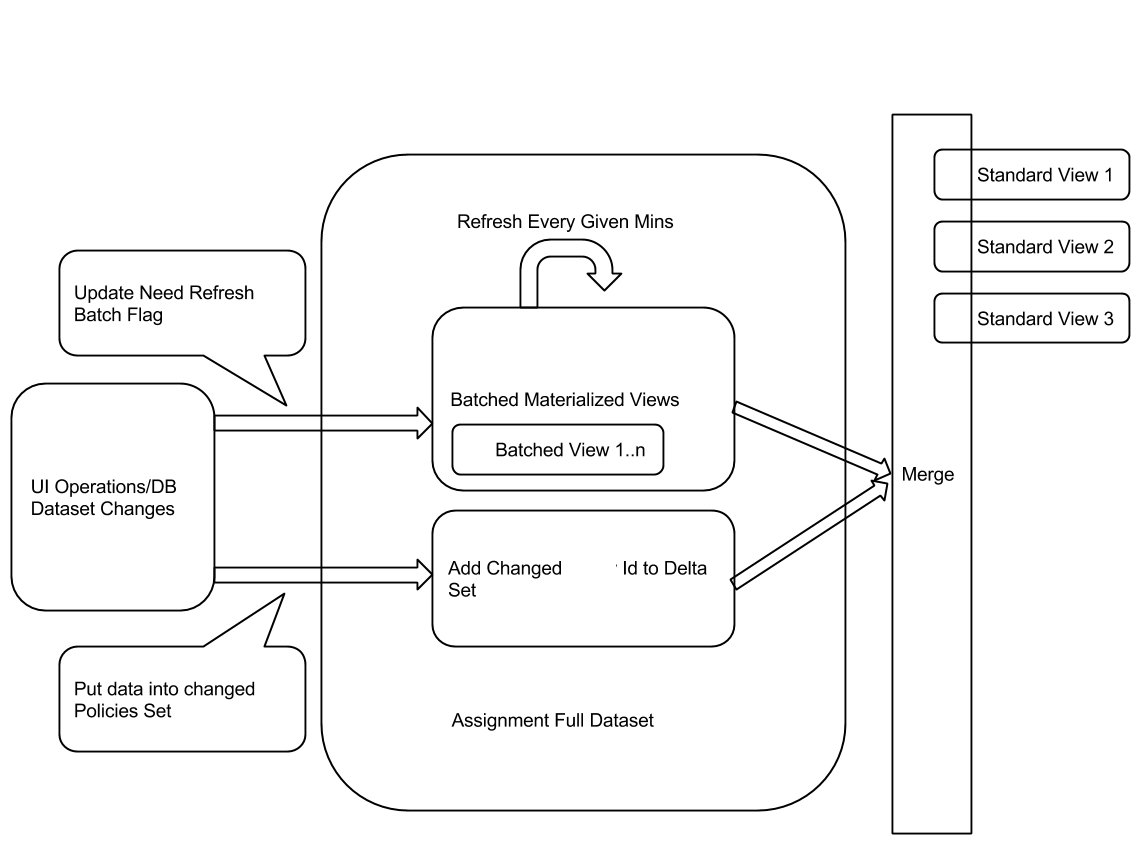
For the triditional Oracle DB, we can also take advantage of this idea - make pre-compiled batched queried plus the delta data changes using materialized views and in-time queries. The pic attached describes the idea.

















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









