



 本文详细介绍Hive中用户自定义函数(UDF)的开发方法,包括针对简单数据类型的UDF和复杂数据类型的GenericUDF。通过示例展示了如何使用Java实现MD5哈希和字符串切分功能。
本文详细介绍Hive中用户自定义函数(UDF)的开发方法,包括针对简单数据类型的UDF和复杂数据类型的GenericUDF。通过示例展示了如何使用Java实现MD5哈希和字符串切分功能。
关键字:Hive udf、UDF、GenericUDF
Hive中,除了提供丰富的内置函数(见[一起学Hive]之二–Hive函数大全-完整版)之外,还允许用户使用Java开发自定义的UDF函数。
开发自定义UDF函数有两种方式,一个是继承org.apache.hadoop.hive.ql.exec.UDF,另一个是继承org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
如果是针对简单的数据类型(比如String、Integer等)可以使用UDF,如果是针对复杂的数据类型(比如Array、Map、Struct等),可以使用GenericUDF,另外,GenericUDF还可以在函数开始之前和结束之后做一些初始化和关闭的处理操作。
UDF
使用UDF非常简单,只需要继承org.apache.hadoop.hive.ql.exec.UDF,并定义
public Object evaluate(Object args) {} 方法即可。
比如,下面的UDF函数实现了对一个String类型的字符串取HashMD5:
package com.lxw1234.hive.udf;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.util.MD5Hash;
import org.apache.hadoop.hive.ql.exec.UDF;
public class HashMd5 extends UDF {
public String evaluate(String cookie) {
return MD5Hash.getMD5AsHex(Bytes.toBytes(cookie));
}
}将上面的HashMd5类打成jar包,udf.jar
使用时候,在Hive命令行执行:
add jar file:///tmp/udf.jar;
CREATE temporary function str_md5 as 'com.lxw1234.hive.udf.HashMd5';
select str_md5(‘lxw1234.com’) from dual;GenericUDF
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDF之后,需要重写几个重要的方法:
public void configure(MapredContext context) {}
//可选,该方法中可以通过context.getJobConf()获取job执行时候的Configuration;
//可以通过Configuration传递参数值
public ObjectInspector initialize(ObjectInspector[] arguments)
//必选,该方法用于函数初始化操作,并定义函数的返回值类型;
//比如,在该方法中可以初始化对象实例,初始化数据库链接,初始化读取文件等;
public Object evaluate(DeferredObject[] args){}
//必选,函数处理的核心方法,用途和UDF中的evaluate一样;
public String getDisplayString(String[] children)
//必选,显示函数的帮助信息
public void close(){}
//可选,map完成后,执行关闭操作
下面的程序将一个以逗号分隔的字符串,切分成List,并返回:
package com.lxw1234.hive.udf;
import java.util.ArrayList;
import java.util.Date;
import org.apache.hadoop.hive.ql.exec.MapredContext;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* http://lxw1234.com
* lxw的大数据田地
* @author lxw1234
* 该函数用于将字符串切分成List,并返回
*/
public class Lxw1234GenericUDF extends GenericUDF {
private static int mapTasks = 0;
private static String init = "";
private transient ArrayList ret = new ArrayList();
@Override
public void configure(MapredContext context) {
System.out.println(new Date() + "######## configure");
if(null != context) {
//从jobConf中获取map数
mapTasks = context.getJobConf().getNumMapTasks();
}
System.out.println(new Date() + "######## mapTasks [" + mapTasks + "] ..");
}
@Override
public ObjectInspector initialize(ObjectInspector[] arguments)
throws UDFArgumentException {
System.out.println(new Date() + "######## initialize");
//初始化文件系统,可以在这里初始化读取文件等
init = "init";
//定义函数的返回类型为java的List
ObjectInspector returnOI = PrimitiveObjectInspectorFactory
.getPrimitiveJavaObjectInspector(PrimitiveObjectInspector.PrimitiveCategory.STRING);
return ObjectInspectorFactory.getStandardListObjectInspector(returnOI);
}
@Override
public Object evaluate(DeferredObject[] args) throws HiveException {
ret.clear();
if(args.length < 1) return ret;
//获取第一个参数
String str = args[0].get().toString();
String[] s = str.split(",",-1);
for(String word : s) {
ret.add(word);
}
return ret;
}
@Override
public String getDisplayString(String[] children) {
return "Usage: Lxw1234GenericUDF(String str)";
}
}其中,在configure方法中,获取了本次任务的Map Task数目;
在initialize方法中,初始化了一个变量init,并定义了返回类型为java的List类型;
getDisplayString方法中显示函数的用法;
evaluate是核心的逻辑处理;
需要特别注意的是,configure方法,“This is only called in runtime of MapRedTask”,该方法只有在运行map task时候才被执行。它和initialize用法不一样,如果在initialize时候去使用MapredContext,则会报Null,因为此时MapredContext还是Null。
上面的函数执行后,在MapReduce的日志中打印出了以下内容:
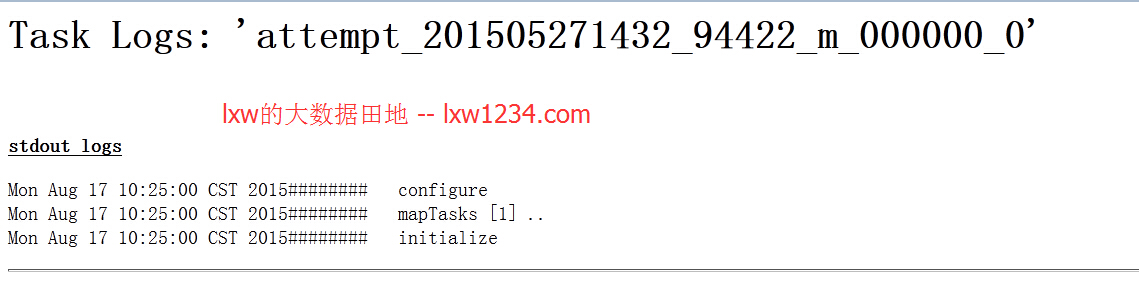
即在MapReduce阶段,GenericUDF几个方法的执行顺序为:
configure–>initialize–>evaluate–>close
Hive相关文章(持续更新):
—-Hive中的数据库(Database)和表(Table)
hive优化之——控制hive任务中的map数和reduce数
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » [一起学Hive]之十八-Hive UDF开发

















 3186
3186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









