




 本文整理自NVIDIA线下交流会,探讨如何使用TensorRT加速深度学习推理计算,涉及TensorRT、TensorRT Inference Server和Deepstream,旨在解决在硬件资源有限条件下提升推理速度的问题。内容包括TensorRT的工作原理、性能优化以及相关工具的使用场景。
本文整理自NVIDIA线下交流会,探讨如何使用TensorRT加速深度学习推理计算,涉及TensorRT、TensorRT Inference Server和Deepstream,旨在解决在硬件资源有限条件下提升推理速度的问题。内容包括TensorRT的工作原理、性能优化以及相关工具的使用场景。
主讲人:Ken(何琨)| NVIDIA开发者社区经理
张康 屈鑫 编辑整理
量子位 出品 | 公众号 QbitAI
12月22日,量子位联合NVIDIA英伟达举行了线下交流会,跟现场近百位开发者同学共同探讨了如何用TensorRT加速深度学习推理计算,详细讲解了GPU的推理引擎TensorRT,以及如何配合Deepstream实现完整加速推理的解决方案。
应读者要求,量子位将交流内容整理成文,与大家分享。
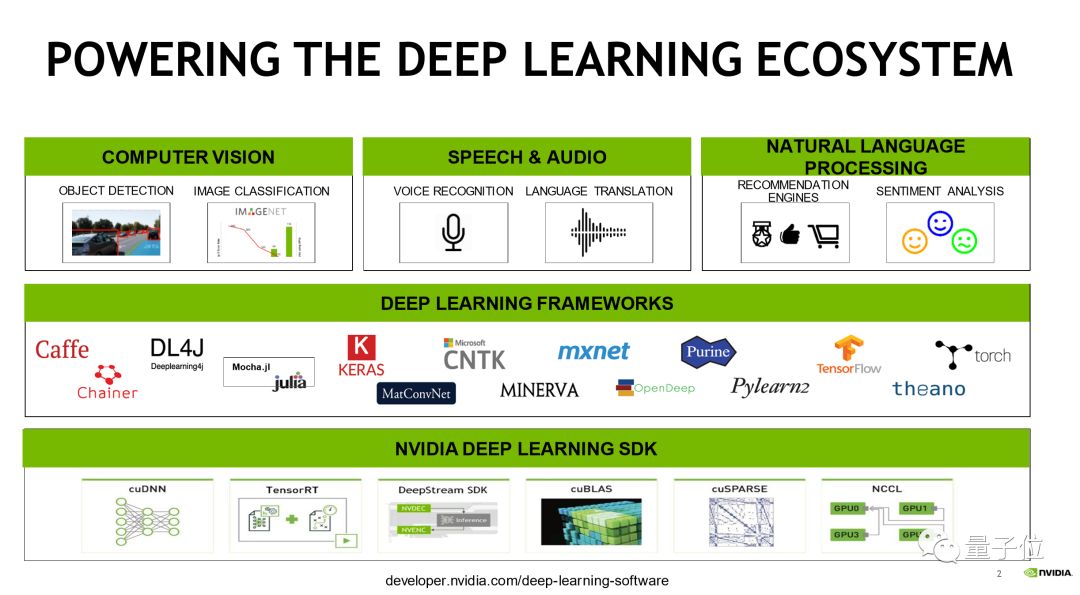
这张图是一个完整的现代深度学习应用,在硬件的应用方面,三个比较大的常用的领域是:视觉相关,包含医疗、自动驾驶、摄像头的处理等等;另外是语音和自然语言处理相关,包含语义理解和语音识别。
为了实现这些功能,会使用各种各样的框架,包括Caffe、TensorFlow、PyTorch等等。
框架不同,每个人的使用习惯也不同,但最终都是完成一件事情:深度学习模型的训练,以及深度模型的推理。这样一个工具。完成这两个任务最核心的内容还是计算。
今天主要核心介绍的就是TensorRT以及相关的DeepStream SDK,他们如何来加速深度学习推理计算。
TensorRT
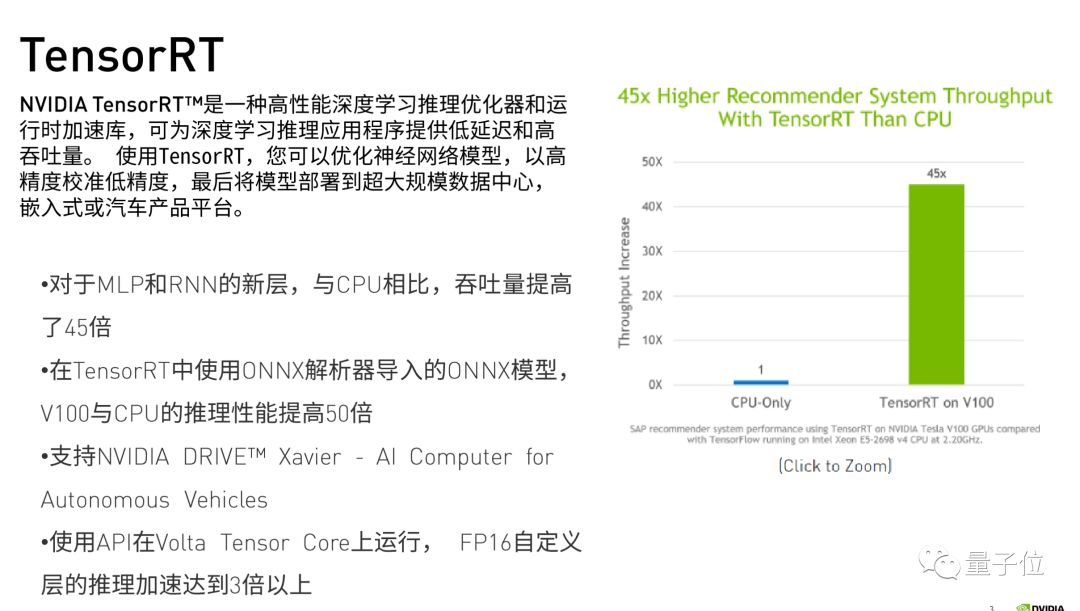
先介绍一下什么是TensorRT。
Tensor,深度学习中的张量。一个一维Tensor的叫Vector,二维的叫Matrix,三维四维的Tensor都有。 Tensor RT的Tensor指的就是这个概念,而整个TensorRT的工具是指一个GPU Inference Engine,也就是一个GPU推理引擎。
GPU推理引擎是干什么的呢?我们在做推理的时候,比如拿Caffe框架训练出来一个模型,那么推理的时候就直接拿Caffe框架Test。
但是上述场景只适用于做研究或者做课题,部署到产品端会更复杂。举个例子,比如部署到自动驾驶汽车上,框架都很常见,但这么大的框架塞到一个嵌入式的移动设备中非常不合适,里边的空间、计算的内存、CPU的一些计算资源,不可能还有其余的空间给这些框架。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









