




公众号
关注公众号:推荐算法工程师,输入"进群",加入交流群,和小伙伴们一起讨论机器学习,深度学习,推荐算法.

前言
早期做特征工程的时候,采用人工或决策树等来选择特征,然而这些方法无法学习到训练集中没有出现的特征组合.而近几年出现的基于embedding的方法,可以学习到训练集中没有出现的组合,作者将embedding方法归为两类,一类是FM这种线性模型,之前介绍过的FNN就是利用FM作为初始化的embedding;另一类是基于神经网络的非线性模型,NFM(Neural Factorization Machine)则是将两种embedding结合起来.NFM是发表在SIGIR 2017上的文章,出现在深度学习与推荐系统结合的初期,模型相对较为简单,可以拿来练习tensorflow.
论文地址:https://arxiv.org/pdf/1708.05027.pdf
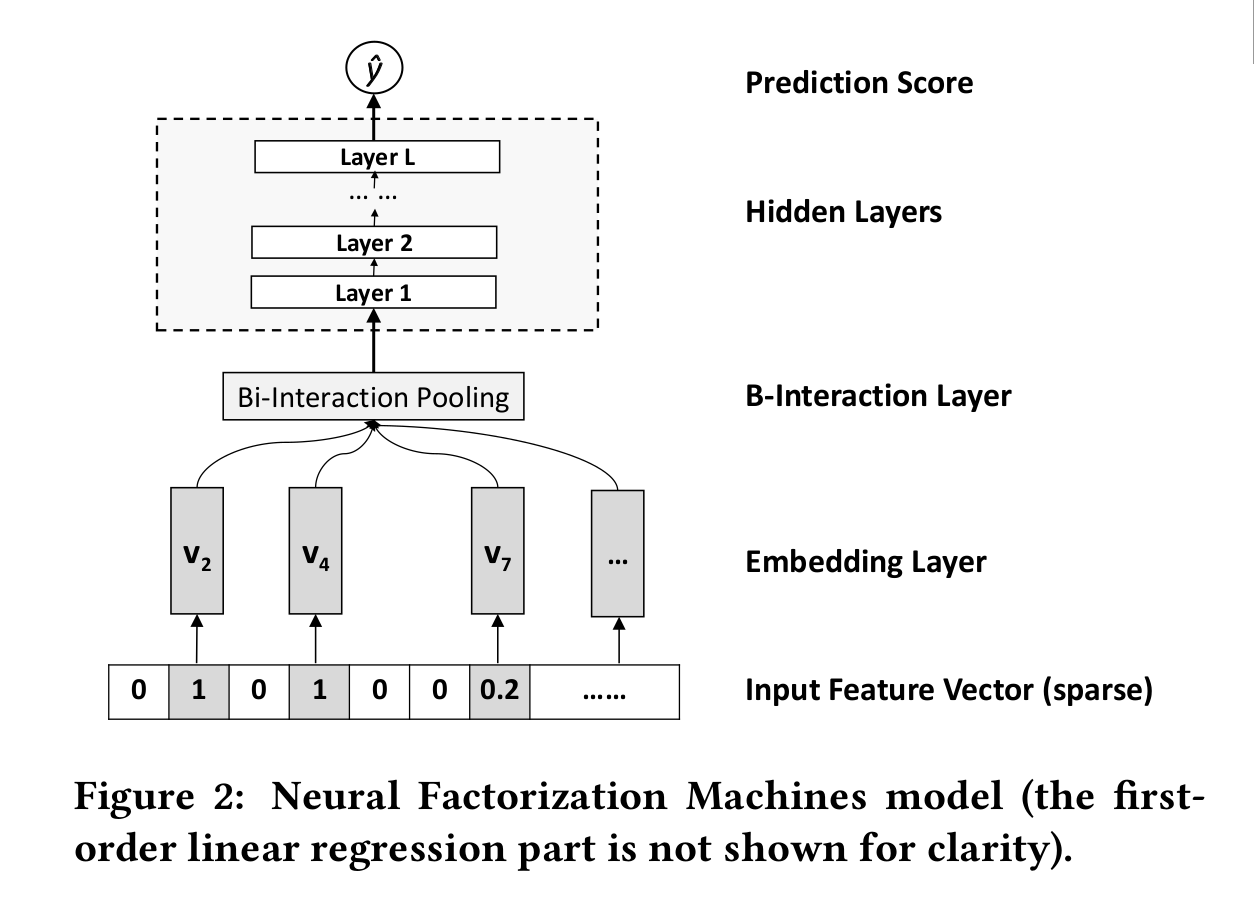
NFM模型
首先来回顾下FM模型:
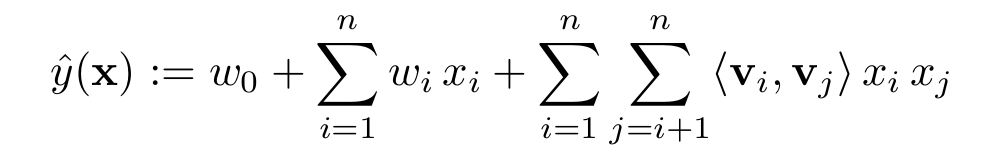
设embedding向量维度为k,其中的二阶交叉项可以进行优化:
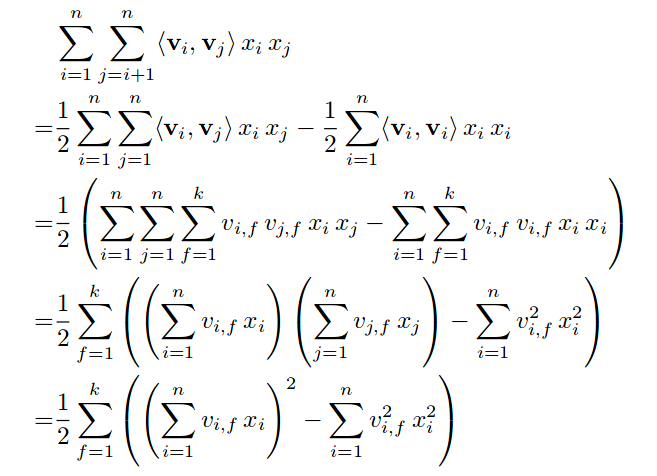
交叉项得到的是一个值,如果去掉最外面那层求和,得到一个k维的向量.这个k维的向量就是所谓的"Bi-Interaction Layer"的结果:
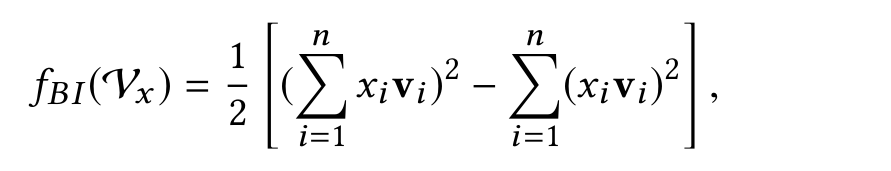
将这个向量输入全连接层,得到预测结果f(x),而最终的预估公式就是:
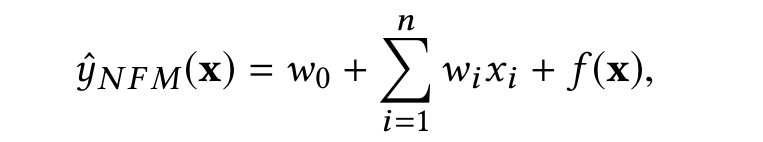
此时再看模型一目了然:
代码实战
这部分代码改自之前AFM的代码,有兴趣可以自己改改试一试,挺简单的.其中interaction layer的实现提供了优化前和优化后两种写法,可以运行下比较比较时间,差距蛮大.简单看看几个关键点的实现,首先是embedding layer:
with tf.name_scope('Embedding_Layer'):
self.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'], self.feature_index) # [None, field_size, embedding_size]
feat_value = tf 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









