



Mysql
简介:
MySQL 是一个流行的开源关系型数据库管理系统,由瑞典 MySQL AB 公司开发,后被 Sun 公司收购,Sun 公司又被 Oracle 公司收购。MySQL 被广泛应用于 Web 应用程序开发中,是许多网站和应用的数据库存储引擎之一。
以下是 MySQL 的一些主要特点和功能:
-
开源性:MySQL 是开源软件,采用 GPL 许可证,可以免费使用和修改,这使得它成为许多开发者和组织的首选数据库管理系统。
-
跨平台性:MySQL 可以在各种操作系统上运行,包括 Windows、Linux、Mac 等,这为开发者提供了灵活的选择。
-
性能优化:MySQL 具有高性能的特点,能够处理大规模的数据,提供快速的查询和响应速度。
-
标准化:MySQL 遵循 SQL 标准,并支持 ACID(原子性、一致性、隔离性、持久性)属性,保证数据的完整性和一致性。
-
丰富的功能:MySQL 提供了丰富的数据类型支持(包括数值、日期时间、字符串等),以及索引、触发器、存储过程等数据库特性。
-
可扩展性:MySQL 支持主从复制、分片、集群等方式进行数据库的扩展和负载均衡,适应了不同规模和需求的应用场景。
-
社区支持:MySQL 拥有庞大的用户社区和开发者社区,提供了丰富的文档、教程和支持资源。
MySQL 在 Web 开发领域有着广泛的应用,尤其是在 LAMP(Linux + Apache + MySQL + PHP/Python/Perl)架构中扮演着重要的角色。通过结合强大的功能和开源的特性,MySQL 成为了许多开发者和组织构建可靠、高性能 Web 应用的首选数据库管理系统。
Mysql索引失效的情况
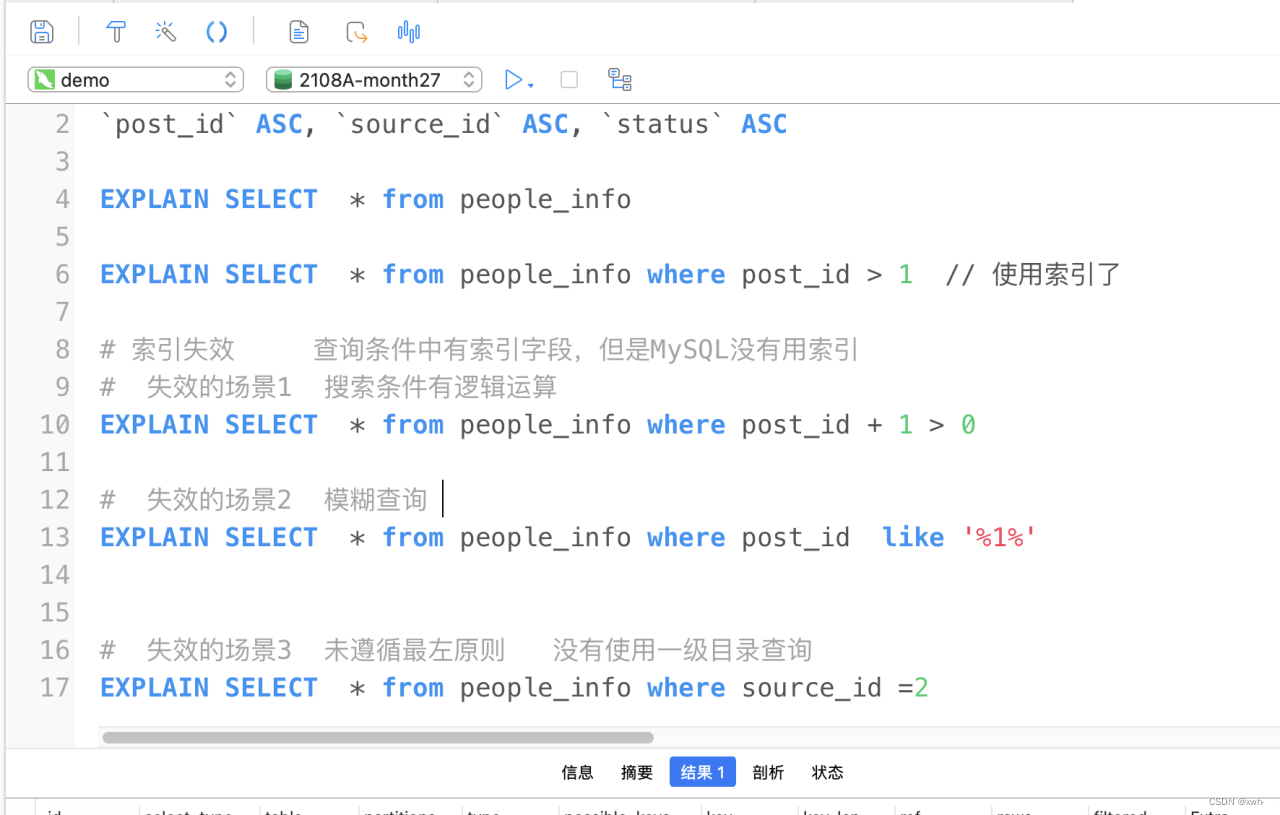
首先创建一个组合索引,

注意:
展示效果的时候,需要演示索引生效和索引失效的场景
生效:

失效

失效的场景一、
搜索条件有逻辑运算
EXPLAIN SELECT * from emp where id/10>0
EXPLAIN SELECT c.* FROM car c where c.type_id is not null
失效的场景二、
模糊查询
EXPLAIN SELECT * from emp where name like '%余%';
失效的场景三、
未遵循最左原则 (没有使用一级目录查询)
EXPLAIN SELECT * from emp where job_id=10
关于EXPLAIN
在MySQL中,EXPLAIN命令用于分析查询语句的执行计划,提供了有关查询的详细信息,包括访问类型、使用的索引、表之间的连接方式等。通过使用EXPLAIN,可以帮助开发人员优化查询性能。
要使用EXPLAIN命令,只需在查询语句前加上EXPLAIN关键字,例如:
EXPLAIN SELECT * FROM table_name WHERE condition;
执行该命令后,MySQL将返回一个解释查询执行计划的结果集,通常以表格形式显示。下面是一些可能包含的字段:
- id: 查询中操作的标识符。如果查询是复杂的,可能会有多个操作。
- select_type: 查询的类型,常见的类型包括SIMPLE(简单查询)、PRIMARY(主查询)、SUBQUERY(子查询)等。
- table: 操作的表名。
- partitions: 分区信息。
- type: 表示访问类型,描述了MySQL如何获取数据,常见的类型有ALL(全表扫描)、INDEX(使用索引扫描)、REF(使用非唯一索引扫描)等。
- possible_keys: 可能使用的索引列表。
- key: 实际使用的索引。
- key_len: 使用的索引长度。
- ref: 使用的索引参考值。
- rows: 估计的所需读取行数。
- filtered: 过滤的行占比。
- Extra: 额外的执行信息,如Using index(使用索引)等。
通过分析EXPLAIN的输出,可以确定查询执行过程中是否存在潜在的性能问题,并根据需要进行索引优化、重写查询语句或调整数据库结构,以提高查询效率。
Tomcat
简介
Apache Tomcat(简称 Tomcat)是一个开源的、轻量级的 Web 应用服务器,用于运行 Java Servlet 和 JavaServer Pages(JSP)等动态 Web 内容。Tomcat 由 Apache 软件基金会开发和维护,是一个流行的 Java Web 应用服务器。
以下是关于 Tomcat 的一些主要信息:
-
Servlet 和 JSP 支持:Tomcat 提供了对 Servlet 和 JSP 技术的完整支持,可以部署和运行基于这些技术的 Web 应用程序。
-
开源性:Tomcat 是开源软件,采用 Apache 许可证,可以免费使用和修改,这使得它成为了许多开发者和组织的首选 Web 应用服务器。
-
跨平台性:Tomcat 可以在各种操作系统上运行,包括 Windows、Linux、Mac 等,这为开发者提供了灵活的选择。
-
易用性:Tomcat 设计简单,易于安装和配置,同时提供了丰富的管理和监控工具,方便开发者进行应用程序的部署和管理。
-
扩展性:Tomcat 支持通过插件和扩展实现功能增强和定制化,开发者可以根据需要扩展和定制 Tomcat 的功能。
-
社区支持:Tomcat 拥有庞大的用户社区和开发者社区,提供了丰富的文档、教程和支持资源。
-
适用范围:Tomcat 适用于中小型的 Web 应用程序,对于大型、高负载的应用,也可以通过集群和负载均衡的方式进行扩展。
总的来说,Tomcat 是一个受欢迎的、稳定的 Web 应用服务器,适用于开发和部署 Java Web 应用程序。它的轻量级特点和丰富的功能使得它成为了许多开发者和组织构建 Java Web 应用的首选服务器之一。
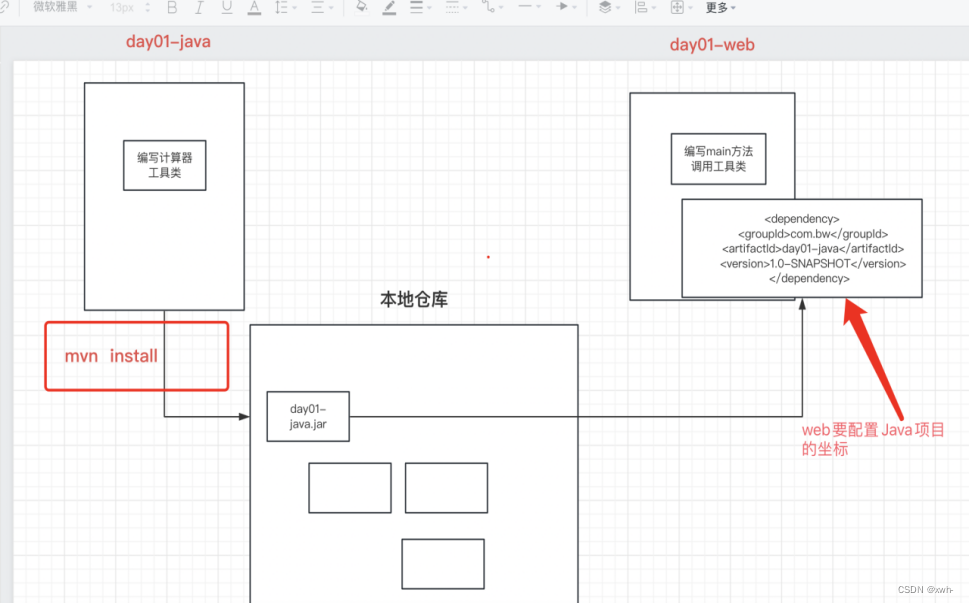
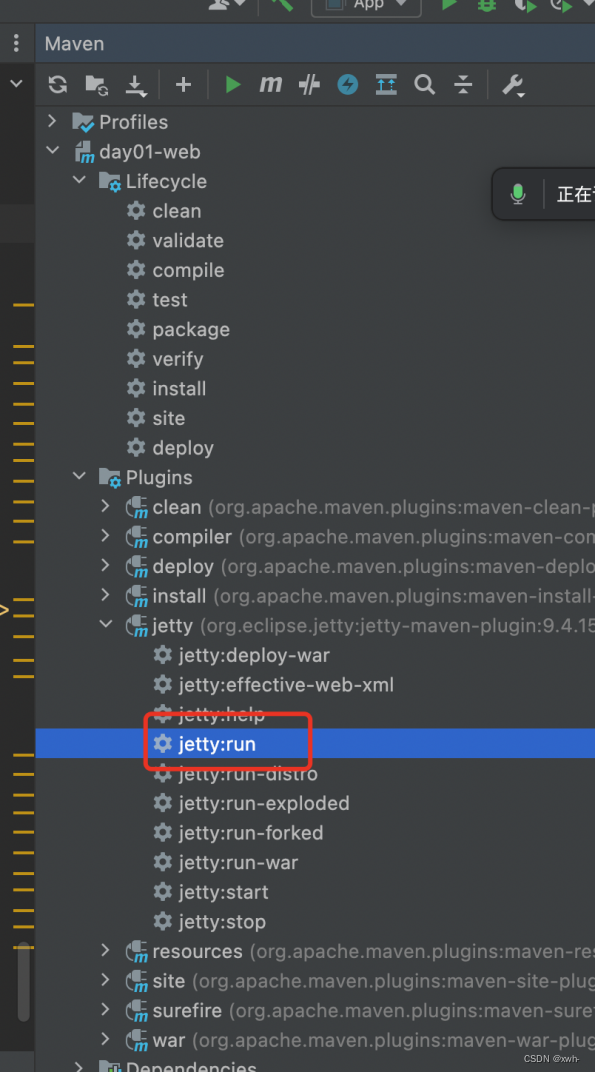
如何在本地tomcat运行项目
前提:保证idea里没有启动任何web项目(防止端口号被占用)
1.idea打包web项目, mvn package
2. 在项目生成的target目录下找到war包
3. 找到tomcat安装目录, webapps文件夹下删除命名为ROOT的文件夹和war包(如果没有忽略)
4. 把打包之后的war包复制到webapps文件夹下,并重命名为ROOT.war
5. Tomcat 安装目录里的bin文件夹, 找到startup.bat, 双击运行, cmd显示启动成功
6. 打开浏览器访问http://localhost:8080、
7.流程图
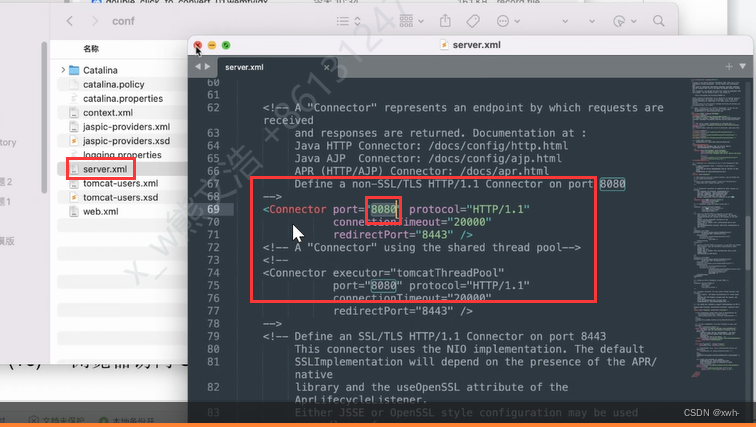
如何修改Tomcat的端口号
sql语法与函数
一。函数
聚合函数是数据库中用于对数据集进行汇总计算的函数。常见的聚合函数包括:
- COUNT:计算数据行的数量 (统计)。
- SUM:计算数值列的总和。(求和)
- AVG:计算数值列的平均值。(平均数)
- MIN:找出数值列的最小值。(最小值)
- MAX:找出数值列的最大值。(最大值)
- GROUP_CONCAT:将字符串列的值连接起来,形成一个字符串列表。
- DISTINCT:返回指定列中唯一值的数量。
在使用聚合函数时,通常需要结合其他关键字和子句一起使用,例如:
- SELECT:用于选择要查询的列。
- FROM:用于指定查询的数据表或视图。
- WHERE:用于过滤符合条件的数据行。
- GROUP BY:用于按照某一列或多列对数据进行分组。(分组)
- HAVING:用于筛选分组后的结果。(分组后过滤)
- ORDER BY:用于对结果进行排序。(排序)
- LIMIT:用于限制返回的结果数量。(分页)
二。具体语法和函数
1.去除查询到的重复内容
DISTINCT

需要注意的是,DISTINCT 作用于所有指定的列,而不仅仅是单独的某一列。这意味着返回的每一行都是唯一的组合,而不仅是各个列的值唯一。
总之,DISTINCT 是 SQL 中用于消除重复行的重要关键字,可以帮助我们筛选出唯一的结果。
2.将时间戳转为指定年月日时分秒格式
一。 FROM_UNIXTIME(ts/1000,'%Y-%m-%d %H')

注意
如果是精确到毫秒的时间戳需要先/1000
在 SQL 中,FROM_UNIXTIME 函数用于将 UNIX 时间戳转换为日期时间格式。UNIX 时间戳是指从 1970 年 1 月 1 日 00:00:00 UTC(协调世界时)起至特定时间的秒数。FROM_UNIXTIME 函数可以帮助我们将这些秒数转换为易读的日期时间格式。
语法如下:
FROM_UNIXTIME(unix_timestamp, [format])
unix_timestamp是一个表示 UNIX 时间戳的整数值。format是一个可选参数,用于指定输出日期时间的格式,默认情况下会以 'YYYY-MM-DD HH:MM:SS' 的格式返回日期时间。
总之,FROM_UNIXTIME 函数是 SQL 中用于将 UNIX 时间戳转换为日期时间格式的重要函数,它可以让我们方便地处理 UNIX 时间戳并将其转换成易读的日期时间。
2.1。日期时间格式化
DATE_FORMAT()
DATE_FORMAT(a,'%Y-%m-%d %H')时间格式化

DATE_FORMAT(date, format)
date:表示要格式化的日期。format:表示日期的显示格式,可以是各种组合的年、月、日、时、分、秒等。
3.计算两个日期之间的差距
DATEDIFF(unit, start_date, end_date)
DATEDIFF(a,b)两个时间之间相差的天数

unit:表示要计算的时间间隔单位,可以是以下选项之一:day(天)week(周)month(月)year(年)- 等等
start_date:表示时间间隔的起始日期。end_date:表示时间间隔的结束日期。
计算两个日期或时间之间的差异
TIMESTAMPDIFF
TIMESTAMPDIFF函数用于在SQL中计算两个日期或时间之间的差异。它返回两个日期或时间之间的差异,并且可以指定要返回的时间单位,例如秒、分钟、小时、天等。

具体用法
TIMESTAMPDIFF(unit, start_timestamp, end_timestamp)
unit:表示要计算的时间单位,可以是以下选项之一:SECONDMINUTEHOURDAYMONTHYEAR
start_timestamp:表示时间间隔的起始日期或时间戳。end_timestamp:表示时间间隔的结束日期或时间戳。
4.IF条件判断
IF(a,b,c)第一个参数a为判断的条件,第二个参数B为条件成立的结果,第三个参数c为条件不成立的结果

IF(condition, value_if_true, value_if_false)
condition:表示一个条件表达式,可以是任何能够返回布尔值(真或假)的表达式。value_if_true:表示如果条件为真,将返回的值。value_if_false:表示如果条件为假,将返回的值。
5.合并SELECT结果集
UNION ALL
SQL语法中的UNION ALL用于合并两个或多个SELECT语句的结果集,包括重复行

6.包含不包含
NOT EXISTS(不包含),EXISTS(包含)

是 SQL 中的一个条件运算符,用于检查是否存在满足特定条件的行。它通常与子查询一起使用。
如果子查询中不存在满足特定条件的行,则 NOT EXISTS 返回 True,否则返回 False。
NOT EXISTS 的使用场景通常是在 WHERE 子句中,用来排除那些满足特定条件的行
7.sql中分组拼接从表字段(多对多)
sql语法:GROUP_CONCAT(字段名) 联查分组之后,在select from 中间 加上

8.分组后过滤筛选
HAVING
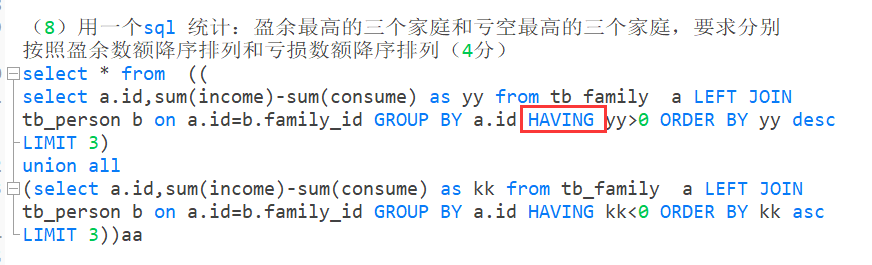
HAVING 是 SQL 中用于在 GROUP BY 子句之后对分组结果进行筛选的关键字。它通常用于对分组后的结果集进行聚合条件的过滤。只有满足该条件的分组才会出现在最终的结果集中。
与 WHERE 子句不同,HAVING 子句是用于筛选分组后的结果,可以使用聚合函数和分组列来定义条件。
9.在日期和时间值上执行加减操作
INTERVAL:
在 SQL 中,INTERVAL 是用于处理日期和时间的关键字。它通常与日期和时间函数一起使用,用于在日期和时间值上执行加减操作,以及进行日期和时间单位的转换。
在使用 INTERVAL 时,通常会结合关键字如 YEAR、MONTH、DAY、HOUR、MINUTE、SECOND 等来指定具体的时间单位
10.开窗函数

10.1 ROW_NUMBER()
ROW_NUMBER()是一种窗口函数,用于为结果集中的每一行分配一个唯一的数字序号。它常用于分页、排序和排名等场景。
语法如下: ROW_NUMBER() OVER (ORDER BY column1, column2, ...)
其中,ORDER BY子句指定了用于排序的列。如果不指定ORDER BY子句,则ROW_NUMBER()按照结果集的任意顺序生成序号。
10.2 over()
OVER()是SQL中用于指定窗口函数操作的子句。它定义了窗口函数所应用的数据窗口,这可以是整个结果集,也可以是结果集中的一个子集。通过OVER()子句,我们可以对窗口中的数据进行排序、分组和筛选,以便窗口函数能够在指定的数据范围内进行操作。
通常,OVER()子句后会跟随ORDER BY、PARTITION BY、ROWS/RANGE等子句,用于指定窗口函数的行为。
10.3 PARTITION BY
PARTITION BY是SQL中用于对数据进行分区的子句,通常与窗口函数一起使用。通过PARTITION BY子句,可以将数据集按照指定的列进行分组,使得窗口函数能够在每个分区内独立地进行计算。
当使用PARTITION BY子句时,窗口函数将在每个分区内独立计算,并生成相应的结果。这对于需要对数据进行分组计算的情况非常有用。

















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









