



 本文深入探讨了Hive数据仓库的原理与应用,包括Hive的背景、架构、与RDBMS的对比、部署步骤、表操作及数据管理。详细介绍了如何在Hadoop生态中利用Hive进行大数据统计分析。
本文深入探讨了Hive数据仓库的原理与应用,包括Hive的背景、架构、与RDBMS的对比、部署步骤、表操作及数据管理。详细介绍了如何在Hadoop生态中利用Hive进行大数据统计分析。
一、Hadoop
狭义
Hadoop是最重要最基础的一个部分
广义
Hadoop生态圈
Hadoop、Hive、Sqoop、HBase…
处理如下业务:join/group by
二、hive产生的背景
基于Hadoop处理大数据存在的弊端:
面向MapReduce麻烦
RDBMS的需求
==> Hive的产生背景
MySQL/Oracle… 统计
先创建表:表名、列名、列类型… schema(元数据/metadata)
然后再使用SQL进行相应的业务统计分析
HDFS上的文件:文本格式
按照某个分隔符(\t):第一列是什么、第二列是什么
元数据 vs 源数据
源数据:HDFS上的文件
元数据:是描述数据的数据
三、Hive概述
hive.apache.org
The Apache Hive ™ data warehouse software facilitates
reading,
writing,
managing large datasets residing
in distributed storage (HDFS/S3)
using SQL
A command line tool
and JDBC driver are provided to connect users to Hive
Facebook开源,用于解决海量结构化的日志数据统计问题
构建在Hadoop(HDFS/MapReduce/YARN)之上的数据仓库
Hive的数据是存放在HDFS之上
Hive底层执行引擎:MapReduce/Tez/Spark
只需要通过一个参数就能够切换底层的执行引擎
Hive作业提交到YARN上运行
提供了HQL查询语言
和SQL类似,但不完全相同
所谓的大数据“云化”:是一个很大项目
适用于离线处理/批处理
HDFS上的数据:文本 压缩、列式存储
SQL on Hadoop:Hive/Presto/Impala/Spark SQL…
四、Hive的优缺点
优点:SQL
缺点:
如果底层引擎是基于MR,性能必然不高
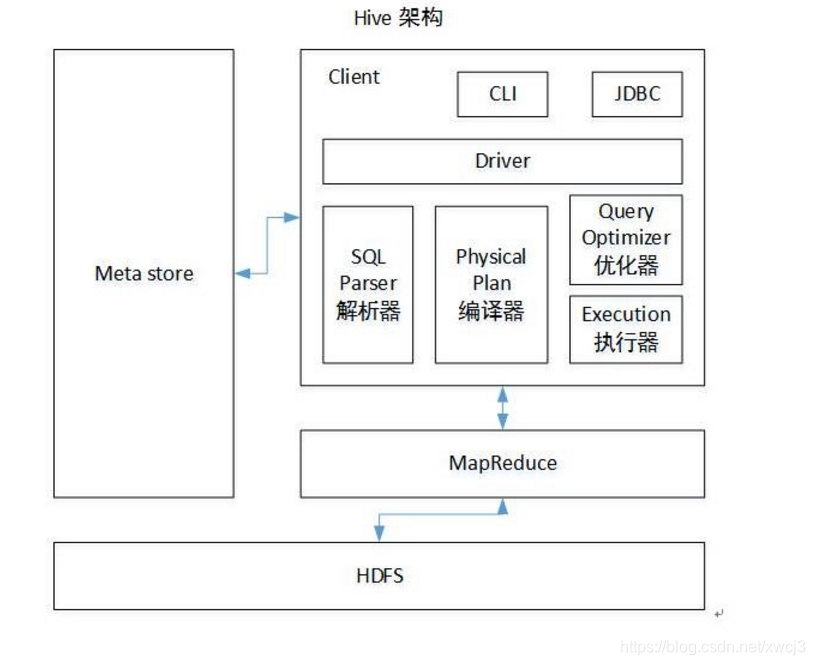
五、Hive架构
用户接口层:黑窗口、JDBC
Driver/驱动器
SQL解析:SQL ==> AST(antlr)
查询优化:逻辑/物理执行计划
UDF/SerDes:
Execution:执行
元数据:表名、所属数据库、列(名/类型/index)、表类型、表数据所在目录
id,username,password,age
Hive的数据是存放在HDFS之上
Hive的数据分为两部分:数据 + 元数据
六、Hive和RDBMS的对比
相同点
SQL
事务
insert/update/delete Hive-0.14才支持
针对Hive数据仓库,写比较少的,批次加载数据到Hive然后进行统计分析
不同点
体量/集群规模
延迟/时性
七、部署
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
前期工作
前置
JDK8
Hadoop2.x
Linux
MySQL
CDH-5.16.2
wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.16.2.tar.gz
安装
解压
[pxj@pxj31 /opt]$tar -zxvf hive-1.1.0-cdh5.16.2.tar.gz -C /home/pxj/app/
#### 配置环境
[pxj@pxj31 /home/pxj]$vim .bashrc
export HIVE_HOME=/home/pxj/app/hive-1.1.0-cdh5.16.2
export PATH=${HIVE_HOME}/bin:$PATH
[pxj@pxj31 /home/pxj]$source .bashrc
[pxj@pxj31 /home/pxj]$which hive
~/app/hive-1.1.0-cdh5.16.2/bin/hive
修改配置文件
[pxj@pxj31 /home/pxj/app/hive-1.1.0-cdh5.16.2/conf]$vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://pxj31:3306/pxj31_hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>lenovo</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
</configuration>
[pxj@pxj31 /home/pxj/app/hive-1.1.0-cdh5.16.2/conf]$cp hive-env.sh.template hive-env.sh
[pxj@pxj31 /home/pxj/app/hive-1.1.0-cdh5.16.2/conf]$vim hive-env.sh
HADOOP_HOME=/home/pxj/app/hadoop
拷贝驱动
[pxj@pxj31 /opt]$sudo mv mysql-connector-java-5.1.27-bin.jar ~/app/hive-1.1.0-cdh5.16.2/lib/
启动
[pxj@pxj31 /home/pxj/app/hive-1.1.0-cdh5.16.2/lib]$hive
which: no hbase in (/home/pxj/app/hive-1.1.0-cdh5.16.2/bin:/home/pxj/app/hadoop/bin:/home/pxj/app/hadoop/sbin:/usr/java/jdk1.8.0_121/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/pxj/.local/bin:/home/pxj/bin)
19/12/15 01:04:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Logging initialized using configuration in jar:file:/home/pxj/app/hive-1.1.0-cdh5.16.2/lib/hive-common-1.1.0-cdh5.16.2.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive (default)> show databases;
OK
database_name
default
Time taken: 31.063 seconds, Fetched: 1 row(s)
八、创建表
hive (default)> create table stu(id int, name string, age int);
OK
Time taken: 4.357 seconds
hive (default)>
查看表结构的四种方法
hive (default)> desc stu;
OK
col_name data_type comment
id int
name string
age int
Time taken: 0.869 seconds, Fetched: 3 row(s)
hive (default)> desc extended stu;
OK
col_name data_type comment
id int
name string
age int
Detailed Table Information Table(tableName:stu, dbName:default, owner:pxj, createTime:1576343220, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null), FieldSchema(name:age, type:int, comment:null)], location:hdfs://pxj31:9000/user/hive/warehouse/stu, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format=1}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{transient_lastDdlTime=1576343220}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, ownerType:USER)
Time taken: 0.081 seconds, Fetched: 5 row(s)
hive (default)> desc formatted stu;
OK
col_name data_type comment
col_name data_type comment
id int
name string
age int
Detailed Table Information
Database: default
OwnerType: USER
Owner: pxj
CreateTime: Sun Dec 15 01:07:00 CST 2019
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://pxj31:9000/user/hive/warehouse/stu
Table Type: MANAGED_TABLE
Table Parameters:
transient_lastDdlTime 1576343220
Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 0.388 seconds, Fetched: 29 row(s)
hive (default)> show create table stu;
OK
createtab_stmt
CREATE TABLE `stu`(
`id` int,
`name` string,
`age` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://pxj31:9000/user/hive/warehouse/stu'
TBLPROPERTIES (
'transient_lastDdlTime'='1576343220')
Time taken: 0.986 seconds, Fetched: 14 row(s)
插入数据
insert into stu values(1,'pk',30);
查询数据
hive (default)> select * from stu;
OK
stu.id stu.name stu.age
1 pk 30
Time taken: 0.336 seconds, Fetched: 1 row(s)
所在的目录
hdfs://pxj31:9000/user/hive/warehouse/stu
hive.metastore.warehouse.dir:/user/hive/warehouse
stu:表的名字
表的完整路径是: ${hive.metastore.warehouse.dir}/tablename
九、Hive的完整执行日志:
cd
H
I
V
E
H
O
M
E
c
p
h
i
v
e
−
l
o
g
4
j
.
p
r
o
p
e
r
t
i
e
s
.
t
e
m
p
l
a
t
e
h
i
v
e
−
l
o
g
4
j
.
p
r
o
p
e
r
t
i
e
s
h
i
v
e
.
l
o
g
.
d
i
r
=
HIVE_HOME cp hive-log4j.properties.template hive-log4j.properties hive.log.dir=
HIVEHOMEcphive−log4j.properties.templatehive−log4j.propertieshive.log.dir={java.io.tmpdir}/${user.name}
hive.log.file=hive.log
j
a
v
a
.
i
o
.
t
m
p
d
i
r
/
{java.io.tmpdir}/
java.io.tmpdir/{user.name}/${hive.log.file}
/tmp/hadoop/hive.log
十、Hive配置属性
全局:$HIVE_HOME/hive-site.xml中
临时/当前session:仅对当前session生效
查看当前的属性:set key;
修改当前的属性:set key=value;
hive -hiveconf hive.cli.print.current.db=true
十一、Hive中交互式命令
-e:不需要进入hive命令后,就可以跟上sql语句查询
-f:执行指定文件(内容是SQL语句)
拓展:基于Hive的离线统计/数据仓库
把SQL封装到shell脚本中去,使用hive -e “query sql…”
定时调度:crontab
十二、Hive中的数据抽象
Hive中的表(stu)必须要归属于某个数据库(default)
Database
包含了0到N张表
每个db对应HDFS上的一个文件夹
default==>/user/hive/warehouse
十三、创建数据库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, …)];
CREATE DATABASE IF NOT EXISTS ruozedata_hive;
自己创建的Hive数据库的存放目录规则:
${hive.metastore.warehouse.dir}/dbname.db
/user/hive/warehouse/pxj_hive.db
CREATE DATABASE IF NOT EXISTS pxj_data LOCATION '/pxj/directory' ;
hive (default)> dfs -ls /pxj
> ;
Found 1 items
drwxr-xr-x - pxj supergroup 0 2019-12-15 01:19 /pxj/directory
hive (default)>
hive (default)> CREATE DATABASE IF NOT EXISTS pxj_data LOCATION '/pxj/directory'
> ;
OK
Time taken: 0.144 seconds
hive (default)> dfs -ls /pxj
> ;
Found 1 items
drwxr-xr-x - pxj supergroup 0 2019-12-15 01:19 /pxj/directory
hive (default)> CREATE DATABASE IF NOT EXISTS pxj_hive3 COMMENT 'this is pxj database' WITH DBPROPERTIES('creator'='pk', 'date'='9012-12-30');;
OK
Time taken: 0.069 seconds
十四、删除数据库
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
hive (default)> drop database pxj_data;
OK
Time taken: 0.911 seconds
hive (default)> drop database pxj_hive3;
OK
Time taken: 0.212 seconds
慎用:强制性删除数据库需要使用cascade关键字;
CASCADE(了解即可,慎用): one2many == 1 db 对 多 table
十五、基本数据类型
HDFS上的文件来说:string
数值类型:int bigint float double decimal
字符串类型:string 90%
布尔类型:boolean: true/false
日期类型:date timestamp …
分隔符
delimiter code
^A \001 字段之间的分隔符
\n \n 记录分隔符
^B \002 ARRAY/STRUCT (Hive中的复杂数据类型)
^C \003 key/value of MAP (Hive中的复杂数据类型)
1,pk,30
1$$$
p
k
pk
pk$$$30
create table stu2(id int, name string, age int) row format delimited fields terminated by ‘,’;
insert into stu2 values(1,‘pk’,30);
把/user/hive/warehouse/stu/000000_0下载到本地,查看数据的内容。

















 869
869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









