







 本文详细介绍了如何安装和配置IK分词器以支持中文和英文分词,包括基本使用、自定义专有名词、同义词设置及英文驼峰分词的实现。通过实例展示了如何在Elasticsearch中创建索引和查询时应用这些配置,以达到理想的搜索效果。
本文详细介绍了如何安装和配置IK分词器以支持中文和英文分词,包括基本使用、自定义专有名词、同义词设置及英文驼峰分词的实现。通过实例展示了如何在Elasticsearch中创建索引和查询时应用这些配置,以达到理想的搜索效果。
ES 的默认分词器(standard)不支持中文分词,满足不了平时的需求,所以需要用能够支持中文分词的 IK 分词器。而且 IK 分词器也是支持英文分词的。
本文介绍下IK分词器的安装、基本使用方法;专有名词、同义词的使用;英文驼峰分词的实现。
下载与安装
中文IK分词器下载地址:Releases · medcl/elasticsearch-analysis-ik · GitHub
- 选择一个版本下载,然后解压。
- 在 elasticsearch 的 plugins 目录中新建文件夹 "ik"
- 将解压出来的所有东西都放到"ik"目录
- 修改 "plugin-descriptor.properties" 中的 "elasticsearch.version" 为你使用的 elasticsearch 版本(版本不一致的话启动会失败)
- 重启 elasticsearch
- 如果已经建了索引的话,索引也需要重建
重启后,IK分词器就生效了。
基本使用
IK分词器有两种分词模式:"ik_max_word" 和 "ik_smart"
- ik_max_word:会做最细粒度的拆分,把能拆分的词都拆出来
- ik_smart:会做最粗粒度的拆分,贪心算法,尽可能把词分得长
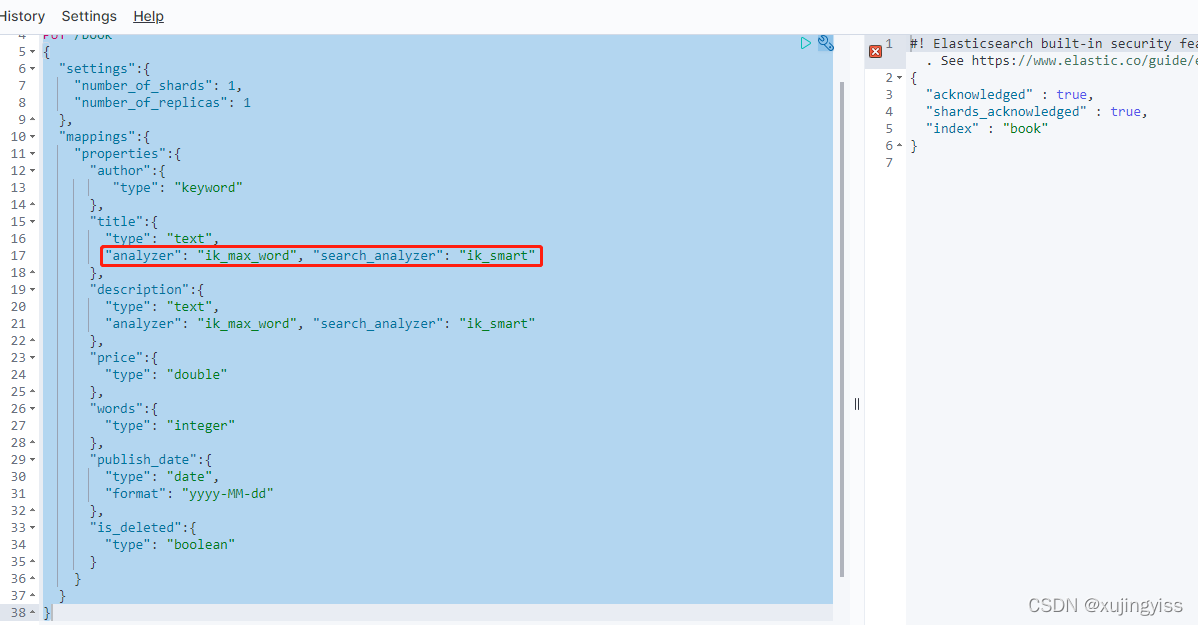
所以,建索引的时候建议用 ik_max_word,查询的时候用 ik_smart
"name":{
"type": "text",
"analyzer": "ik_max_word", "search_analyzer": "ik_smart"
},
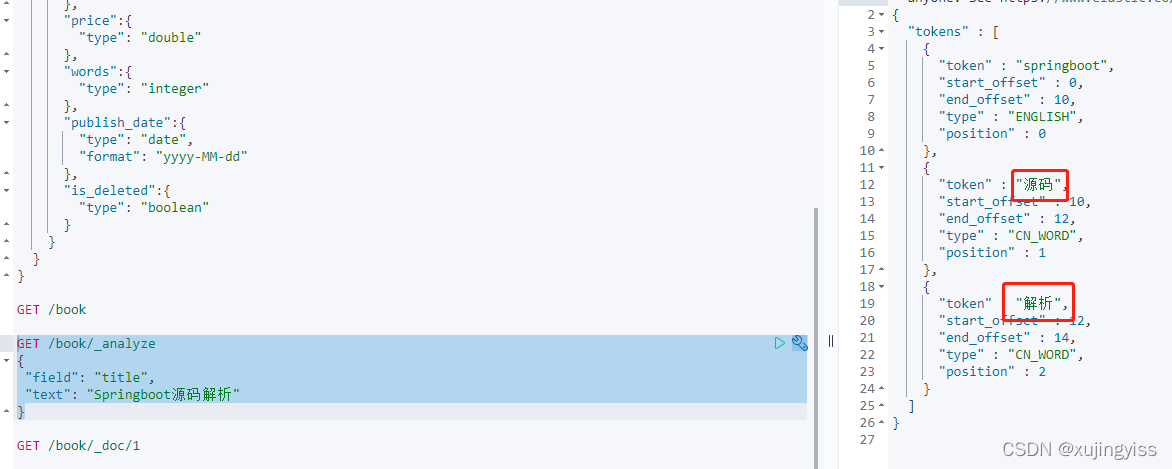
通过 "_analyze" 查看分词结果:
专有名词
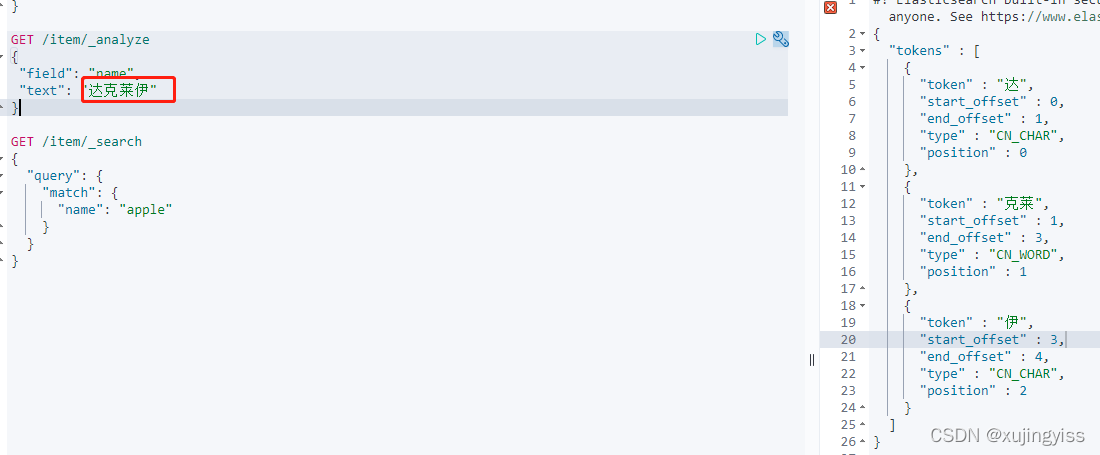
实际使用 IK 分词器时,有些专有名词也分不了,这时就需要自定义词典了。
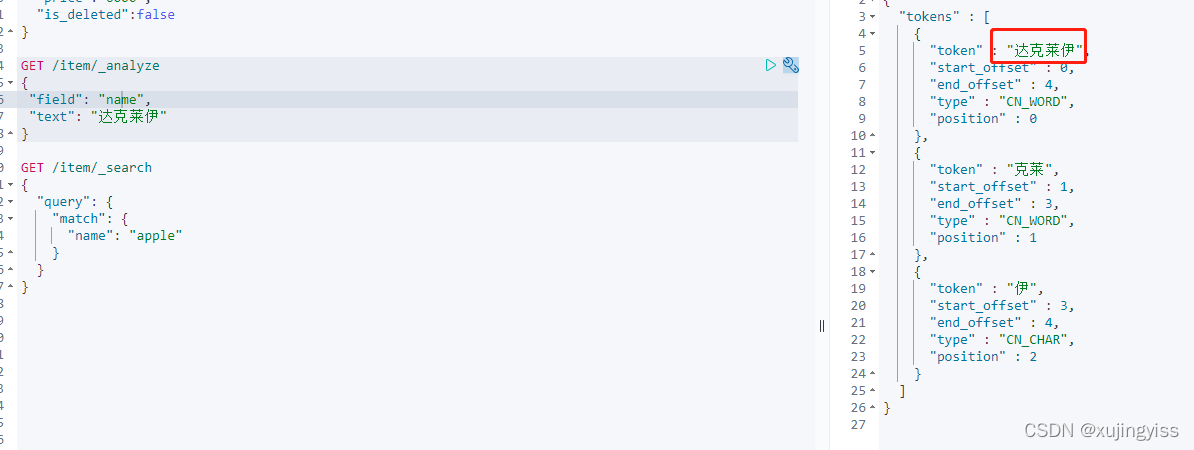
比如宝可梦中有个叫"达克莱伊",这种专属词汇,IK分词器默认就分不了:
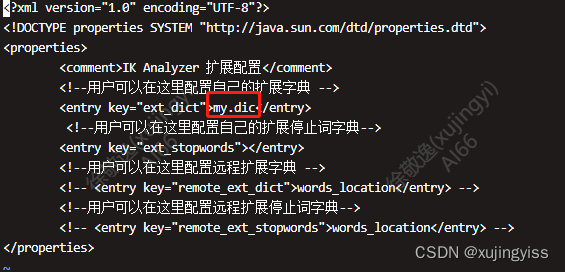
在 plugins/ik/config 目录中新增 "my.dic" 文件(名称自己定义),在 "my.dic" 中加入我们需要使用的专属词汇:

然后修改 "IKAnalyzer.cfg.xml" 文件,在 "ext_dict" 模块,增加 "my.dic"。
这里可以配置多个 dic 文件,多个之间用 ";" 分隔。
注意:集群中每个节点都要修改!
重启 es 后查看效果:分词器可以识别此专属词汇了
同义词
当我们在淘宝、京东上搜索"苹果"时,既能搜索出来iphone,又能搜出来真实吃的苹果。或者"西红柿"和"番茄",就是同一个东西。这种就要用到同义词了。
我想实现的效果:
- 不管输入【西红柿】还是【番茄】,都能同时搜出【西红柿 & 番茄】
- 在输入【苹果】时,能同时搜索出【苹果&iphone】,但是在输入【iphone】时,只能搜索出【iphone】
首先在 "plugins/ik/config" 目录下新建 "analysis" 目录,然后在 "analysis" 目录下新建文件 "synonym.txt"。之后在 "synonym.txt" 文件中添加同义词。

注意:是英文逗号!且集群中每个节点都要添加此配置!
这里使用了两种写法:
- 第一种是使用【逗号分隔】,平等看待所有的同义词
- 第二种是使用【类型扩展】,不平等地看待同义词
之后重启 es,然后创建索引时,对分词器进行扩展。同时,在需要的字段中设置使用扩展后的分词器:
"settings":{
"analysis": {
"analyzer": {
"synonym_smart": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": ["synonym_filter"]
},
"synonym_max_word": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["synonym_filter"]
}
},
"filter": {
"synonym_filter": {
"type": "synonym",
"synonyms_path": "/usr/share/elasticsearch/plugins/ik/config/analysis/synonym.txt"
}
}
}
}"name":{
"type": "text",
"analyzer": "ik_max_word", "search_analyzer": "synonym_smart"
},
注意:这里虽然定义了 "synonym_max_word",但其实没有使用到它,建立索引时使用的分词器仍然是 "ik_max_word",而在搜索时使用了 "synonym_smart"。
因为如果在建立索引时使用了 "synonym_max_word",在输入 【iphone】时,也会搜索出来 【苹果】,而这不是我想要的效果。
具体可以参考官方文档关于【类型扩展】的说明:
扩展或收缩 | Elasticsearch: 权威指南 | Elastic
之后插入点数据,然后测试查询。
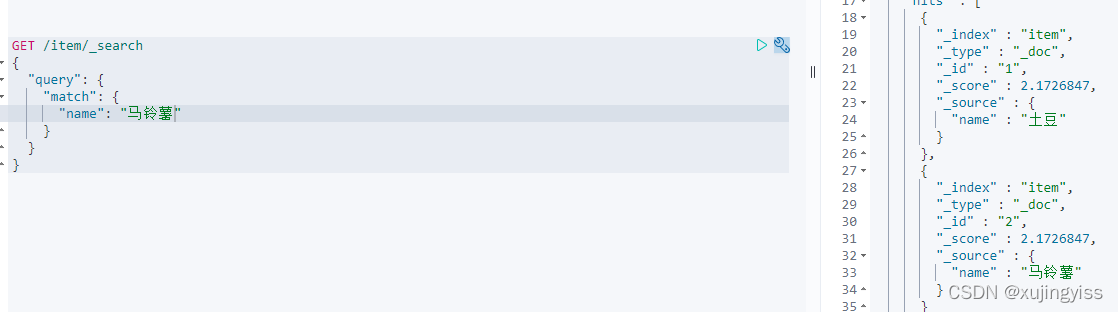
1)输入 "土豆" 或者 "马铃薯",都能同时搜到"土豆"与"马铃薯"

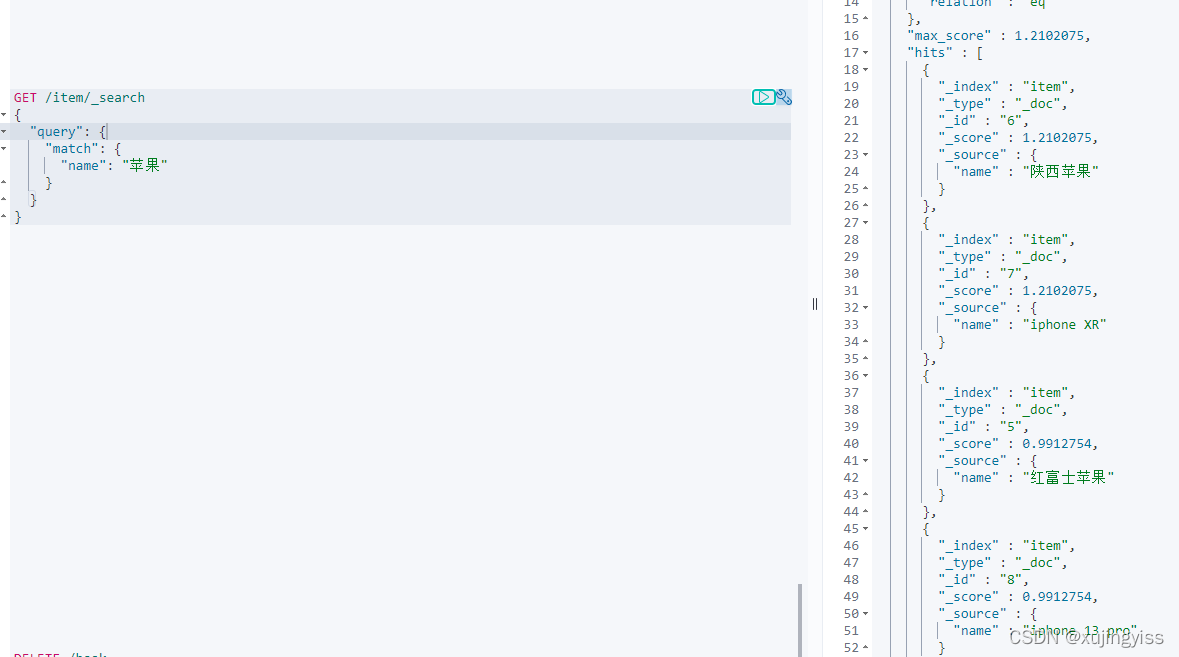
2)输入"苹果",能同时搜到"苹果"与"iphone"
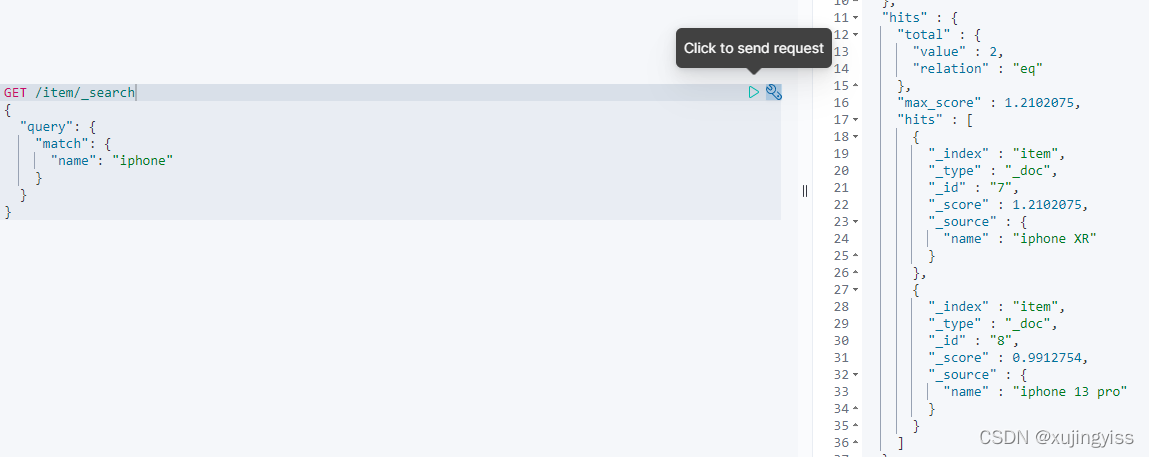
3)输入"iphone",只能搜到"iphone"
英文驼峰形式分词
IK分词器默认也是不支持英文驼峰形式的分词的。比如 "PersonAndVehicleDetection" 这个字符串,使用 IK 分词器分析出来的结果,仍然是 "PersonAndVehicleDetection"
GET /book/_analyze
{
"field": "description",
"text": "PersonAndVehicleDetection"
}分析结果:
{
"tokens" : [
{
"token" : "personandvehicledetection",
"start_offset" : 0,
"end_offset" : 25,
"type" : "ENGLISH",
"position" : 0
}
]
}
此时,根据字符串 "person" 来查,是查不到的:
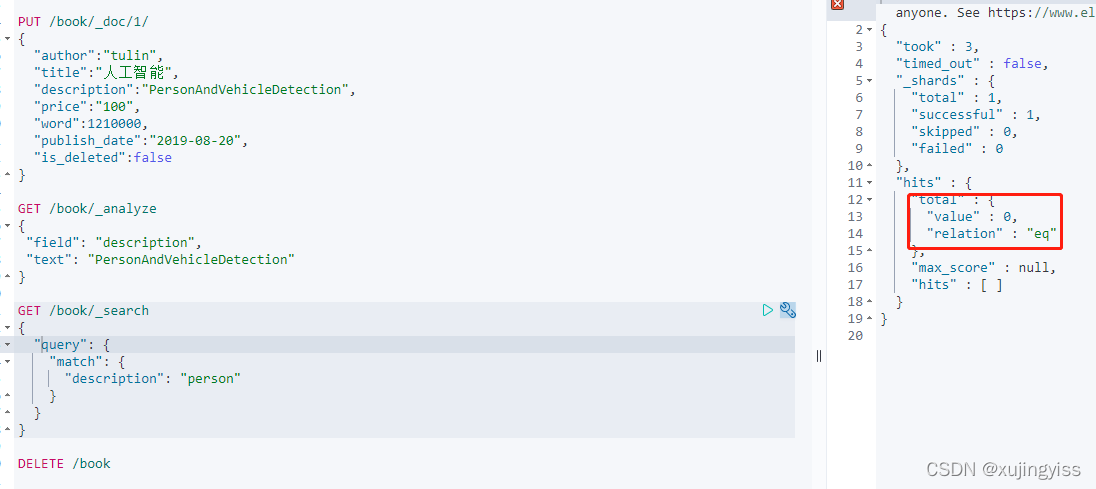
但是业务需要,在输入 person 或者 vehicle 时,也想要查询出此条数据时怎么办呢?那就需要对分词器做一些扩展,在创建索引时,在 settings 中的 analysis 里配置自己的分词器,然后在 mappings 中的字段中引用该分词器:
"settings":{
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"char_filter": [
"camel_case_filter"
]
}
},
"char_filter": {
"camel_case_filter": {
"type": "pattern_replace",
"pattern": "(?<=\\p{Lower})(?=\\p{Upper})",
"replacement": " "
}
}
}
}"description":{
"type": "text",
"analyzer": "my_analyzer", "search_analyzer": "ik_smart"
}
使用了新的 analyzer 之后再分析看结果:
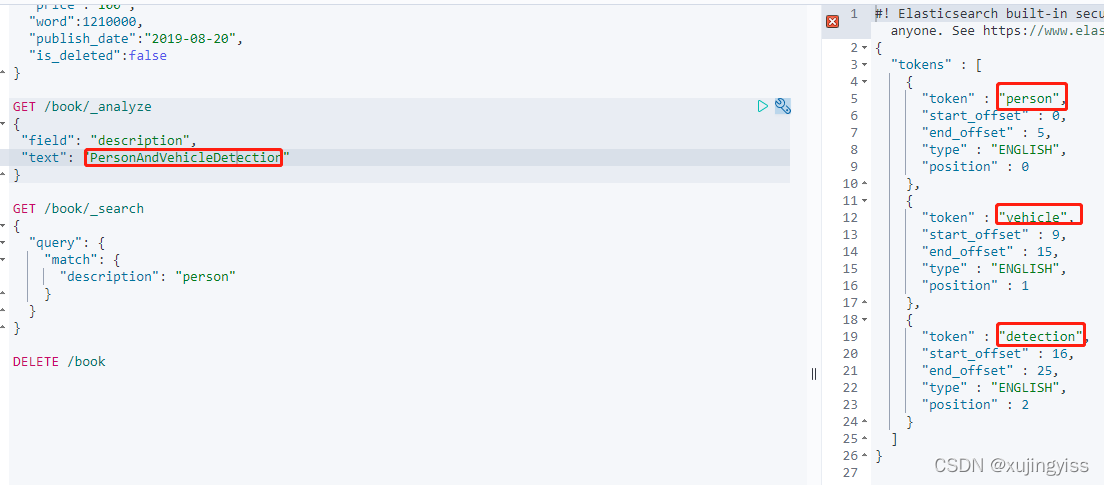
然后再查询发现能查询到了:
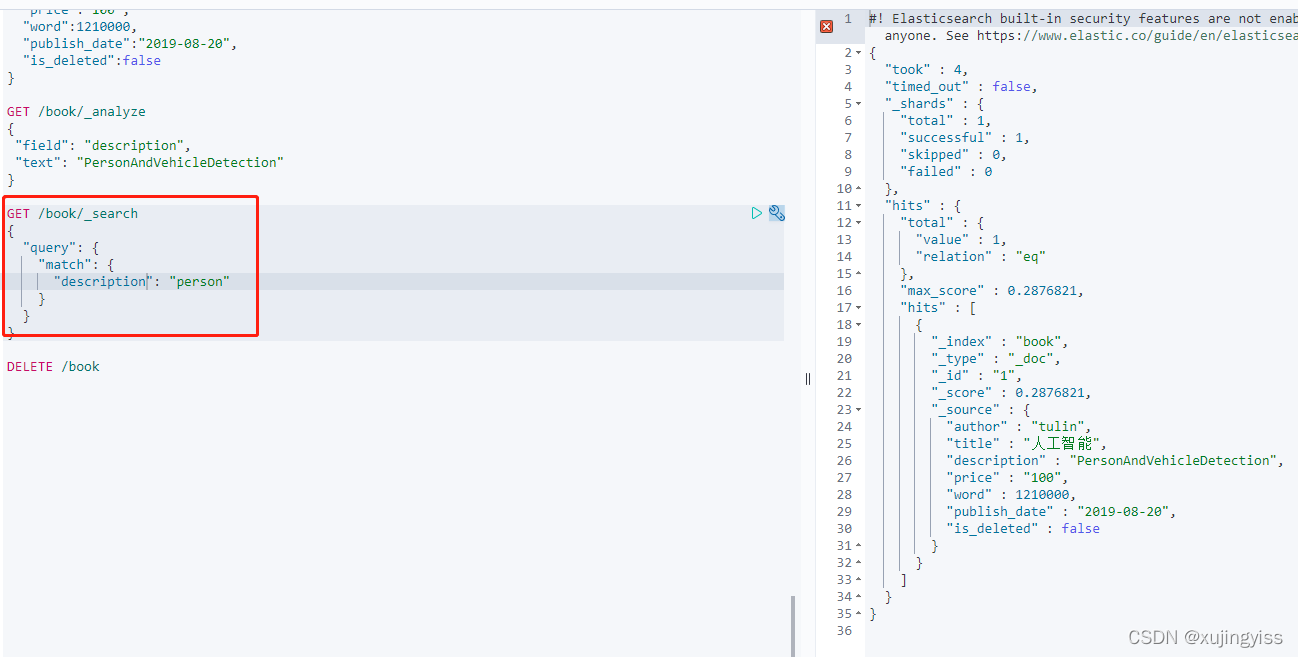

















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









