



一,内核链表的特点
内核链表是Linux内核中广泛使用的一种数据结构,它具有以下特点:
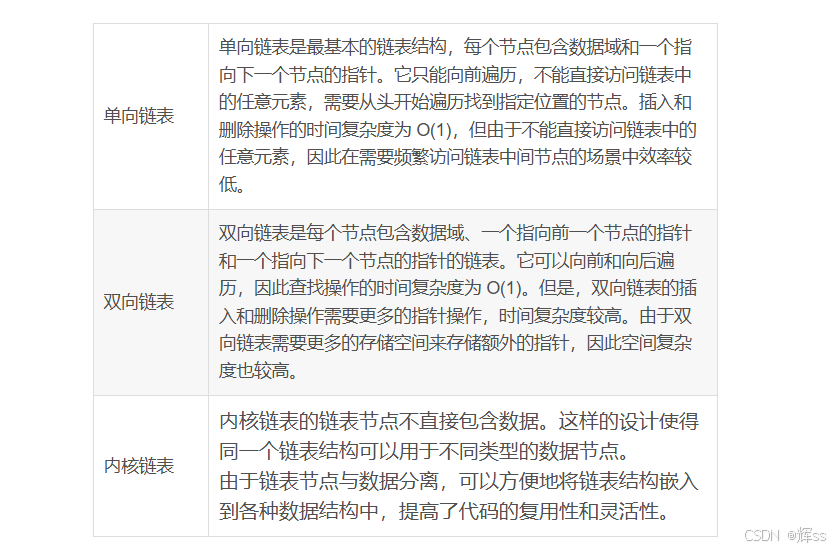
1.双向循环链表:每个节点包含两个指针,一个指向前驱节点(prev),另一个指向后继节点(next),形成一个闭环。
2.结构封装:链表节点不直接包含数据。这样的设计使得同一个链表结构可以用于不同类型的数据节点。
3.通用性:由于链表节点与数据分离,可以方便地将链表结构嵌入到各种数据结构中,提高了代码的复用性和灵活性。
二.内核链表与单向以及双向链表的区别
1.普通链表概念简单,操作方便,但存在有致命的缺陷,即:每一条链表都是特殊的,不具有通用性。因为对每一种不同的数据,所构建出来的链表都是跟这些数据相关的,所有的操作函数也都是数据密切相关的,换一种数据节点,则所有的操作函数都需要一一重新编写,这种缺陷对于一个具有成千上万种数据节点的工程来说是灾难性的。
2、内核链表
如前所述,内核链表解决通用性问题,大概分两步:
①设计标准节点
②针对标准节点,设计由标准节点构成的标准链表的所有操作
三.内核链表组成
节点结构
内核链表的节点通常包含至少两个指针:一个指向前一个节点(prev),另一个指向后一个节点(next)。在某些实现中,还可能包含一个指向数据本身的指针,但在Linux内核的链表中,节点本身并不直接存储用户数据,而是将用户数据保存在包含链表节点的结构体中。
链表头
链表头是一个特殊的节点,它通常不包含有效数据,但用于标识链表的开始位置。在双向链表中,链表头还可能包含指向链表最后一个节点的指针,以及一个指向链表第一个节点的指针。

















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









