




 本文深入探讨了MapReduce中In-Map聚合与Combiner的区别及应用场景,详细解析了In-Map聚合如何在Map阶段直接进行数据聚合,从而避免了不必要的序列化与反序列化过程,提高了处理效率。
本文深入探讨了MapReduce中In-Map聚合与Combiner的区别及应用场景,详细解析了In-Map聚合如何在Map阶段直接进行数据聚合,从而避免了不必要的序列化与反序列化过程,提高了处理效率。
为什么使用in-map aggregation, 与combine 有什么区别,什么时候使用combiner ,什么时候使用in-map 聚合?
先介绍用一张图看看一下combiner 在一个mr job中的位置。
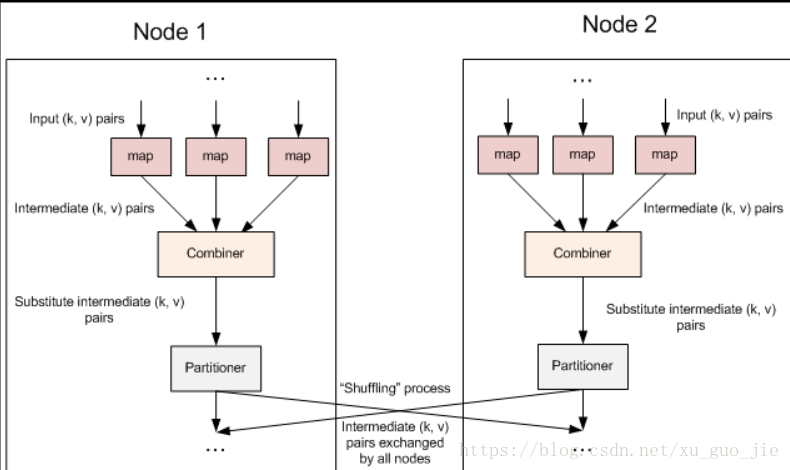
下面上干货:
数据文件 由 InputFormat 读取,传入到Map阶段处理。 Map处理完后,会把结果key value 对写到Map 任务节点内存中的一个环形缓存区。写到缓存区的Key Value 对已经是 序列化过的了,这是一个重点!
然后当map 任务结束或者缓存区使用率到一定阶段,会发生spill 溢写(map 端至少会发生一次磁盘写入),在spill溢写之前 会调用Combine 进行聚合。
那Combine 拿到已经序列化的key value 对后首先要进行反序列化,然后再进行聚合,然后再进行序列化写入磁盘。这是Combine的处理过程。
那in-map 聚合是什么概念?
in-map 聚合是指,map结果输出时进行聚合,这样避免了反序列化-处理-再序列化 这样一个过程。
具体实现是使用到了Map 的一setup() 与 cleanup() 两个方法。
setup : 是当这map task 运行前首先执行的一个方法。
cleanup:是指当前map task运行结束时最后执行的一个方法。
具体通过代码体会吧 :注意一点context.write 是在 cleanup方法中执行的。
public static class MyWordCountMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
Logger log = Logger.getLogger(MyWordCountJob.class);
Map<Character,Integer> map = new HashMap<Character,Integer>();
Text mapKey = new Text();
IntWritable mapValue = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
for(char c :value.toString().toLowerCase().toCharArray()){
if(c>='a' && c <='z'){
map.put(c,map.get(c)+1);
}
}
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
for(char key : map.keySet()){
mapKey.set(String.valueOf(key));
mapValue.set(map.get(key));
context.write(mapKey, mapValue);
}
}
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
for(char c='a';c<='z' ;c++){
map.put(c, 0);
}
}
}
看执行结果
16/05/11 06:25:30 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=630
FILE: Number of bytes written=338285
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=556
HDFS: Number of bytes written=107
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=3
Launched reduce tasks=1
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=515880
Total time spent by all reduces in occupied slots (ms)=68176
Map-Reduce Framework
Map input records=8
Map output records=78
Map output bytes=468
Map output materialized bytes=642
Input split bytes=399
Combine input records=0
Combine output records=0
Reduce input groups=26
Reduce shuffle bytes=642
Reduce input records=78
Reduce output records=26
Spilled Records=156
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=164
CPU time spent (ms)=3490
Physical memory (bytes) snapshot=1089146880
Virtual memory (bytes) snapshot=3962114048
Total committed heap usage (bytes)=868352000
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=157
File Output Format Counters
Bytes Written=107
通过Counter 可以看出Reducer 的输入为78个, 与使用Combiner 的效果是一样的。 而Map输出的记录数减少到了78个。
继续研究这个例子,可以看到 代码中定义了一个map,来存放所有的字符的数量。这个map中最大的记录数也就26个,占用内存不大,那这是适用的。
假如我们统计的是单词数量,而且单词数量很多,就可能会导致map task的内存中存放不下,那这种情况就是不适用的!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









