



1、Excel表格拆分:有一张产品销售情况数据表,有5个不同的产品,现需要把源数据表根据不同产品拆分成5个新的Excel表格。
(数据准备:直接新建一张Excel表,输入若干个字段,订单编号设为100001,下拉向下填充若干百条,产品名称任意填充五种,其他直接用问号填充):
| 订单编号 | 产品名称 | 产品售价 | 产品销量 | 负责人 |
| 1000001 | 产品A001 | ? | ? | ? |
| 1000002 | 产品A001 | ? | ? | ? |
| 1000003 | 产品A001 | ? | ? | ? |
| 1000004 | 产品A001 | ? | ? | ? |
原表

变成
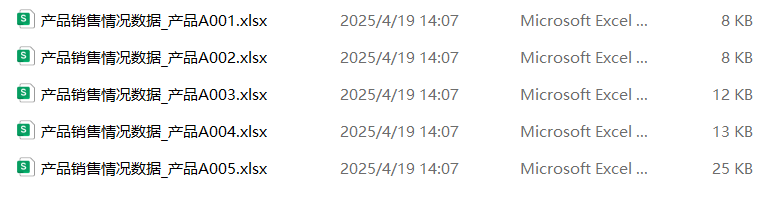
import pandas as pd
df=pd.read_excel("data/产品销售情况数据.xlsx") #读取数据
for i in df["产品名称"].drop_duplicates(): #根据不同的产品名称去除产品数据并写入新的Excel
df[df["产品名称"]==i].to_excel("data/产品销售情况数据_"+i+".xlsx",index=False)
2、多张表合并成1张Excel表:现有5张不同产品的数据表,需要把其汇总成一张Excel表。
原来:
变成:
import pandas as pd
import os
df_list=[]
# os.listdir('data/')读取"data/"文件夹下所有文件的名字
# "产品销售情况数据_产品A001.xlsx".split(".")[1]的作用是对字符串根据“.”进行拆分并返回结果列表的第二个值,这里返回的是“xlsx"
for i in os.listdir('data/'):
if i.split('.')[1]=="xlsx": #判断文件格式是否为xlsx
df=pd.read_excel('data/'+i)
df_list.append(df) #把读取的内容入到df_list列表中
df=pd.concat(df_list,ignore_index=True)
df.to_excel('totaldata/产品销售情况数据汇总.xlsx',index=False)

















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









