




 本文介绍了如何通过Python爬虫抓取雪球网上使用Ajax动态加载的热股榜数据。在解析过程中,由于原始HTTP请求缺少必要的Cookie信息,导致返回400状态码。通过添加浏览器中的Cookie到请求头,成功解决了问题并实现了数据的正确获取。
本文介绍了如何通过Python爬虫抓取雪球网上使用Ajax动态加载的热股榜数据。在解析过程中,由于原始HTTP请求缺少必要的Cookie信息,导致返回400状态码。通过添加浏览器中的Cookie到请求头,成功解决了问题并实现了数据的正确获取。
最近在实习,同事给我安排了个小任务:写一个爬虫把雪球网上关注度比较高的股票抓下来,每天2点抓一次,然后同时将股票信息通过钉钉推送给他。
我像往常一样用requests抓取页面,但是我发现这样得到的结果和在浏览器中看到的不一样,我找不到我需要的内容。在浏览器中可以看到正常显示的页面数据,但是使用requests得到的结果并没有。
经过百度发现是因为,requests获取的都是原始的HTML文档,而浏览器中的页面则是经过JavaScript处理数据后生成的结果,这些数据的来源有多种,可能是通过Ajax加载的,可能是包含在HTML文档中的,也可能是经过JavaScript和特定算法计算后生成的。
所以如果遇到这样的情况,就要用其他的办法。
1. 请求
进入网页:https://xueqiu.com/
打开Ajax的XHR过滤器,然后在热股榜里一直点“沪深”,“港股或”美股”,就可以看到,会不断有Ajax请求发出。
也就是不断的会有“list.josn?size=8&&_type=....”出现。
选定我们关注的“沪深”。点击该请求,进入详情页面。
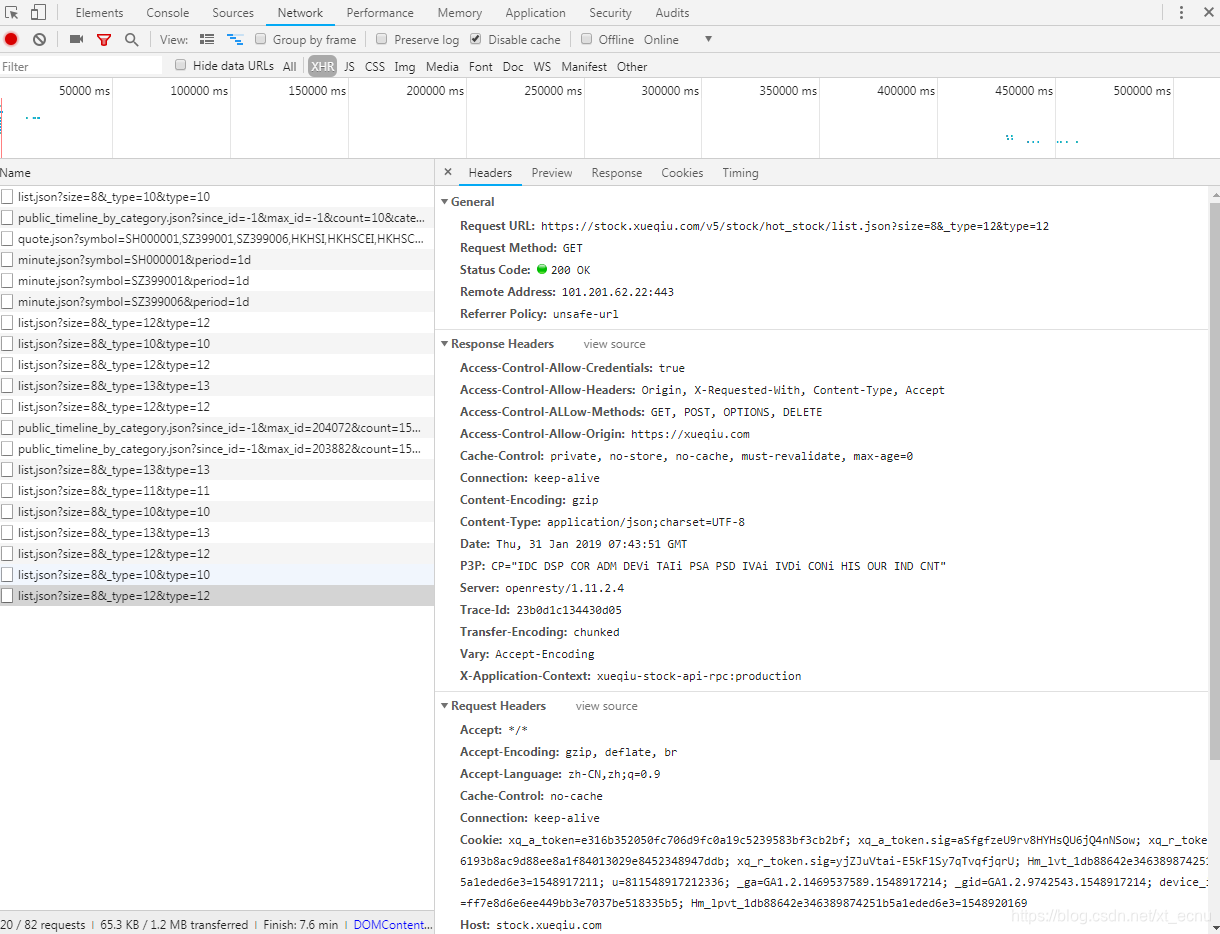
可以发现
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2634
2634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









