




 本文介绍了中文分词技术,特别是知更鸟分词器(RS/Robin-Segmenter)的设计和实现,重点讨论了逆向回退策略的正向最大匹配算法。此外,还与其他常见分词工具如JE、IK、PD和MS进行了性能和准确性的对比验证。
本文介绍了中文分词技术,特别是知更鸟分词器(RS/Robin-Segmenter)的设计和实现,重点讨论了逆向回退策略的正向最大匹配算法。此外,还与其他常见分词工具如JE、IK、PD和MS进行了性能和准确性的对比验证。
内容提要
本文设计了一种带逆向回退策略的正向最大匹配。
1 分词概述
英文文本的处理相对简单,每一个单词之间有空格或标点符号隔开。如果不考虑短语,仅以单词作为唯一的语义单元的话,处理英文单词切分相对简单,只需要分类多有单词,去除标点符号。中文自然语言处理首先要解决的难题就是中文分词技术。
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
2 算法分类
现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
2.1 字符匹配
这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配。
常用的几种机械分词方法如下:
1)正向最大匹配法(由左到右的方向);
2)逆向最大匹配法(由右到左的方向);
3)最少切分(使每一句中切出的词数最小);
4)双向最大匹配法(进行由左到右、由右到左两次扫描)
2.2 理解法
这种分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
2.3 统计法
从形式上看,词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。可以对语料中相邻共现的各个字的组合的频度进行统计,计算它们的互现信息。定义两个字的互现信息,计算两个汉字X、Y的相邻共现概率。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。但这种方法也有一定的局限性,会经常抽出一些共现频度高、但并不是词的常用字组,例如“这一”、“之一”、“有的”、“我的”、“许多的”等,并且对常用词的识别精度差,时空开销大。实际应用的统计分词系统都要使用一部基本的分词词典(常用词词典)进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
3 常见项目
极易分词(JE)
MMAnalyzer极易中文分词组件,由中科院提供的中文极易分词器。比较完善的中文分词器。
支持英文、数字、中文(简体)混合分词。
常用的数量和人名的匹配。
超过22万词的词库整理。
实现正向最大匹配算法。
IKAnalyzer(IK)
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
Paoding(PD)
Paoding(庖丁解牛分词)基于Java的开源中文分词组件,提供lucene和solr 接口,具有极 高效率和 高扩展性。引入隐喻,采用完全的面向对象设计,构思先进。
高效率:在PIII 1G内存个人机器上,1秒可准确分词 100万汉字。
采用基于不限制个数的词典文件对文章进行有效切分,使能够将对词汇分类定义。
能够对未知的词汇进行合理解析。
仅支持Java语言。
MMSEG4J(MS)
MMSEG4J基于Java的开源中文分词组件,提供lucene和solr 接口:
1.mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。
2.MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex 加了四个规则过虑。官方说:词语的正确识别率达到了 98.41%。mmseg4j 已经实现了这两种分词算法。
smallseg(SS)
开源的,基于DFA的轻量级的中文分词工具包。
特点:可自定义词典、切割后返回登录词列表和未登录词列表、有一定的新词识别能力。
4 知更鸟分词实现
中文分词既然作为自然语言处理的基本工具,那么我们就来实现一个基于字符匹配的中文分词,用我的英文名(Robin)给她起个名字,就叫做——知更鸟分词器(RS/Robin-Segmenter)。
4.1 算法描述
基本实现算法:
(1)正向最大匹配;
(2)逆向最大匹配;
(3)逆向回退策略的正向最大匹配(重点)。
支持以下功能:
- 新词发现、新词标注;
- 字符转换、格式统一;
- 自定义分割符;
- 特殊符号保留;
- 检索分词模式;
- 合并拆分模式;
4.2 数据结构
基于字典字符匹配匹配的分词算法,重点是字典数据结构的设计。好的字典数据结构能够极大提升匹配检索的效率。
采用基本容器HashMap实现的一种变种字典树(Trie)结构。其基本的思想如图。
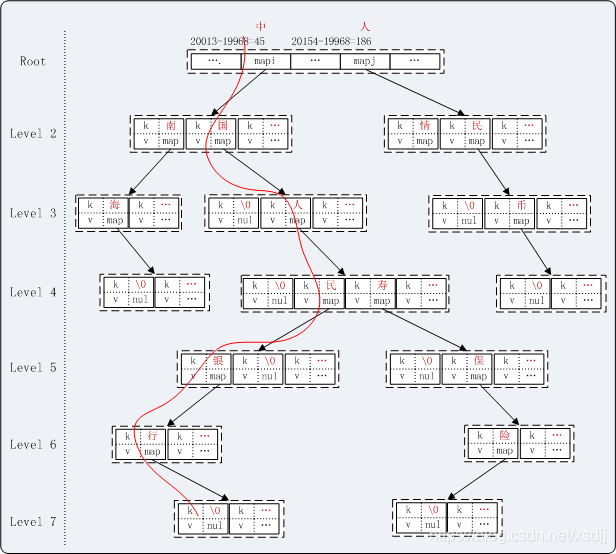
假设词典:中国 | 中南海 | 人民 | 人民币 | 人情 | 银行 | 中国人民 | 中国人民银行 | 中国人寿保险 | ……
例如:“中国人民银行行长易纲。”这样一条文本的匹配过程如图示红线路径。分词结果应该示“中国人民银行 行长 易纲”。
由于中文词首字分布比较均匀,并且查询首字的概率远大于其他非首字,根节点采用map数组方式,数组下标为字符的Unicode码减去最小中文汉字 Unicode码。数组维度为汉字的Unicode码范围。
4.3 部分代码
Unicode工具类:
package com.robin.segment.robinseg;
import com.robin.config.ConfigUtil;
import com.robin.file.FileUtil;
import java.util.HashSet;
import java.util.Set;
/**
* <DT><B>描述:</B></DT>
* <DD>Unicode 编码工具类</DD>
*
* @version Version1.0
* @author Robin
* @version <I> V1.0 Date:2018-01-28</I>
* @author <I> E-mail:xsd-jj@163.com</I>
*/
public class Unicode {
/** 量词配置路径 */
private static final String QUANTIFIER_PATH;
/** 量词集合 */
private static Set<Character> quantifierSet;
/** 中文数词路径 */
private static final String NUMERAL_PATH;
/** 中文数词集合 */
private static Set<Character> numeralSet;
/** 词典文件编码 */
private static final String DIC_ENCODING;
/** 空字符 Unicode */
public static final int NULL = 0x0;
/** 半角空格 Unicode */
public static final int DBC_BLANK = 0x20;
/** 半角句点 Unicode */
public static final int DBC_POINT = 0x2E;
/** 半角0 Unicode */
public static final int DBC_0 = 0x30;
/** 半角9 Unicode */
public static final int DBC_9 = 0x39;
/** 半角A Unicode */
public static final int DBC_A = 0x41;
/** 半角Z Unicode */
public static final int DBC_Z = 0x5A;
/** 半角a Unicode */
public static final int DBC_LA = 0x61;
/** 半角z Unicode */
public static final int DBC_LZ = 0x7A;
/** 普通最小中文汉字 Unicode */
public static final int MIN_CHINESE = 0x4E00;
/** 普通最大中文汉字 Unicode */
public static final int MAX_CHINESE = 0x9FA5;
/** 全角空格 Unicode */
public static final int SBC_BLANK = 0x3000;//0xFF00也是全角空格
/** 关注全角下限 Unicode */
public static final int SBC_LOW_LIMIT = 0xFF00;
/** 关注全角上限 Unicode */
public static final int SBC_UP_LIMIT = 0xFF5E;
/** 全角句点 Unicode */
public static final int SBC_POINT = 0xFF0E;
/** 全角0 Unicode */
public static final int SBC_0 = 0xFF10;
/** 全角9 Unicode */
public static final int SBC_9 = 0xFF19;
/** 全角A Unicode */
public static final int SBC_A = 0xFF21;
/** 全角Z Unicode */
public static final int SBC_Z = 0xFF3A;
/** 全角a Unicode */
public static final int SBC_LA = 0xFF41;
/** 全角z Unicode */
public static final int SBC_LZ = 0xFF5A;
/** 半角全角数字或字母 Unicode 编码偏移 */
public static final int OFFSET_DBC_SBC = 0xFEE0;
/** 英文大小写字母 Unicode 编码偏移 */
public static final int OFFSET_UP_LOW = 0x20;
static {
QUANTIFIER_PATH = ConfigUtil.getConfig("dic.quantifier");
NUMERAL_PATH = ConfigUtil.getConfig("dic.numeral");
DIC_ENCODING = ConfigUtil.getConfig("dic.encoding");
initQantifierSet();
initNumeralSet();
}
/**
* Unicode 字符类型
*/
public enum CharType {
/** 控制符 */
CONTROL,
/** 半角数字 */
DBC_DIGIT,
/** 半角大写字母 */
DBC_UPPER_CASE,
/** 半角小写字母 */
DBC_LOWER_CASE,
/** 中文 */
COMMON_CHINESE,
/** 全角字符 */
SBC_CHAR,
/** 全角字母 */
SBC_CASE,
/** 全角数字 */
SBC_DIGIT,
/** 全角大写字母 */
SBC_UPPER_CASE,
/** 全角小写字母 */
SBC_LOWER_CASE,
/** 小数点 */
DECIMAL_POINT,
/** 数字后缀 */
DECIMAL_SUFFIX,
/** 百分比符号 */
PERCENT_CHAR,
/** 空白符 */
BLANK_CHAR,
/** 其他 */
OTHER_CHAR,
}
/**
* 通过字符判断其类型
*
* @param ch Unicode字符
* @return 字符类型
*/
public static CharType getCharType(char ch) {
int value = ch;
//Unicode 普通中文汉字区
if ((value >= MIN_CHINESE) && (value <= MAX_CHINESE)) {
return CharType.COMMON_CHINESE;
}
//空白符、控制字符、半角空格0x20、全角空格0x3000
if ((value <= DBC_BLANK) || (value == SBC_BLANK)) {
return CharType.BLANK_CHAR;
}
//半角数字0-9:0x30-0x39
if ((value >= DBC_0) && (value <= DBC_9)) {
return CharType.DBC_DIGIT;
}
//半角字母a-z:0x61-0x7A
if ((value >= DBC_LA) && (value <= DBC_LZ)) {
return CharType.DBC_LOWER_CASE;
}
//半角字母A-Z:0x41-0x5A
if ((value >= DBC_A) && (value <= DBC_Z)) {
return CharType.DBC_UPPER_CASE;
}
//小数点:半角0x2E
if (value == DBC_POINT) {
return CharType.DECIMAL_POINT;
}
//数字后缀
if ((value == (int) ('%'))
|| (value == (int) ('$'))
|| (value == (int) ('¥'</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2727
2727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









