



 该论文提出了一种对抗多任务学习框架,旨在解决多任务学习中任务特有特征干扰共享知识的问题。通过引入对抗训练和正交约束,确保共享特征空间只包含通用特征,而私有特征空间则不含冗余。实验表明这种方法在文本分类任务中表现出色。
该论文提出了一种对抗多任务学习框架,旨在解决多任务学习中任务特有特征干扰共享知识的问题。通过引入对抗训练和正交约束,确保共享特征空间只包含通用特征,而私有特征空间则不含冗余。实验表明这种方法在文本分类任务中表现出色。
论文 : Adversarial Multi-task Learning for Text Classification
最近决定每周读一篇GAN的论文。一方面,提升自己的阅读理解能力。另一方面,拓展自己的思路。作为GAN的初学者,有很多表述不当的地方欢迎大家批评指正!
标题:对抗多任务学习用于文本分类。所谓多任务学习(MTL)就是指学习某一类任务的通用知识(focus on learning the shared layers to extract the common and task-invariant features)。比如学习AlexNet,VGG的卷积部分(不含全连接层)。这样学习出来的卷积特征通常表示一些通用的特征表示(类似于SIFT,HOG)。而利用全连接层,就可以学的一些可以针对某个具体任务的特征,比如分类,分割,检测等。详细可以看这篇关于多任务学习文章。
Abstract
作者提出利用GAN进行多任务学习,可以缓解多任务学习中学习的shared knowledge存在task-specific features问题。
Introduction
作者为解决目前多任务学习中存在的问题,设计了一个shared-private learning framework. 其主要关键点就是引入了对抗训练以及正交约束,这样可以阻止 shared and private latent features from interfering with each other。说白了,作者就是要将task-specific features 以及 task-dependent features分开来,示意图如下:
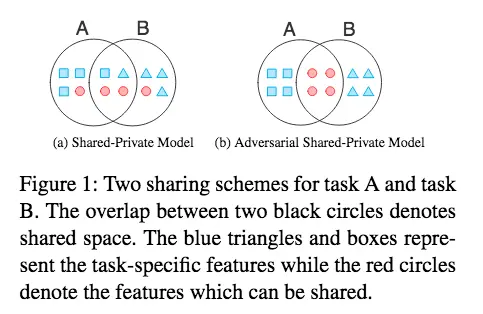
举个栗子,通用的shared-private model存在下面的问题:
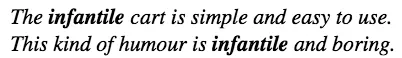
第一句话的infantile是一个中性词,但是第二句是贬义词。显然,这是一个task-specific feature, 但是,目前的模型却会把他们放到shared space,这样就会导致shared space 中的特征冗余。为了解决这个问题,作者提出的框架引入了正交约束,使得shared-privete space 天生就是分离的。
作者提出的框架具有两个关键点:
- 对抗训练:使得shared features space 仅仅包含通用的特征。
- 正交约束:从private and shared space中消除冗余约束。
作者本文的工作有以下三点:
- 提出了一种更精确的划分task-specific features 以及 shared space 的方法,而不是以前那种通过shared parameters来粗糙的划分。
- 对于多类问题,拓展了以前的二值GAN,不仅使得多任务可以联合训练,而且还可以利用未标记的数据。
- 将shared knowledge 浓缩到现成的layer中,使其可以很容易的迁移到新任务中。
LSTM用于文本分类
LSTM可以表示为下式:

对于分类问题,给定一个词序列,首先要学得每一个词的向量表示(即词嵌入,所谓词嵌入,是学得序列的一个向量表示,ont-encoding就是一种表示,但这样通常维度很高,词嵌入通常有一个降维过程,word2vec就是一种词嵌入方法),经过LSTM之后,其最后一个时刻的输出h作为整个序列的特征表示,而后跟上一个softmax非线性层预测每一类的概率。
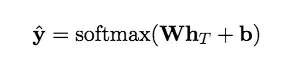
网络的优化目标是交叉熵损失。
Multi-task Learning for TextClassification
多任务学习的关键就是在潜在的特征空间共享方案。共享方案通常有两种:
- Fully-Shared Model (FS-MTL) :这种模型忽略了task-dependent特性
- Shared-Private Model (SP-MTL) :这种模型对每个任务都引入了shared space 和 private space。分别用LSTM学得,并级联。
示意图如下:
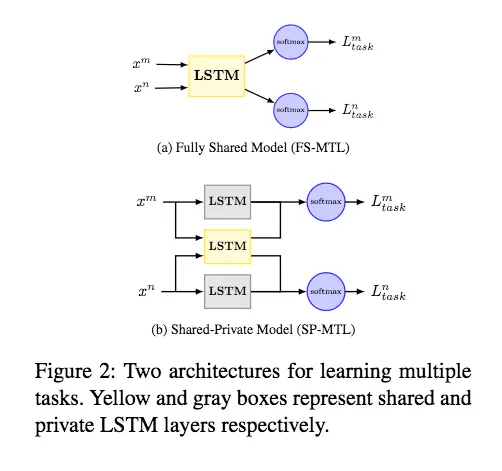
上图其实表示的就是多任务学习的两种网络框架,上述网络的优化目标如下(alpha为各个任务的权重因子,L表示交叉熵损失):
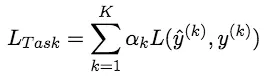
Incorporating Adversarial Training
作者将shared space学得的特征丢到判别器中,最大化判别器的损失,以达到对抗训练的目的。损失函数如下(d表示任务的类型):
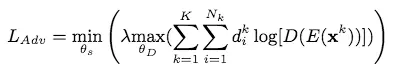
对于一个sentence,LSTM生成一个特征表示误导判别器,与此同时,判别器尝试尽可能减小判别误差。此外,从上面的公式可以看出,训练过程并未用到样本的label,所以可以将这个引入无监督学习以解决相关问题。
可以看出,上述模型还存在一个问题,那就是对抗训练只能保证task-dependent features 不进入shared space,但是task-invariant features还是会进入private space。因此,作者受他人工作启发,引入正交约束,对代价函数进行惩罚,使LSTM尽量从不同层面提取特征。惩罚函数如下:
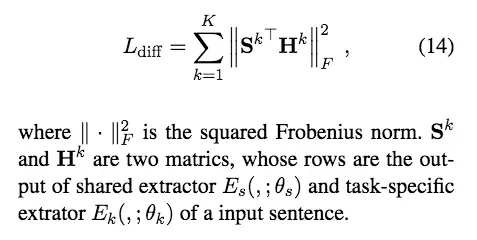
总结起来,最终代价函数如下(lambda和gama为超参数,即各个loss的权重比例):
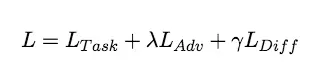
网络利用反向传播进行训练,对抗网络的训练可以用gradient reverse layer。整体网络框架如下:

Experiment
效果不错,就不讲啦。
作者本文的两大关键点就是:对抗训练,正交约束。

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









