



Nginx学习:安全链接、范围分片以及请求分流模块
又迎来新的模块了,今天的内容不多,但我们都进行了详细的测试,所以可能看起来会多一点哦。这三个模块之前也从来都没用过,但是通过学习之后发现,貌似还都挺有用。当然,还是要根据具体业务情况来看,如果你的业务中有用到,那么就可以尝试一下哦。
安全链接是实现请求 URL 的验证模块,通过签名密钥来判断请求是否可以返回相应的数据。范围分片一般用于分段下载,主要用于代理时请求后端的 Range
头的设置。最后的请求分流不太好说清楚,咱们到文章中详细再说明吧。
今天的内容大部分可以在 http、server、location 下配置,仅有两个只能在 http 或 location 下配置,我会单独说。
安全链接
安全链接模块
ngx_http_secure_link_module(0.7.18),可以用于检查请求链接的真实性,保护资源免受未经授权的访问,并限制链接寿命。
请求链接的真实性通过将请求中传递的校验和值与为请求计算的值进行比较来验证。这个其实就像我们做 App 接口时,一般都会加个 sign
签名一样,客户端使用和服务端相同的方式进行签名,用于验证客户端发来的请求是否有效。另外,这个模块还可以根据链接的生命周期来进行验证,如果生命周期有限且时间已过,则认为该链接已过期。这些检查的状态在
$secure_link 变量中可用。
该模块提供了两种可选的操作模式。第一种模式由secure_link_secret
指令启用,用于检查请求链接的真实性以及保护资源免受未经授权的访问。第二种模式 (0.8.50) 由secure_link 和secure_link_md5
指令启用,也用于限制链接的生命周期。这两种形式我们后面都会进行测试。
它不包含在 Nginx 核心源码中,需要通过 --with-http_secure_link_module
编译安装。我们还是先来看看这个模块所包含的配置项,然后再进行综合的测试。
secure_link
定义一个带有变量的字符串,将从中提取链接的校验和值(md5+base64)和生命周期。
secure_link expression;
表达式中使用的变量通常与请求相关联,一般可以设置为 $arg_md5 ,这个变量名是可以自己起的,目的就是获取到这个加密值。将从字符串中提取的校验和值与
secure_link_md5 指令定义的表达式的 MD5 哈希值进行比较。如果校验和不同,则 $secure_link
变量设置为空字符串。如果校验和相同,则检查链路寿命。
如果链接的生命周期有限且时间已过,则 $secure_link 变量设置为“0”。否则,设置为“1”。请求中传递的 MD5 哈希值以 base64url
编码。如果链接的生命周期有限,则过期时间设置为自 Epoch(1970 年 1 月 1 日星期四 00:00:00 GMT)以来的秒数。
该值在 MD5 哈希后的表达式中指定,并以逗号分隔,比如 $arg_sign、$arg_expires ,后面这个 expires 就是可以通过
GET 获取的过期时间值。请求中传递的过期时间可通过 $secure_link_expires 变量在secure_link_md5
指令中使用,不使用也行,后面测试时我们会看到。如果未指定过期时间,则链接具有无限的生命周期。
secure_link_md5
定义一个表达式,将计算 MD5 哈希值并将其与请求中传递的值进行比较。
secure_link_md5 expression;
表达式应包含链接(资源)的安全部分和秘密成分。如果链接的生命周期有限,则表达式还应包含 $secure_link_expires
。为了防止未经授权的访问,表达式可能包含有关客户端的一些信息,例如其地址和浏览器版本。
比如我们可以指定为 secure_link_md5 '$uri zzyy'; ,那么上面 secure_link 第一个设置的值就是
base64_encode(md5('请求的链接地址 zzyy')) 这样的结果就可以和 secure_link_md5
的值匹配上。如果不匹配,$secure_link 会是空,如果使用了过期时间,并且时间确实过期了,那么就是 0 ,这时就可以使用 if
指令判断是否验证成功做出不同的操作。
看不懂是吧?没事,一会测试例子运行一下就明白了。
secure_link_secret
定义用于检查所请求链接的真实性的秘钥。
secure_link_secret word;
仅能在 location 下配置。请求链接的完整 URI 如下所示:
/prefix/hash/link
其中 hash 是 MD5 散列的十六进制表示,用于连接链接和秘钥,prefix 是不带斜杠的任意字符串。如果请求的链接通过了真实性检查,则
$secure_link 变量设置为从请求 URI 中提取的链接。否则,$secure_link 变量设置为空字符串。
这个又是啥玩意?注意,它是单独使用的,和上面那两个没关系。假如我们设置 secure_link_secret zyblog; 请求地址为
/p/17ceb6c14933609f0ab68e37fe633b1a/1.html ,那么中间加密的部分其实就是 md5('1.htmlzyblog') 。前面的 /p/ 是没啥用的,因为这个配置只能在 location 下配置,所以这个前缀就是 location 的 URI 部分。
使用上面的链接可以将 $secure_link 设置为 1.html ,然后我们就可以通过 rewrite 去请求真实的 1.html
了,这里可以加个判断,如果 $secure_link 为空,就返回异常页面,这样就实现了链接的验证。
嗯,说不明白,还是一会看测试效果吧。
变量
-
$secure_link链接检查的状态。具体值取决于所选的操作模式 -
$secure_link_expires请求中传递的链接的生命周期,仅用于 secure_link_md5 指令
安全链接测试(一)secure_link 与 secure_link_md5
好了,看完了配置指令,咱们就来看看怎么使用。首先看第一种方式,就是 secure_link 与 secure_link_md5
组合的方式。先添加以下的测试代码。
log_format securelink 'secure_link_expires=$secure_link_expires, secure_link=$secure_link';
server{
listen 8034;
location /securelink1/ {
access_log logs/34.securelink.log securelink;
alias html/;
secure_link $arg_md5,$arg_expires;
secure_link_md5 "$secure_link_expires$uri$remote_addr zyblog secret";
if ($secure_link = "") {
return 200 nosecure;
}
if ($secure_link = "0") {
return 200 timeexpire;
}
}
}
上面的日志记录,是为了看两个变量的变化情况。然后我们指定 secure_link 的值,分别是从 GET 获取到的 md5 参数和 expires
参数。expires 可以给个时间戳,我们给的是明天的一个时间点。secure_link_md5 我们设置的内容是通过
“过期时间+请求链接URI+IP地址+空格+zyblog+空格+secret” 这一个字符串进行加密的。
然后就是使用两个 if 指令进行判断,如果 secure_link 为空,表示安全验证没通过,如果 $secure_link 是 0
,表示过期了,分别通过 return 返回不同的内容。
然后咱们先测试一下啥参数都不带的。
➜ ~ curl 'http://192.168.56.88:8034/securelink1/'
nosecure
直接返回 nosecure 。再看下日志。
// 34.securelink.log
secure_link_expires=-, secure_link=-
两个变量都是空的。然后我们准备一下要加密的签名数据,根据 secure_link_md5 的设置,我们可以直接通过 Linux 的 openssl
工具进行加密,如果没有安装这个的话可以自己安装一下哦,或者使用 PHP 以及其它动态语言也是可以的,就是md5 之后再 base64 一下。
[root@localhost article.http.d]# echo -n '1663719873/securelink1/192.168.56.1 zyblog secret' | openssl md5 -binary | openssl base64 | tr +/ -_ | tr -d =
VEJ41JfqBbXXaGJRXWK3rw
1663719873 是我们一会要通过 expires 参数传过来的过期时间,现在用当前时间,后面我们才会测试过期的问题,在 secure_link
配置中逗号后面第二个参数我们放置的就是它,然后它就会到 $secure_link_expires 变量中。secure_link_md5
中第一个变量就是它,所以我们要拼接在最前面,然后是请求的地址,这里就是请求根目录,URI 就是 /securelink1/ ,然后就是客户端 IP
地址,我这里是 192.168.56.1,最后接上空格和固定的字符串,加密后的结果就是 VEJ41JfqBbXXaGJRXWK3rw
。然后发送请求时使用 GET 带上这两个参数吧。
curl 'http://192.168.56.88:8034/securelink1/?md5=VEJ41JfqBbXXaGJRXWK3rw&expires=1663719873'
是不是发现可以打开首页了?因为我们做了 alias ,所以就是直接打开 html 目录下的首页了。再看下日志。
// 34.securelink.log
secure_link_expires=1663719873, secure_link=1
两个值都取到了,secure_link 的值是 1 ,不符合 if 每个人的中的内容,不会直接 return 返回,正常向下执行。
secure_link_expires=1662769473, secure_link=1
接下来试试过期问题,先改造一下。
secure_link $arg_md5,1662769473;
secure_link_md5 "$uri$remote_addr zyblog secret";
这回我们让过期时间的设置不使用传递过来的参数了,而是一个固定值,这个值是比现在的时间稍微早一点的时间。然后 secure_link_md5 也改了下,不使用
secure_link_expires。
➜ ~ curl 'http://192.168.56.88:8034/securelink1/?md5=EzLUxfpwyLdp7bDv0m0l0Q'
timeexpire
查看日志,secure_link 被设置成了 0 ,而 secure_link_expires 则是我们 secure_link 中设置的那个值。
// 34.securelink.log
secure_link_expires=1662769473, secure_link=0
然后我们再将过期时间设置为比现在晚一点的时候,比如比当前时间多个几分钟。
secure_link $arg_md5,1663644527;
现在访问又正常了,从这里可以看出,过期时间是基于当前系统的时间值的,如果小于当前系统时间,就是过期的,如果大于当前系统时间,就是正常的。而如果将
$secure_link_expires 加入到 secure_link_md5 中一起加密的话,则是保证这个请求必须在 1
秒内到达。假设有代理或者黑客大佬中间拦截了请求,就会导致时间过期,而如果时间参数对不上加密内容,则会导致验证不通过。这里和我们之前讲过的接口签名 sign
是一样的概念。
时间参数最重要的作用,就是让签名产生变化,如果没有这个动态值,那么签名就会一直是一样的,这种签名有跟没有不就没啥区别了。
不过就像做接口签名一样,客户端和服务端如果时间不一致,就可能导致签名失败。一般有两种解决方式,一是对发来的时间参数判断,比如1分钟或几分钟内的都有效,二是每次接口请求都返回服务器的时间,让客户端保存一份,并以这个时间戳为基准进行计时。通常来说,第一种方式是我们用动态语言时常用的方式,第二种则可以应用在
Nginx 这个配置中。
对于接口签名不太了解的同学,可以查阅下相关的资料哦。一般都是通过 URI+请求参数排序+时间戳 这种加密形式进行接口签名的。
当然,我们也可以不使用过期时间,secure_link 不加过期时间参数就可以了。
secure_link $arg_md5;
secure_link_md5 "$uri$remote_addr zyblog secret";
然后对参数进行加密。
[root@localhost article.http.d]# echo -n '/securelink1/192.168.56.1 zyblog secret' | openssl md5 -binary | openssl base64 | tr +/ -_ | tr -d =
EzLUxfpwyLdp7bDv0m0l0Q
直接访问,可以正确获得访问结果。
curl 'http://192.168.56.88:8034/securelink1/?md5=EzLUxfpwyLdp7bDv0m0l0Q'
日志的内容如下。
secure_link_expires=-, secure_link=1
安全链接测试(二)secure_link_secret
第二种,secure_link_secret 的使用方法,还是先来准备测试代码吧。
location /securelink2/ {
access_log logs/34.securelink.log securelink;
alias html/;
secure_link_secret zyblog.com.cn;
if ($secure_link = "") {
return 200 nosecure;
}
rewrite ^ /$secure_link;
}
location / {
root html;
}
这段代码中,我们指定签名的 Key 是 zyblog.com.cn 。如果匹配不成功,就返回 nosecure
的内容,如果成功了,$secure_link 会变成签名内容之后的 URI 地址。也就是上面配置解释中 link 的部分。接着就通过 rewrite
重写到 link 地址。
先来看看直接访问的效果。
curl 'http://192.168.56.88:8034/securelink2/aaa'
nosecure
不出意外的返回 nosecure ,因为我们的验证没有通过,$secure_link 的值是空的,先做一个加密密钥过来吧,根据规则,直接拼接 aaa 和
zyblog.com.cn ,然后 md5 就可以了,这里不需要再 base64 了。
[root@localhost article.http.d]# echo -n 'aaazyblog.com.cn' | openssl md5 -hex
(stdin)= e09475846aa906796ef997b684eced07
获得密钥之后,加到 location 和 aaa 中间。
curl 'http://192.168.56.88:8034/securelink2/e09475846aa906796ef997b684eced07/aaa'
是不是可以正常访问啦,看看日志内容。
// 34.securelink.log
secure_link_expires=-, secure_link=aaa
secure_link 确实变成了密码后面的 URI 内容了。对于指定的文件也需要加密。
[root@localhost article.http.d]# echo -n 'tf2/2.htmlzyblog.com.cn' | openssl md5 -hex
(stdin)= 2fef203746d3684862e8d2607bfebc86
现在需要访问的是 tf2 目录下的 2.html 文件。
curl 'http://192.168.56.88:8034/securelink2/2fef203746d3684862e8d2607bfebc86/tf2/2.html'
也是可以正常访问的。这里需要注意的是,它仅能对非根的的路径进行安全连接保护。比如下面这样就不行。
curl 'http://192.168.56.88:8034/securelink2/xxxx/'
即使你是 “zyblog.com.cn” 或 “/zyblog.com.cn” 这样加密都不行,但要想直接访问可以直接指定文件名。
[root@localhost article.http.d]# echo -n 'index.htmlzyblog.com.cn' | openssl md5 -hex
(stdin)= 2a19ca1a01c0121c7bb6b4ecb8d109dc
这样就可以访问根目录下的 index.html 了。
curl 'http://192.168.56.88:8034/securelink2/2a19ca1a01c0121c7bb6b4ecb8d109dc/index.html'
范围分片
这里的范围分片,其实就是范围请求的意思,也就是 HTTP 中的那个 Range
请求头和响应头的作用。不过这里的配置不是针对客户端的,而是针对代理服务器的。它的命名是 ngx_http_slice_module
模块(1.9.8),是一个过滤器,用于将请求拆分为子请求,每个子请求返回一定范围的响应。过滤器提供更有效的大响应缓存。
它只有一个配置指令,并且不是包含在 Nginx 核心源码中的,需要通过 --with-http_slice_module 编译。
slice
设置切片的大小。
slice size;
默认 0 表示禁用将响应拆分为切片。请注意,过低的值可能会导致内存使用过多并打开大量文件。
为了让子请求返回所需的范围,应将 $slice_range 变量作为 Range 请求标头字段传递给代理服务器。如果启用了缓存,则应将
$slice_range 添加到缓存键中,并应启用具有 206 状态代码的响应的缓存。
变量
$slice_rangeHTTP字节范围格式的当前切片范围,例如bytes=0-1048575。
范围分片测试
这个测试需要借助反向代理,因为它主要是针对代理的子请求的嘛。所以我们添加如下配置。
# http
proxy_cache_path slicecache levels=1:2 keys_zone=slicecache:10m;
server{
………………
location ~ /slice(.*) {
slice 100;
proxy_cache slicecache;
proxy_cache_key $uri$is_args$args$slice_range;
proxy_set_header Range $slice_range;
proxy_cache_valid 200 206 10m;
proxy_pass http://127.0.0.1/$1?$args;
}
}
代理相关的配置就不多说了,主要就是做了个代理缓存。然后添加了 slice 指令,设置为 100 个字符。然后需要设置代理请求头的 Range 头,值直接就放
$slice_range 就好了。另外就是有效缓存响应码要把 206 加上。这些配置都是我们之前在学习代理时讲过的。
然后准备一个 PHP 文件,没什么特别的内容,就是获取 Range 请求头的内容,然后返回响应时响应为 206 状态码,并且添加 Content-Range
响应头。最后循环随机输出数据。
// vim /usr/local/nginx/html/fastcgi1/slice/1.php
if (isset ( $_SERVER ['HTTP_RANGE'] )) {
if (preg_match ( '/bytes=\h*(\d+)-(\d*)[\D.*]?/i', $_SERVER ['HTTP_RANGE'], $matches )) {
$begin = intval ( $matches [1] );
if (! empty ( $matches [2] )) {
$end = intval ( $matches [2] );
}
}
}
header ( 'HTTP/1.1 206 Partial Content' );
header ( "Content-Range: bytes $begin-$end/10000" );
foreach(range(0, 99) as $v){
echo rand(1, 9);
}
请求之后,我们去看 Proxy 缓存目录,会发现生成了很多缓存。这就是因为我们每次都只是请求 100 字节范围内的数据,所以每次请求的响应就只有 100
字节,总共会响应 1000 个字节,大概有 10 次子请求。这里只有 8 个目录,但是还有二级目录,总共生成的缓存文件应该是 10 个。
[root@localhost article.http.d]# ll /usr/local/nginx/slicecache/
total 0
drwx------ 3 www www 16 Sep 20 09:58 0
drwx------ 3 www www 16 Sep 20 09:58 1
drwx------ 4 www www 26 Sep 20 09:58 3
drwx------ 3 www www 16 Sep 20 09:58 4
drwx------ 3 www www 16 Sep 20 09:58 5
drwx------ 3 www www 16 Sep 20 09:58 a
drwx------ 4 www www 26 Sep 20 09:58 c
drwx------ 3 www www 16 Sep 20 09:58 f
随便查看一个目录下面的缓存文件,内容就是 100 个字符。
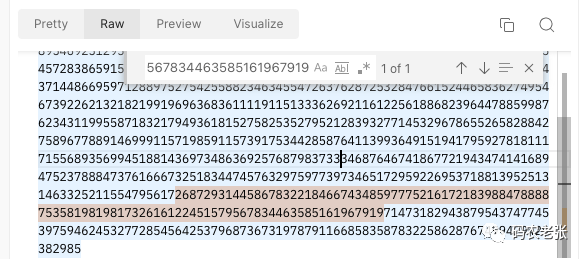
[root@localhost article.http.d]# cat /usr/local/nginx/slicecache/3/25/2c87b23befe050b716282f3280b5c253
��)c��������-)c
R
KEY: /slice/fastcgi1/slice/1.phpbytes=800-899
HTTP/1.1 206 Partial Content
Server: nginx/1.23.0
Date: Tue, 20 Sep 2022 01:58:05 GMT
Content-Type: text/html; charset=UTF-8
Connection: close
X-Powered-By: PHP/7.2.24
Content-Range: bytes 800-899/1000
2687293144586783221846674348597775216172183988478888753581981981732616122451579567834463585161967919
这 100 个字符在最终整体返回的数据中肯定是存在的,是整体响应内容的连续一部分。
请求分流
最后我们再来看到的是请求分流的功能。它还是比较有意思的,能够根据一个变量内容,进行 Hash 分配到指定的内容,有点类似于之前学习过的 Redis
的分槽的效果。这个模块的全名是 ngx_http_split_clients_module 模块,用于创建适用于 A/B
测试的变量,也称为拆分测试。它直接包含在 Nginx 核心源码中,直接就可以使用,也只有一个配置指令。
split_clients
为 A/B 测试创建一个变量。
split_clients string $variable { ... }
只能在 http 模块下进行配置。使用 MurmurHash2 对原始字符串的值进行散列。和 Redis Cluster 中的 槽solt 类似,从 0 到
4294967295 的范围内,根据配置的结果,会让散列值落在一定的范围内。后面我们看例子再详细说明。
请求分流测试
上面的内容要是没看懂,我们就直接测试效果。
# http
split_clients "${arg_a}zyblog" $variant {
50% aaa.html;
20% a.txt;
* index.html;
}
server {
# ………………
location /splitclient/ {
alias html/;
index $variant;
}
}
在 split_clients 配置中,我们定义了 $arg_a 拼接 zyblog 字符串做为 Hash 值,也就说,根据我们传递过来的 GET 参数
a 的不同,就会有不同的哈希结果。上面配置的意思是,50% 代表散列结果为 0-2147483647 范围内的结果,就设置 $variant 为
aaa.html ;20% 代表散列值在 2147483648-3006477107 范围内的结果,$variant 为 a.txt ;剩下如果落在
3006477108 - 4294967295 范围内,则将变量的值设置为 index.html 。
这一块真的和 Redis Cluster 中相关的概念非常类似,如果不记得了,可以回到 Redis进阶:分布式部署RedisCluster(一)
这篇文章中,看一下 槽Slot 相关的说明。接下来就是测试了,不停地修改 a 参数的值就可以看到效果啦。
➜ ~ curl 'http://192.168.56.88:8034//splitclient/'
111222333444
<h1>aaa</h1>
➜ ~ curl 'http://192.168.56.88:8034//splitclient/?a=1'
this is a.txt. 111
➜ ~ curl 'http://192.168.56.88:8034//splitclient/?a=2'
111222333444
<h1>aaa</h1>
➜ ~ curl 'http://192.168.56.88:8034//splitclient/?a=3'
this is a.txt. 111
➜ ~ curl 'http://192.168.56.88:8034//splitclient/?a=4'
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!123123</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
总结
安全链接这个,是不是感觉有点意思啊,虽说大部分情况下我们会在动态语言中做接口签名,但静态资源有需要的时候完全也可以通过 Nginx
来实现嘛。这样不管动态还是静态资源,都是有请求限制的啦。
范围分片可能我们平常用得不多,大多数情况下可能是对一些下载文件做断点续传时会用到。
请求分流这个,其实可以实现更多的功能。因为我们可以设置变量,就可以将这个变量应用到 location、if、rewrite
等等各种配置中去,甚至分开记录日志都可以。非常强大,也非常灵活,期待各路高手大佬的开发咯,有好的案例也欢迎留言分享哦。
参考文档:
http://nginx.org/en/docs/http/ngx_http_secure_link_module.html
http://nginx.org/en/docs/http/ngx_http_slice_module.html
http://nginx.org/en/docs/http/ngx_http_split_clients_module.html
学习计划安排

我一共划分了六个阶段,但并不是说你得学完全部才能上手工作,对于一些初级岗位,学到第三四个阶段就足矣~
这里我整合并且整理成了一份【282G】的网络安全从零基础入门到进阶资料包,需要的小伙伴可以扫描下方优快云官方合作二维码免费领取哦,无偿分享!!!
如果你对网络安全入门感兴趣,那么你需要的话可以
点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!
①网络安全学习路线
②上百份渗透测试电子书
③安全攻防357页笔记
④50份安全攻防面试指南
⑤安全红队渗透工具包
⑥HW护网行动经验总结
⑦100个漏洞实战案例
⑧安全大厂内部视频资源
⑨历年CTF夺旗赛题解析


















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









