







 本文详细介绍了SQLite数据库中的SQL语句高级用法,包括函数和聚合、分组与过滤、约束、联结表、视图、触发器以及查询优化中的索引。通过实例讲解了如何创建和使用主键、唯一约束、检查约束,以及如何创建触发器和索引以提升查询效率。同时,给出了多道练习题,帮助读者巩固学习。
本文详细介绍了SQLite数据库中的SQL语句高级用法,包括函数和聚合、分组与过滤、约束、联结表、视图、触发器以及查询优化中的索引。通过实例讲解了如何创建和使用主键、唯一约束、检查约束,以及如何创建触发器和索引以提升查询效率。同时,给出了多道练习题,帮助读者巩固学习。
接着上一篇SQL数据库。
1.函数和聚合
SQL语句支持利用函数来处理数据,函数一般是在数据上执行的,它给数据的转换和处理提供了方便。
常用的文本处理函数:
length() 返回字符串的长度
lower() 将字符串转换为小写
upper() 将字符串转换为大写
select * upper(addr) from person; //保存大写地址
select id,length(name) from person; //保存名字长度
2.常用的聚集函数
使用聚集函数,用于检索数据,以便分析和生成报表
avg() 返回某列的平均值
count() 返回某列的行数
max() 返回某列的最大值
min() 返回某列的最小值
sum() 返回某列值之和
select avg(score) from person; //保存平均分数
select id,name,max(score) from person //保存最大分数
select sum(score) from person; //保存分数总和
3.数据分组group by
分组数据,以便能汇总表内容的子集,常和聚集函数搭配使用。例如查询每个班级中的人数、平均分等。
语法:select 列名1 [,列名2,...] from 表名 group by 列名
例如:select class,count(*) from person group by class; //按照班级保存班级对应的人数
4.过滤分组 having
除了能用group by分组数据外,还可以包括哪些分组,排除哪些分组。例如:查看班级平均分大于90的班级。可以通过having实现。
语法:select 函数名(列名1)[,列名2,...] from 表名 group by 列名 having 函数名 限制值
eg: select class,avg(score) from person group by class havinig avg(score) >= 90; //按照班级保存平均分大于等于90的班级和对应的平均分
5.约束
管理如何插入或处理数据库数据的规则
常用约束分类:主键、唯一约束、检查约束
主键:
惟一的标识一行(一张表中只能有一个主键);
主键应当是对用户没有意义的(常用于索引);
永远不要更新主键,否则违反对用户没有意义原则;
主键不应包含动态变化的数据,如时间戳、创建时间列、修改时间列等;
主键应当有计算机自动生成(保证唯一性);
语法:create table 表名称(列名称1 数据类型 primary key,列名称2 数据类型,......,列名称n 数据类型);
唯一约束:
用来保证一个列(或一组列)中数据唯一,类似于主键,但跟主键有区别;
表可包含多个唯一约束,但只允许一个主键;
唯一约束列可修改或更新;
创建表时,通过unique来设置
语法:create table 表名(列名称1 数据类型 unique,列名称2 数据类型 unique,...]);
eg:create table person(id integer primary key,name text unique);
检查约束:
用来保证一个列(或一组列)中的数据满足一组指定的条件。
指定范围,检查最大或最小范围,通过check实现
语法:create table 表名 (列名 数据类型 check (判断语句));
eg:create table person(id integer primary key,name text unique,age integer check(age>0 and age<100));
6.联结表(多表操作)
保存数据时往往不会将所有数据保存在一个表中,而是在多个表中存储,联结表就是从多个表中查询数据。
在一个表中不利于分解数据,也容易使相同数据出现多次,浪费存储空间;使用联结表查看各个数据更直观,这使得在处理数据时更简单。
有如下两个表:分数表和信息表
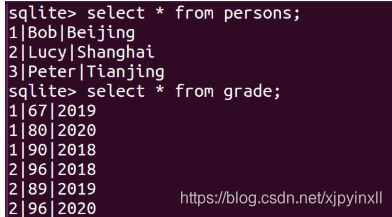
链接分数和信息表:
select person.id,name,addr,score,year from person,grade where person.id=grade.id; //person.id/grade.id这样写不会报二义性的错误
7.视图
视图不包含数据,因此在每次使用视图时,实际上都必须执行查询语句,从返回结果信息中再检索.视图与表一样,必须唯一命名(通过.tables和.schema查看)
语法:create view 视图名 as 语句;
eg:create view personandgrade as select person.id,name,addr,score,year from person,grade where perosn.id=grade.id; //生成按照id保存两个表信息的视图
删除视图:
语法:drop view 视图名;
总结:
1、视图不包含数据,因此在每次使用视图时,实际上都必须执行查询语句;
2、视图相当于创建视图的时候 as后面SQL语句查询得到的结果集合;
3、从返回结果信息(视图)中再检索视图与表一样。
8.触发器
SQLite的触发器是数据库的回调函数,它会在指定的数据库事件发生时自动执行调用
1、只有每当执行delete,insert或update操作时,才会触发,并执行指定的一条或多条SQL语句;
2、触发器常用于保证数据一致,以及每当更新或删除表时,将记录写入日志表。
创建触发器:
语法:create trigger 触发器名 [before|after] [insert|update|delete] on 表名 begin 语句; end;
eg:create trigger tg_delete after delete on persons begin delete from grade where id=old.id; end; //当执行:delete from persons where id=1;语句时,事件触发,执行 begin 与 end 之间的 SQL 语句(即回调函数)
注意:
old.id 等价于 persons.id,但此处不能写 persons.id,old.id 代表删除行的
id(id 代表两个表的关联列)
删除:drop trigger 触发器名;
9.查询优化- 索引
数据库中往往存储了大量的数据,普通查询的默认方法是调用顺序扫描。例如这样一个查询:select * from table1 where id=10000;如果没有索引,必须遍历整个表,直到 ID 等于 10000 的这一行被找到为止。为了提高查询的效率,可以使用索引。
什么是索引?
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
索引就是恰当的排序,经过某种算法优化,使查找次数要少的多的多。
缺点:
索引数据可能要占用大量的存储空间,因此并非所有数据都适合索引;
索引改善检索操作的性能,但降低了数据插入、修改和删除的性能。
创建索引:create index 索引名 on 表名(列名);
查看索引:.indices
删除索引:drop index 索引名;
eg:create index person_id_index on person(id); //id号创建索引
eg:create index person_id_name_index on person(id,name); //id号和name值创建索引
索引创建注意:
1、在作为主键的列上;
2、在经常需要排序的列上创建索引;
3、在经常使用在 WHERE 子句中的列上面创建索引,加快条件的判断速度。
练习

1、创建 persons 表,id 设置为主键,表的格式(id integer primary key, name text, addr text, class text)
2、创建 grade 表,设置约束条件(score>0),表的格式(id integer, score integer, year text)
3、追加相应的数据,见下页
4、打印所有学生的信息:包括 name,addr,class,score,year
5、将打印所以学生信息的语句,创建视图 PersonsGrade,方便后面使用
6、查看最高分数是多少?
7、查看每个班的平均分,以及对应的班级名称和班级人数
8、在 persons 表中 id 列创建一个索引 persons_id_index
9、查看 lucy 在 2013 年的成绩
10、bob 要退学,必须要删除 bob 所有的信息(包括成绩单),通过设置触发器,自动删除 bob 相关的所有数据,
设置触发器 tg_delete
11、执行删除 bob 的操作
12、查看所有人的信息,确定是否执行了删除操作
想要检验可以找小编要答案,加油,朋友!

















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









