




坦白地说,你是不是觉得 Transformer 已经被研究透了?
经过了无数轮的验证与优化,Transformer 的结果看似已经达到了非常稳定的最佳状态,想做出颠覆 Transformer 的结构创新,几乎不太可能了。。
我之前也这么觉得,直到最近看到了一篇 ICML 2025 的论文,没想到又让 Transformer 老树开花了!
这篇论文思路很有意思,没有去卷那些主流的注意力机制,而是独辟蹊径,把“手术刀”对准了 Transformer 内部一个我们习以为常、甚至有些忽略的组件—残差连接(Residual Connection)。
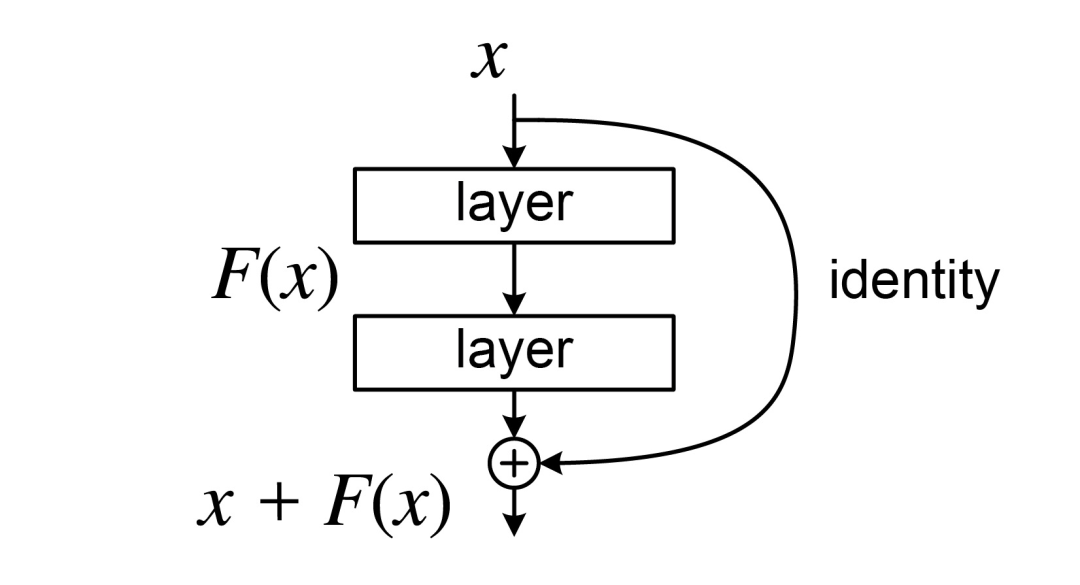
自 2015 年由何恺明团队提出以来,残差连接凭借其有效缓解梯度消失的超能力,几乎是深度网络的标配。没有它,今天的 Transformer 很难稳稳当当地堆到几十层,更别提像 GPT-4 一样动辄上百层了。
不过,任何技术都有它的适用边界。这个曾经的功臣,在今天动辄上百层的深度大模型里,也开始显露出它的瓶颈,成了新的信息“堵塞源头”:
一方面,信息在逐层传递中损耗严重。 随着网络加深,各层特征越来越像(即“表示坍塌”),导致深层网络学不到新东西,白白浪费了参数和算力。
另一方面,单一的“残差流”带宽有限。 Transformer 所有跨层信息都挤在这条道上,当模型需要进行复杂的上下文学习时,这条“单行道”就显得捉襟见肘了。
而这篇 ICML 论文,就是冲着解决这个问题来的。
有意思的是,瞄准这个问题的,还是我们去年的老朋友——彩云科技与北京邮电大学的研究团队。他们设计了一套全新的多路动态密集连接(Multiway Dynamic Dense Connection, MUDD),目标就是给残差连接这个“老基建”来一次高效的改造。
熟悉我的老粉可能还记得,去年我就和大家分享过这个团队在 ICML 2024 上的杰作 DCFormer(哦,所
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









