




 本文介绍了如何通过Chain-of-Thought、CoT-Self-Consistency、Tree-of-Thoughts、Graph-of-Thoughts、Algorithm-of-Thoughts等方法来引导大语言模型提供更恰当的答案,这些框架模仿人类思维过程,提升模型在决策和复杂问题处理上的表现。
本文介绍了如何通过Chain-of-Thought、CoT-Self-Consistency、Tree-of-Thoughts、Graph-of-Thoughts、Algorithm-of-Thoughts等方法来引导大语言模型提供更恰当的答案,这些框架模仿人类思维过程,提升模型在决策和复杂问题处理上的表现。
夕小瑶科技说 原创
编译 | 谢年年
大语言模型LLM被视为一个巨大的知识库,它可以根据你提出问题或陈述的方式来提供答案。就像人类可能会根据问题的不同提供不同的答案一样,LLM也可以根据输入的不同给出不同的答案。因此,你的问题或陈述方式就显得非常重要。
如何引导大语言模型给出更恰当的答案,是最近研究的热点。经常用到的方法如让大模型扮演一个角色,或是给出几个示例都可以引导大模型给出更好的答案。除此之外还有一直以来很火热的思维链的方法也是值得尝试的。
在这篇文章中,我们总结了各种增强LLM推理的提示工程框架,包括:
-
Chain-of-Thought[1]
-
Chain-of-Thought-Self-Consistency[2]
-
Tree-of-Thoughts[3]
-
Graph-of-Thoughts[4]
-
Algorithm-of-Thoughts[5]
-
Skeleton-of-Thought[6]
-
Program-of-Thoughts[7]
一起来看看吧~
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
Chain-of-Thought思维链
与其直接输出答案,不如为语言模型提供中间推理示例来指导其响应。
思维链(CoT) 被认为最具开拓性和影响力的提示工程技术之一,它可以增强大型语言模型在决策过程中的表现。
与传统的提示方法强调直接的输入和输出互动不同,CoT迫使模型将推理过程划分为中间步骤。这种方法类似于人类的认知过程,将复杂的挑战分解为更小、更易于管理的部分。
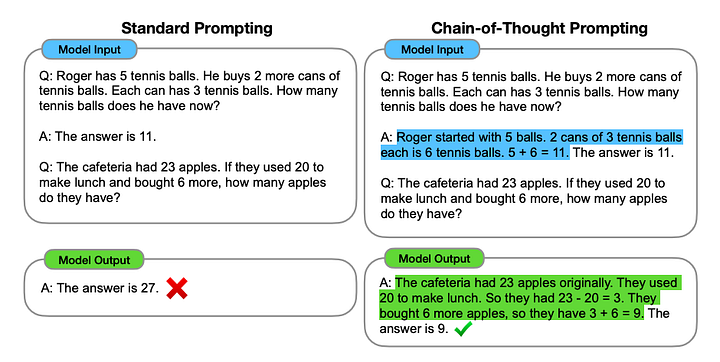
▲Chain-of-Thought Prompting, source: Wei et al. (2022)
如上图中的例子,对于一个数学问题:“罗杰拥有5个网球,随后购买了2罐网球,每个罐含有3个球。他现在拥有多少个网球?”我们可以通过逐步分析来解答这个问题。
-
首先
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









