







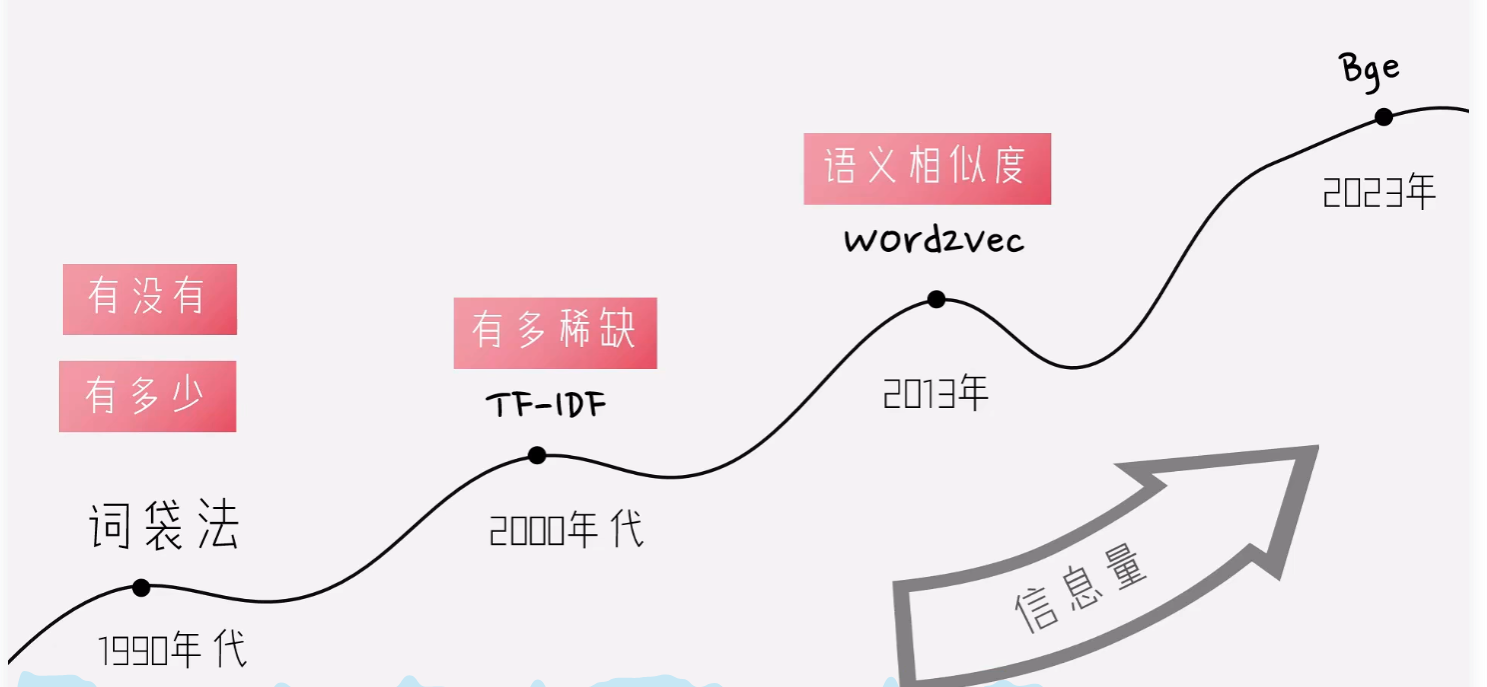
演进的过程
词袋法
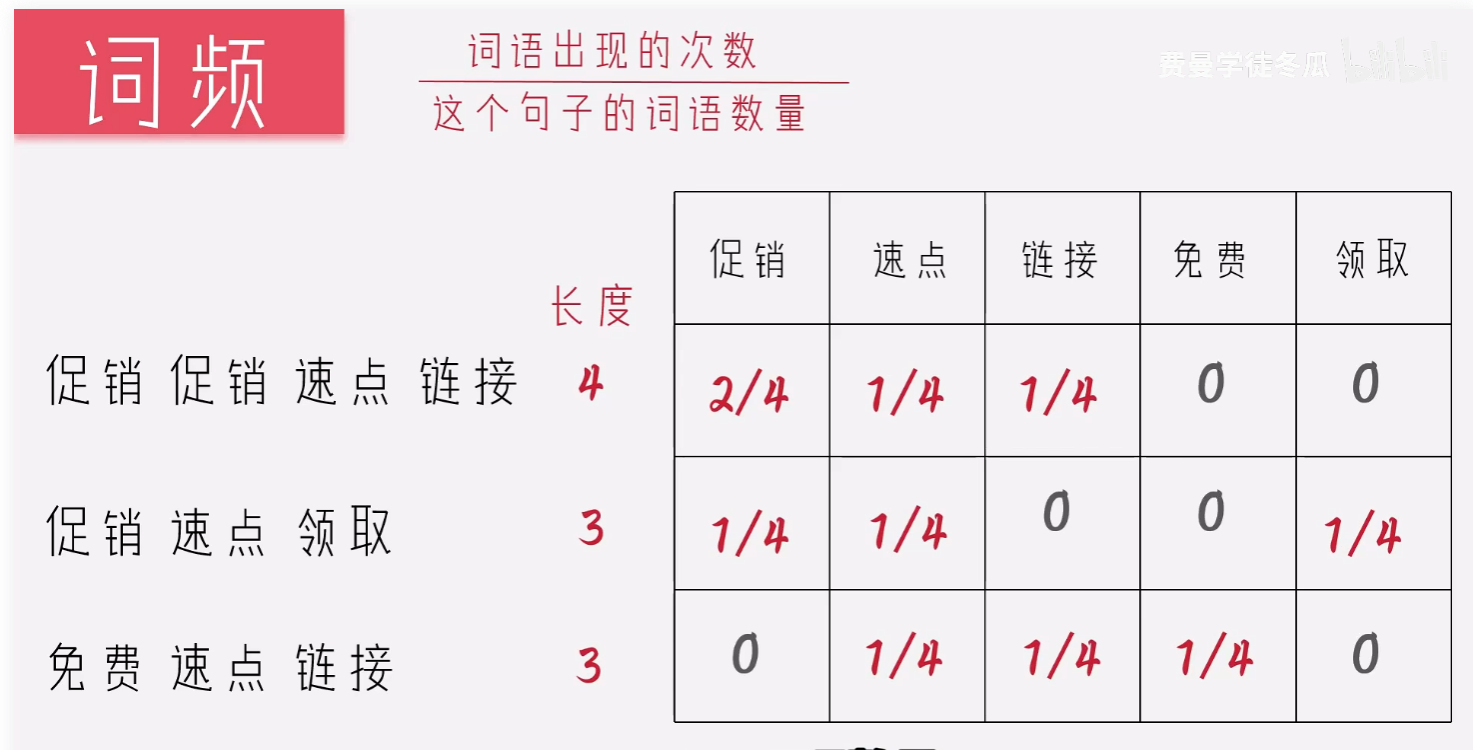
在这个示例中,我们有三个不同的句子:
句子1:促销 促销 速点 链接
句子2:促销 速点 领取
句子3:免费 速点 链接
首先,从这些句子中提取所有唯一的单词,构建一个词汇表:
词汇表:[“促销”, “速点”, “链接”, “免费”, “领取”]
然后,对每个句子进行向量化,统计其中的每个单词是否在词汇表中出现。这里采用的是 0 或 1 的方式(即单词是否出现)。
句子向量化结果以表格形式展示,数值1表示词汇出现,0表示未出现:
| 文档编号 | 句子内容 | 促销 | 速点 | 链接 | 免费 | 领取 |
|---|---|---|---|---|---|---|
| 1 | 促销 促销 速点 链接 | 1 | 1 | 1 | 0 | 0 |
| 2 | 促销 速点 领取 | 1 | 1 | 0 | 0 | 1 |
| 3 | 免费 速点 链接 | 0 | 1 | 1 | 1 | 0 |
文本向量化的过程分为两个阶段:
词汇表构建
遍历所有句子,提取不重复的单词形成词汇表。词汇表定义向量维度,每个维度对应一个特定单词。
句子向量化
对每个句子生成二进制向量,维度与词汇表一致。若句子包含词汇表中的单词,对应维度置1,否则置0。重复出现的单词不重复计数。
TF-ID
稀有性
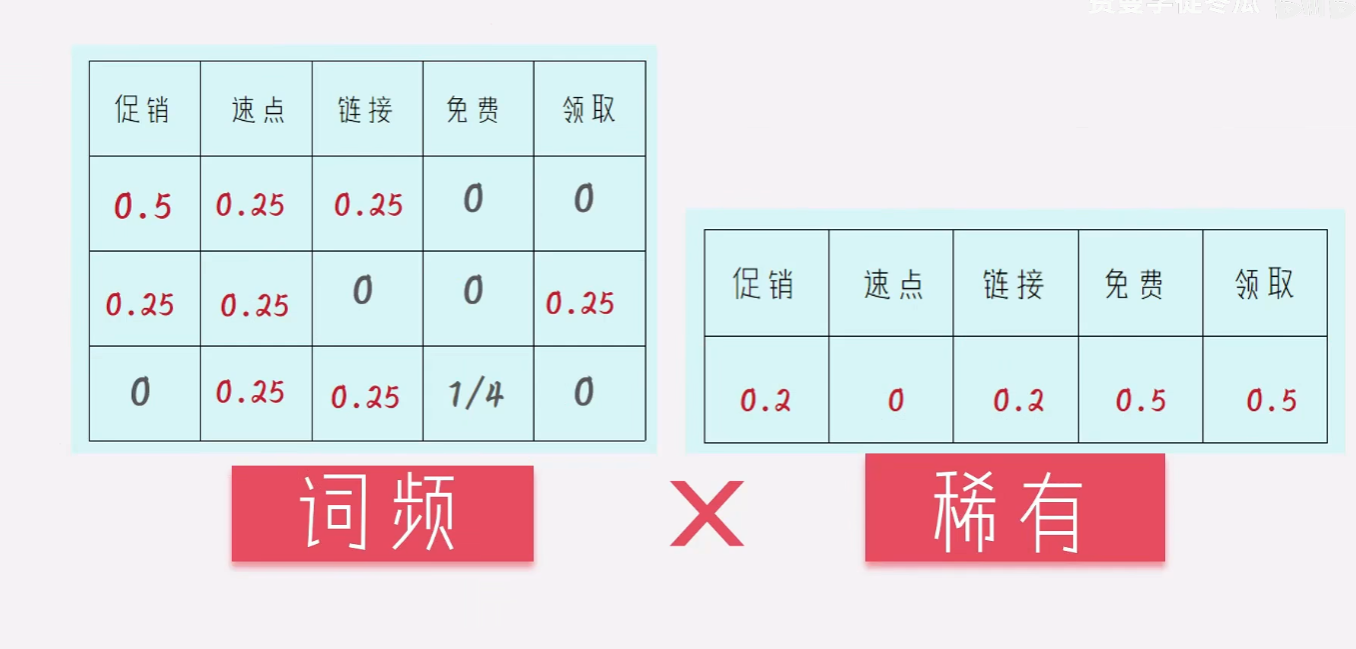
词袋法的问题是:没有考虑不同单词的稀有性。例如下面的例子:

的 字出现的最多,如果使用词袋法,的 字就成为了这个句子的标志,这显然不合理。所以我们需要引入稀缺性的衡量。

为了统计稀缺性,我们要全局统计。如果我们有100篇文章,而一个单词例如“春晚”只在1篇文章里出现过,那么这个词就非常的稀有。可以表示为100/1

很显然,出现的越少,越稀有。

归一化
还有用频次不太公平,不能说你说的越多就越有理。哈哈,所以我们做一个归一化的处理,让每个句子里面的各个单词的频率之和都是1,达到公平的效果。
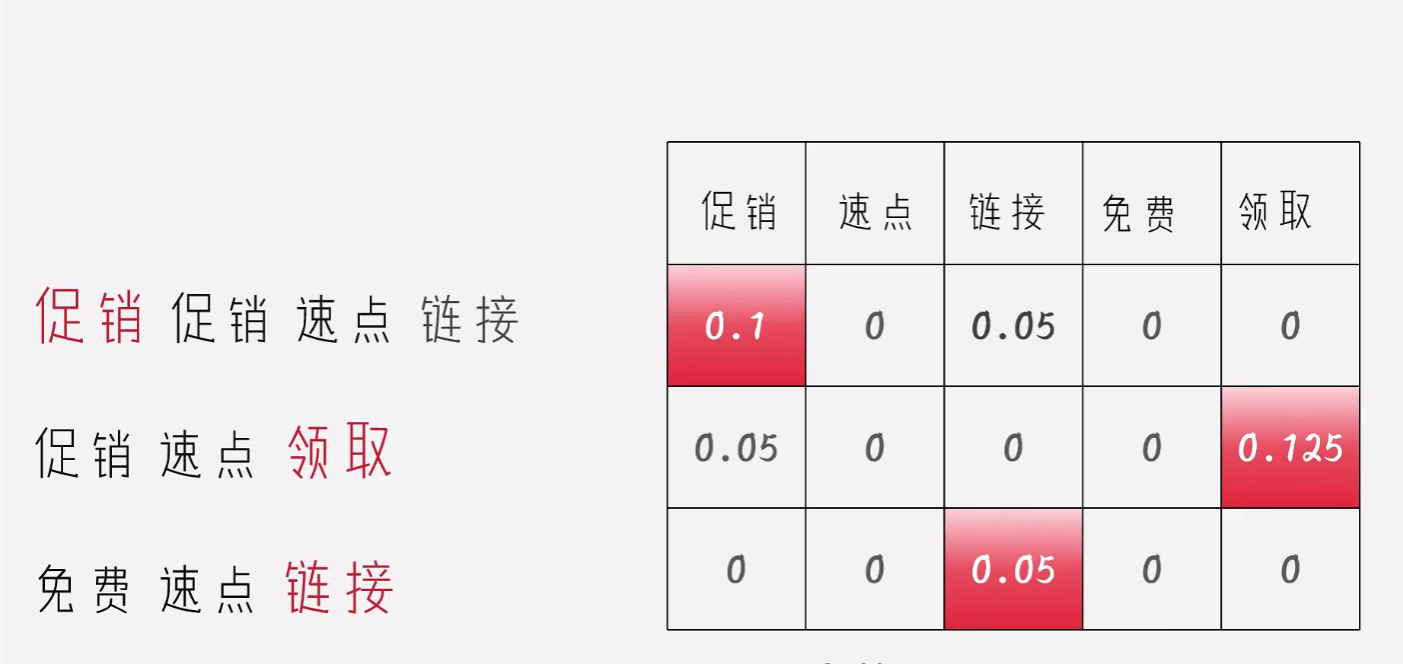
将二者合二为一
这样我们可以选取每个句子里面最大的元素,表征我这句话。
Word2Vec
但是TF-ID还是有一个问题,无法捕捉语义的相似性。
这个电影很好!
这个电影很棒!
从语义上讲,这两句话是一个意思,但是TF-ID方法无法捕捉到这种相似性。那么怎样捕捉相似性呢?Google提出了Word2Vec,他是基于全部所有的语料,训练一个神经网络。这个网络是根据前后两个单词预测中间的单词。
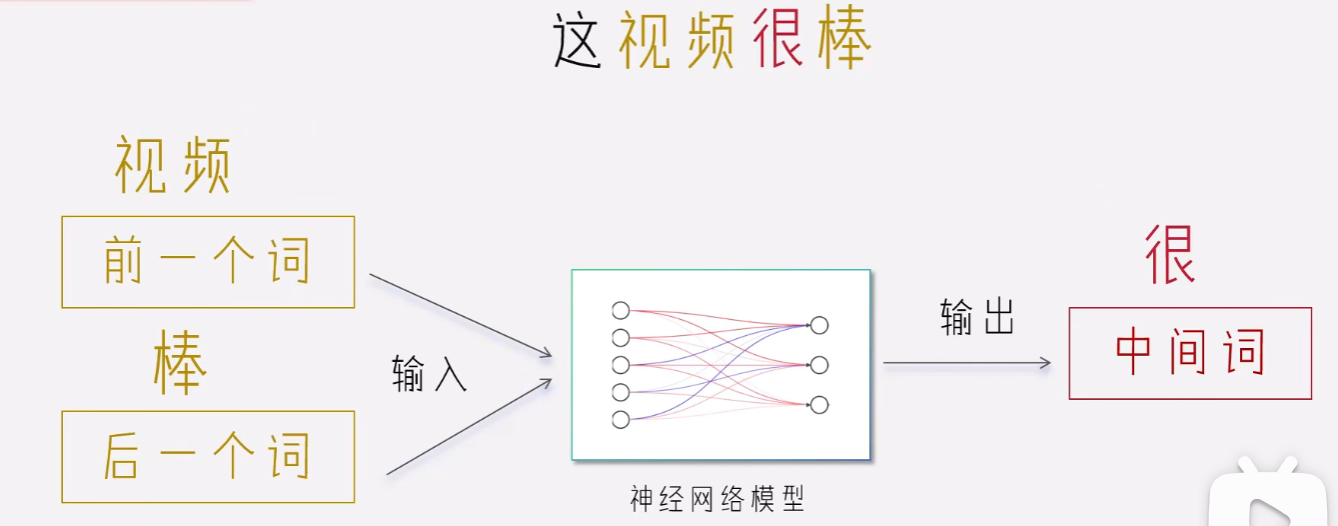
具体步骤:
一开始我们先随意的初始化每个单词的向量表示
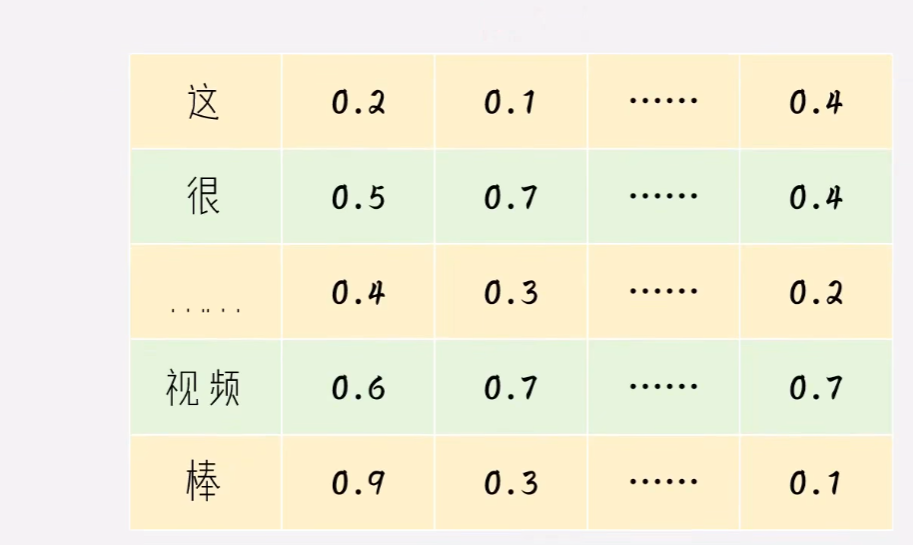
参数的前向传播
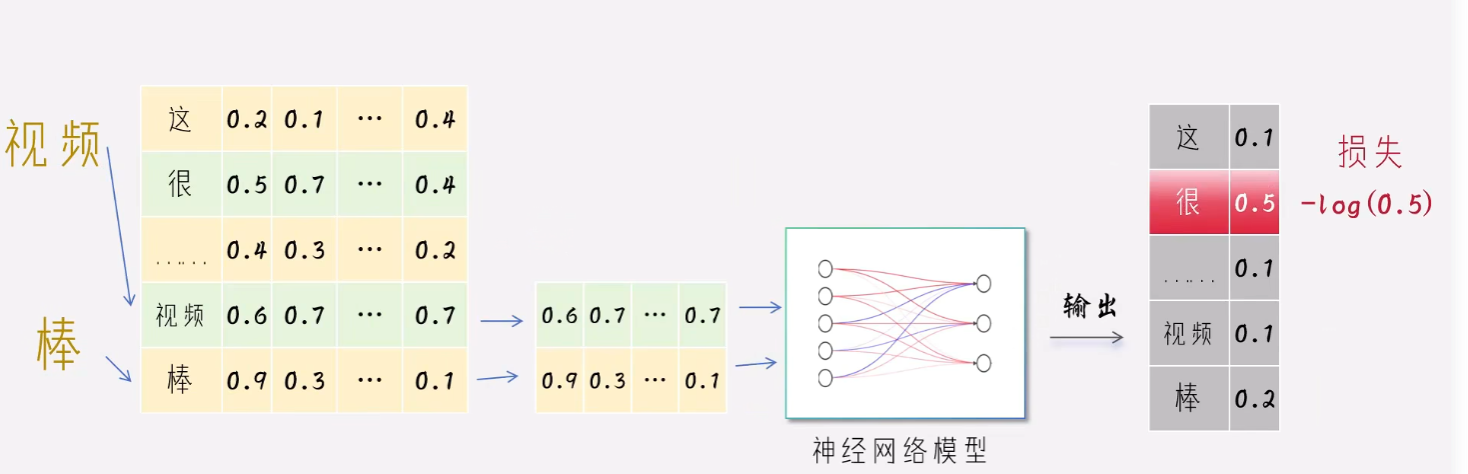
Word2Vec的底层逻辑,如果我周围的朋友跟你周围的朋友都一致,那么很大概率咱俩的爱好相似。我们还可以拿出来几个例子做比对,发现葡萄跟香蕉的相似度高很多,说明词向量捕捉到了我们的核心语义。

BGE
以上的方法都没有考虑词的顺序,例如:

没有考虑一次多义的情况,因为词表是预先定死的,没有灵活性。

说明我们需要根据语境动态的计算词向量。
这个时候我们想到了transformer,他的注意力机制,可以帮助我们根据上下文语境动态的判断语义。
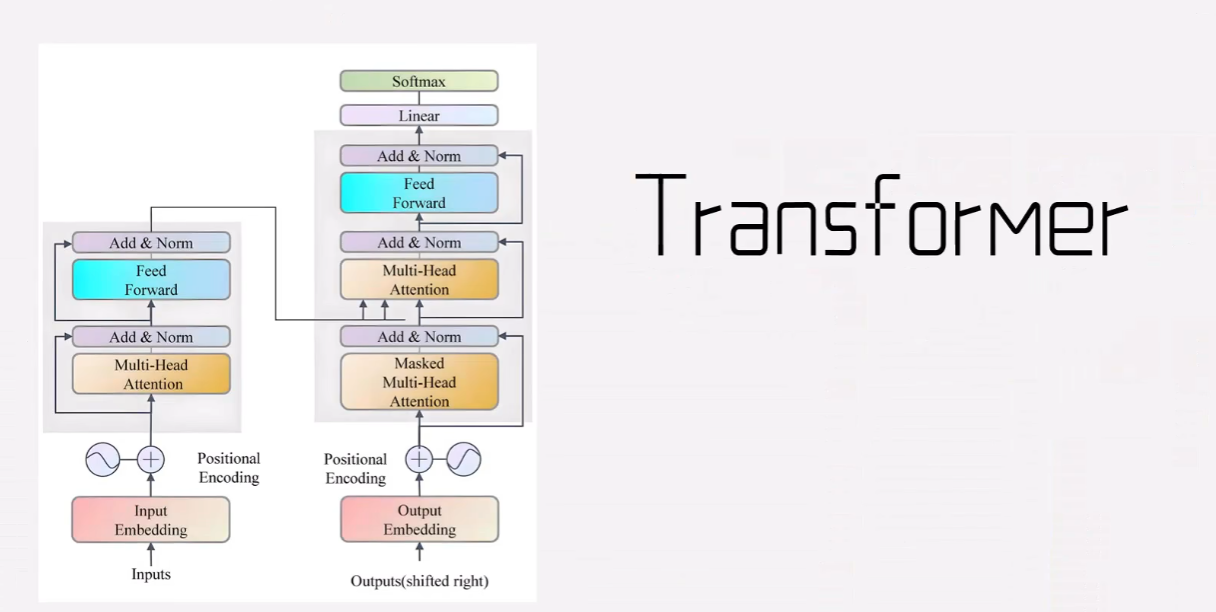
里面的对比学习是核心概念。我们可以使用bert作为我们的训练网络。把我们的一组样本输入给模型。
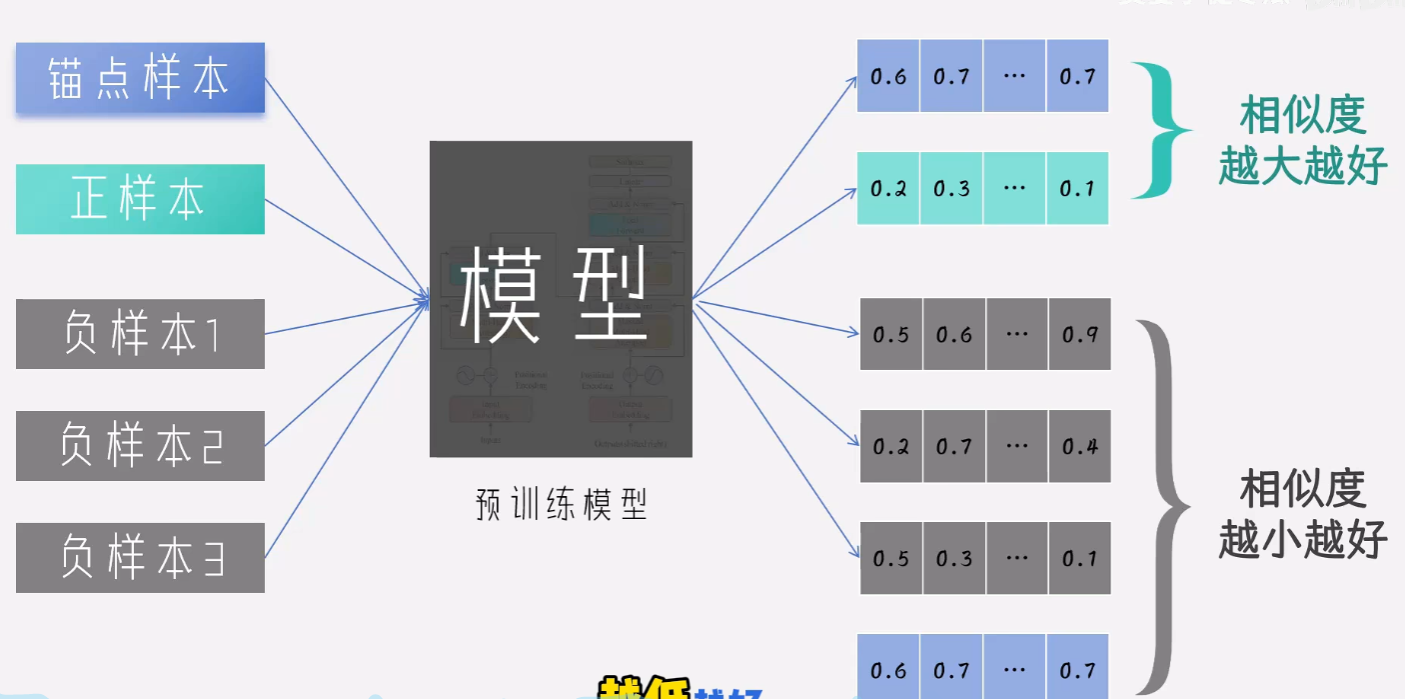
我们的损失函数如下:

反向传播,直到模型收敛。
最终我们会综合 词表+模型 就构成我们的新的词向量的表达。
怎样提高BGE的准确率呢?
关键在于样本数据的质量。

硬正样本:形式上不一样,但是语义一样。
硬负样本:形式上一样,但是语义不同。
比如:我一个叫xxx的朋友问。其实本质是我自己在问。。概括一下就是尽量的给模型上强度。
概括一下BGE

总结
| 方法 | 信息量表达 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 词袋法 | 有多少这个词 | 简单易实现 | 忽略稀有性和语义 | 垃圾邮件分类 |
| TF-IDF | 有多稀缺 | 考虑词频和稀有性 | 无语义信息 | 关键词提取 |
| Word2Vec | 文本语义 | 捕捉词间关系 | 不考虑词序和一词多义 | 语义搜索 |
| BGE | 语境化语义 | 动态生成上下文向量 | 训练复杂 | RAG等 |
视频讲解:https://www.bilibili.com/video/BV1CWV6zKEBn/?spm_id_from=333.1387.0.0&vd_source=82dc2acb60a90c43a2ac0d4023a2cd34
后续RAG重点期待:
https://www.bilibili.com/video/BV1hj5DzyE5d/?spm_id_from=333.1387.upload.video_card.click&vd_source=82dc2acb60a90c43a2ac0d4023a2cd34

















 4116
4116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









