







学过python的都知道,python的encode,decode里面有一些坑,掉进去后比较难爬出来。正好这段时间想总结一下这些坑,我会写2-3篇文章来介绍我对这些坑的理解。既然是个人理解,那很可能有些考虑不对的地方。因此如果大家自认为有更准确的理解,也希望能相互交流,共同学习,一起进步!另,文章中引用的文献,我都做了说明,也都注明了出处,以方便大家查阅。
文章比较长,基本是我一手敲下来的来
一,str 和 unicode
1) str 和 unicode 都是basestring的子类。
str典型编码类型:gbk,utf8; 表现形式:\xc4\xe3\xba\xc3。若是你看到类似于\xc4\xe3这种类型的编码,你首先要搞清楚,这个应该是中文编码经过gbk或utf8或其他类型的编码(总归不是unicode编码),至于到底是gbk还是utf8,不知道!而看到类似于\u4f60,就需要明白,这个是中文的unicode编码或者说是unicode表示,未经具体的utf8或gbk编码
2) str是经过编码的(采用何种编码取决于你的python编辑器,典型的如gbk, utf8。如笔者在cmd中默认为gbk编码),典型形式:\xc4\xe3。
3) unicode 没有经过编码。这里可以认为是有一个“统一世界”,在这个世界里,所有人类世界中的字符(如英文字符,中文字符,阿拉伯字符,希腊字符等等)都有一个统一的代号。典型形式:\u4f60。
4) str是字节串,表现形式 ” ” 或’ ’ 。是unicode经过encode编码后的字节所组成;
>>> s1="你好"
>>> s1
'\xc4\xe3\xba\xc3'
>>> len(s1)
4
>>> s2="hello" #注意,后面“补充解释”会讲到
>>> s2
'hello'
>>> len(s2)
5
而unicode才是真正的字符串,表现形式为u” ”
u1=u"你好"
>>> u1
u'\u4f60\u597d'
>>> len(u1)
2
>>> u2=u'hello' #注意,后面“补充解释”会讲到
>>> u2
u'hello'
>>> len(u2)
5
根据上面的四点,这里要补充解释几个方面
str和unicode的典型表形式,为何他们长成这个样子。
先说unicode。“unicode目前普遍采用的是UCS-2标准,它用两个字节来表示(这里说“表示”,而不是“编码”,因为我觉得这样更加准确)一个字符,故UCS-2最多只能表示65536个字符。汉字简体繁体加起来超过了7万个,但是UCS-2最多只能表示65535个字符,故肯定有部分汉字是UCS-2编码无法表示的,UCS-2的处理办法是是排除一些几乎不用的汉字。另外,为了表示所有的汉字,unicode有UCS-4编码规范,即用四个字节来表示字符串”(——百度百科)。
就拿\u4f60来说,它是中文“你”的UCS-2表示。\u 表示是unicode,4f60是用十六进制表示的两个字节。
因此,今后我们碰到类似“\u—-”这种东东,我们要形成的条件反射是:首先它未经过编码,它只是“某个字符”在统一世界一个统一代码表示,它完全等同于“某个字符”。它是真正的“字符串”。
再说具体的编码形式,如“utf8” 和 “gbk”。
无论是utf8和gbk,他们所做的工作都是把unicode字符进行编码,只是编码的规则不同。从表象来看,他们都是表现为字节串的形式。
如中文“你”(unicode为“\u4f60”)的utf编码为: “\xe4\xbd\xa0”;而gbk的编码为:“\xc4\xe3”。他们长得差不多,因此如果你看到了这种“\x–\x–\x–\x–\x–\x–”,我们要形成的条件反射是:首先它是某种编码,它是“字节串”,我们无法肯定它到底是哪种编码(python提供了判断这种字节串可能是哪种编码方式的API:chardet(),注意判断的结果只是可能是某种编码,并告知我们这种可能性有多大)。
UTF-8和unicode的关系
utf-8只是unicode的一种具体的实现方式。utf8是针对unicode变长编码设计的一种前缀码,根据前缀可判断是几个字节表示一个字符,如下图:

如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
比如”严”的unicode是4E25(100111000100101),4E25处在第三行的范围内(0000 0800-0000 FFFF),因此”严”的UTF-8编码需要三个字节,即格式是”1110xxxx 10xxxxxx 10xxxxxx”。然后,从”严”的最后一个二进制位开始,依次从后向前填入格式中的x,高位补0,得到”严”的UTF-8编码是”11100100 10111000 10100101”。
可以发现:对于0x00-0x7F之间的字符,十进制范围是0–127,UTF-8编码与ASCII编码完全相同。可以得到进一步的结论,由于ASCII是计算机发展史上最早的编码规范,它之后所发展的一些编码规范,典型如utf-8,gb2312等都完全兼容ASCII码。
解释第四点4)中的举例。中文、英文在unicode和gbk的表现形式
先拿例子说话:(在cmd中,编码格式为gbk)
英文:
>>> u"hello"
u'hello'
>>> "hello"
'hello'
>>> u"hello".encode('gbk')
'hello'
中文
>>> u"你好"
u'\u4f60\u597d'
>>> "你好"
'\xc4\xe3\xba\xc3'
>>> u"你好".encode('gbk')
'\xc4\xe3\xba\xc3'
不知道你看了这几个例子有什么想法。怎样理解例子中发生的一切
我说说我自己的理解。先解释一下>>> “hello”,发生了什么,这种实质上是调用的是repr(),它告诉我们该字符在python中的存放方式。(区别 >>>print “hello”, print调用的是str( ), 它实质上在输出的时候有个“编码的动作”,自己查资料吧)
我们发现是英文时,我们无论是否指定编码方式,它在python内部就是以英文字符存在的,而是中文时,无论它是否有指定某种编码,它的方式都是某种“代码”的形式(\u4f60 或 \xc4\xe3)。
这里,我从两个方面来试着解释上面的例子中所发生的东西。
第一个方面: 对unicode码的操作
>>> u"hello"
>>>u'hello'
>>> u"你好"
>>>u'\u4f60\u597d'
这一行的两个句子实质上都没有经过编码。只是做了一下字符形式上的变换
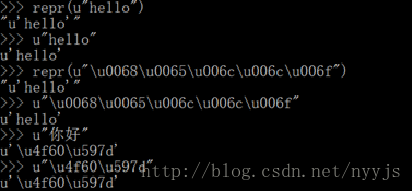
表面上看,中文跟英文的unicode不一样,但实质上是一样的,还记的我们前面讲的吗“unicode码就是字符的另外一种表现形式,它没有经过其他任何编码”。拿 u”h” 来说,它的unicode码是u”\u0068”,在cmd中进行验证
>>> u"\u0068"
>>>u'h'
那为什么>>> u”h”不显示成u“\u0068”呢?我的理解是“内部存储”和“外部显示”是不一样的。内部存储都是unicode符,而在显示给外部时,有两种选择,unicode符和字符本身。到底选择哪种方式,有一个我自己总结的原则:哪种方式更友好就显示哪种。对处在0-127范围的英文字符来讲,显示字符本身u“h”肯定比干巴巴的u“\u0068 “更友好;在0-127之外的中文字符,只有一种选择,就是显示unicode符。实质上,你完全可以把unicode和字符本身等价看待。我们可以进一步进行验证:英文的unicode是以单个字符显示的,中文字符是以unicode显示的,如下:
第二个方面:对字符串的操作
>>> "hello"
>>>'hello'
>>> u"hello".encode('gbk')
>>>'hello'
>>> "你好"
>>>'\xc4\xe3\xba\xc3'
>>> u"你好".encode('gbk')
>>>'\xc4\xe3\xba\xc3'
我们是要对字符串编码为字节码,指定的编码方式是gbk。
第一行当你敲下字符串的时候,实质上,你已经将该字符串按照gbk进行了encode(这句话实质上不严谨,后面解释,暂且这么说),从而变成了字节码;它与第一行后部分的显示地编码做的是同样的工作。根据gb2312码的编码规则(gbk是gb2312基础上的扩展),无论中文字符还是英文字符,每个字符都被编成两个字节。按照这个说法,u“hello”应该是被编成了十个字节,即>>> u”hello”.encode(‘gbk’)的结果应该是“\x–\x–\x–\x–\x–\x–\x–\x–\x–\x–”这种形式,而非显示”hello”。实质上,这涉及到了全角和半角的区别(请自行百度全角半角)。
先抛出几个结论:全角半角只对英文字符有意义;即便指定的是gbk编码,gbk也不会对“半角”的英文字符进行编码,“半角”的英文编码全部是由ascii编码完成的,因此一个”半角”英文字符只会被编成一个字节;gbk编码只对全角英文字符编码,每个全角字符被编码为两个字节。如下:
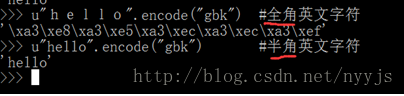
因此回过头再来理解第一行发生的事,实质上是对英文半角字符串进行的ascii的编码,而非gbk的编码。跟第一个方面的解释一样,python内部存储和外部显示是不一样的,在0-127范围之内显示都是字符本身,在0-127之外显示的是编码后的字节串。只是因为是英文,在0-127范围之内,按照原字符进行显示(见之前解释)。
同理第二行也是进行了编码,因为“你好”这两个中文字符都不在0-127范围之内,故只能按照编码之后的字节码’\xc4\xe3\xba\xc3’进行显示。
特别总结一下0-127范围内的字符:
在0-127范围内的字符,即ascii 集合内的字符。若没有经过编码(即为字符本身或unicode字符),则在python内部是以unicode存储,以字符本身进行显示。若该字符经过编码,无论什么类型的编码都与ascii的编码方式完全一样,都会按照原字符进行显示。进一步,无论它有没有经过编码,无论它经过何种类型的编码。0—127范围内的字节码和字符码的都可以认为是同一个东西,
那我们在日常的编码过程中,在与外界文件交互等的过程中,应该要注意哪些方面呢。有以下几点需要注意:
首先一定一定要规范编码,统一编码规范,引用“http://www.mamicode.com/info-detail-308445.html”中的说法,我们可以把python解析器当成一个水池子,有个入口,有个出口。入口处,全部转成unicode, 池里全部使用unicode处理;出口处,再转成目标编码(当然,有例外,处理逻辑中要用到具体编码的情况)
在池子内部(即在python编辑器中)
我们要主动设置defaultencoding(默认为ascii),一般设为’utf8’,如下:
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8’)
对于英文字符串(准确地说是在0—127范围内的字符),若没有经过编码(即字符串前有无u,类似于u”–”),其unicode码值与ascii码值是一样的。若编码了(类似于“–” 或u“–“.encode(“utf8”)),无论指定的是什么编码,它都是按照ascii编码的,那么编码值最终反映的也是ascii码值。因此,英文字符串来讲,无所谓是否指定为unicode编码,也无所谓指定的是什么编码,最终反应的都是ascii码(码值一样)。
对于中文字符串(准确地说是在0—127之外的字符),就必须要明确我们到底要处理的是字符串,还是编码之后的字节串。若是字符串,我们必须要指定它是unicode的字符串,即前面要加上u,如u”你好”;若是我们想要编码之后的字节串,就必须要明确指定有效的字节串,如u”你好”.encoding(“utf8”)。
按照我们前面讲的原则,在python内部,我们最好是把所有涉及字符串的地方,都在前面加上u,特别是串内出现了中文的情况。除非你确定串内只有英文字符,绝不会出现0—127范围外的字符。
在池子外部(即在python编辑器中)
在“输入”到池子时,全部转成unicode,一般来说是用“decode()”方法;从池子往外“输出”时,转成目标编码,一般用“encode()”方法。也就是说在池子内部,尽量都保证是unicode字符码,在池子外部都转为字节码。
输入:
a) 文本文件时。实质上读入的是字节流,因此在进入“池子”之前,需要把这些字节流统一解码为unicode码。
如:
# 使用codecs直接开unicode通道
file = codecs.open("test", "r", "utf-8") #字节码进python前先按”utf8”解码成unicode
for i in file:
print type(i) # i的类型是unicode的
b) 网页时。来自于http://python.jobbole.com/81244/ 的例子
拿http客户端库中的requests库来讲,其中的Request对象在访问服务器后会返回一个Response对象,这个对象将返回的Http响应字节码保存到content属性中。但是如果你访问另一个属性text时,会返回一个unicode对象,乱码问题就会常常发成在这里。所以要么你直接使用content(字节码),要么记得把encoding设置正确,比如我获取了一段gbk编码的网页,就需要以下方法才能得到正确的unicode。
import requests
url = "http://xxx.xxx.xxx"
response = requests.get(url)
response.encoding = 'gbk'
print response.text
输出:
a) 输出到shell。在将字符串在shell中打印时,实质上是直接将字节流输出到shell中的。因此需要将池子中的unicode码按照shell中编码格式编码为shell字节串。如果编成其他码,则可能会导致乱码。
b) Write到文件时。
# -*- coding: gb2312 -*-
s = "你好"
u = s.decode('gbk')
f = open('text.txt','w')
f.write(u) # 出错!
f.write(u.encode('gbk')) # 这样才行
出错的原因很简单,你想输出的是“字符”,而不是“字节”。前面说过,“字符”是抽象的,你是没有办法把一个抽象的东西写到文件里去的。当然,如果字符串内是码值是0-127范围内的字符,是可以成功的(见前面的解释),但是不推荐。最地道的写法是字符串(无论字符串码值是否在0—127范围内)在写进文件之前,统统编码为字节串。
二, string_escape 和 unicode_escape
1)string_escape 和 unicode_escape是python特有的两种编码。官方文档的说明:
string_escape :Produce[s] a string that is suitable as string literal in Python source code
unicode_escape:Produce[s] a string that is suitable as Unicode literal in Python source code
中文翻译,在python源码中生成一个适合作为unicode字面上的字符串。
对于英语渣渣来讲:string认识,literal也认识,连一起的string literal就不认识了(unicode literal也是一样)。
关键是这里的string literal 和 unicode literal该怎么理解?
从例子上来帮助说明:
https://gist.github.com/zfox49/2d9f144315da3dc19e67cb5e66dcc3be
string_escape:
>>> "你好".encode('string_escape')
'\\xc4\\xe3\\xba\\xc3'
>>> '\xe6\x88\x91'.encode('string_escape')
'\\xe6\\x88\\x91'
>>> "hello".encode('string_escape')
'hello'
Unicode_escape:
>>> u"你好".encode('unicode-escape')
'\\u4f60\\u597d'
>>> u"\u4f60\u597d".encode('unicode-escape')
'\\u4f60\\u597d'
>>> u'hello'.encode('unicode-escape')
'hello'
我们知道,
>>> u“你好”.encode(‘gbk’)
>>>'\xc4\xe3\xba\xc3'
>>> '\xc4\xe3\xba\xc3'.encode('string_escape')
>>>'\\xc4\\xe3\\xba\\xc3'
>>>u'\u4f60\u597d'
>>> u'\u4f60\u597d'.encode('unicode_escape')
>>>'\\u4f60\\u597d'
也就是说string_escape 是把在字符串编码后的每个字节前面加上转义字符 ’\’ ,这个转义字符就是string_escape 的 “escape(转义)” 的意思。同理unicode_escape也是可以类似理解。总结来说,就是把在python内“存储”的字节码或字符码(unicode) 显式地显示出来,在显示时,原来字节串中有一个 ‘\’,再将其转义之后,就在原来基础上多加了一个 ‘\’。
这样做的意义在哪?为什么要这样做?下面谈谈我的理解。
再次强调一遍:在ASCII字符集(0–127)范围内的字符,可以认为字符和字节就是同一个东西,它们“融合了”!无论经过怎样的encode,decode,最后的结果都是ASCII字符本身,所以也可以认为它没有了encode decode的概念。ASCII字符集内的字符在整个python世界中都是畅通无阻的!!!容易出问题的就是0—127范围之外的字符!
回到这里,我们发现,encode之后,是生成了一个全新的字符串(也是字节串)。对python而言,我不去想它代表的是什么,它就是一个字符串而已(’\xc4\xe3\xba\xc3’ 或 ‘\u4f60\u597d’),这个串内的所有字符的码值都在0–127范围内。通过这样的处理,我们惊奇地发现存这样处理给我们带来了极大的便利:首先原始字符串(无论字符是不是在0-127范围内)的信息也没有丢失,只是换了一种表示方式;同时原始字符串被统一转化为0—127范围内的字符。还记得我们前面强调过的吗,在ASCII字符集内的字符,对python世界而言是同一个东西。因此在python与输入输出进行交互的时候,就避免了频繁的decode,encode。不过这样处理的后果是人可能看不懂,想想print出来的是’\xc4\xe3\xba\xc3’,或者输出到文件中的是’\u4f60\u597d’这种鬼东西,虽然信息没有丢失,但是我们人看不懂。因此为了人能够看懂,我们可能要对这些字符串还原成它本来的意思,于是就需要对我们就可能就需要各种encode,decode了。
解释到这里,你应该明白了,string_escape和unicode_escape的作用就是把原始字符串(无论中文还是英文)统一成ASCII字符集的字符串,这样方便在整个python世界中(机器世界)进行处理、传输。为了方便我们人类世界看懂,才会最终使用各种encode,decode来将这些ASCII字符集的字符串还原成我们它本来的样子。
三, 那看到一个编码后的串,我们如何从字面上看它是什么编码?
以下斜字体引用自http://www.cnblogs.com/Xjng/p/5093905.html
1)没有办法准确地判断一个字符串的编码方式,例如gbk的“\aa”代表甲,utf-8的“\aa”代表乙,如果给定“\aa”怎么判断是哪种编码?它既可以是gbk也可以是utf-8
2)我们能做的是粗略地判断一个字符串的编码方式,因为上面的例如的情况是很少的,更多的情况是gbk中的’\aa’代表甲,utf-8中是乱码,例如�,这样我们就能判断’\aa’是gbk编码,因为如果用utf-8编码去解码的结果是没有意义的
3)而我们经常遇到的编码其实主要的就只有三种:utf-8,gbk,unicode
• unicode一般是 \u 带头的,然后后面跟四位数字或字符串,例如 \u6d4b\u8bd5 ,一个 \u 对应一个汉字
• utf-8一般是 \x 带头的,后面跟两位字母或数字,例如 \xe6\xb5\x8b\xe8\xaf\x95\xe5\x95\x8a ,三个 \x 代表一个汉字
• gbk一般是 \x 带头的,后面跟两位字母或数字,例如 \xb2\xe2\xca\xd4\xb0\xa1 ,两个个 \x 代表一个汉字
4)使用chardet模块来判断
import chardet
raw = u'我是一只小小鸟'
print chardet.detect(raw.encode('utf-8'))
print chardet.detect(raw.encode('gbk'))
*输出:
{‘confidence’: 0.99, ‘encoding’: ‘utf-8’}
{‘confidence’: 0.99, ‘encoding’: ‘GB2312’}
chardet模块可以计算这个字符串是某个编码的概率,基本对于99%的应用场景,这个模块都够用了。*
四,典型例子汇总:
1, 关于encode decode 的常见错误(一般都是编码和解码不一致导致的)
1) 最常见的一种错误,我们对已经编码过后的字节串再次使用encode,这种实质上有一个“隐式”的解码动作,即隐式地将字节串解码为unicode字符串(解码类型是sys.getdefaultencoding(),一般为ascii ),然后才再encode。整个过程如下:
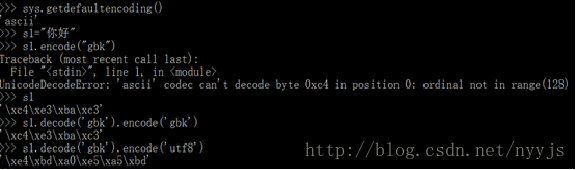
补充一点,本例是在cmd中,该cmd的“显式”编码类型是gbk,所谓的“显式”、“隐式”的名字是我自己取的,具体解释见另一篇博客 http://blog.youkuaiyun.com/nyyjs/article/details/56670080。
在python2.x下,最好的解决办法是保证显式隐式的编码类型一致。
1) 笔者在某个项目中有这么一段数据:
“{\x22provinceName\x22:\x22\xE5\x8C\x97\xE4\xBA\xAC\xE5\xB8\x82\x22}”
我们如何解析它,首先,明面上传递”\x–” 这样的字符串,说明是经过“string_escape”编码过的。“\x22”是英文字符的双引号,其他 “\x–” 不知道是什么编码。我们假设是最常用的utf8编码,那试着解析一下,解析的过程如下: 
Bingo! 成功
2) 网上摘取的一段字符串(https://www.v2ex.com/t/174215),如下:
“u’\xe6\x97\xa0\xe5\x90\x8d’”
首先字符串前的u表示它是unicode字符串,但串内又不是 “\u—-”, 而是”\x–”,试着解析一下 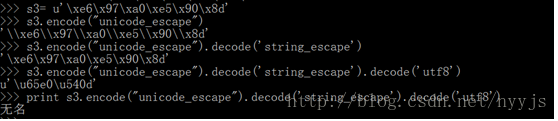
成功
3) 摘取的另一段字符串(http://blog.youkuaiyun.com/devil_2009/article/details/38796533)
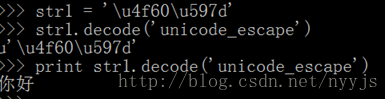
str1 = ‘\u4f60\u597d’
作者:nyyjs
来源:优快云
原文:https://blog.youkuaiyun.com/nyyjs/article/details/56667626
版权声明:本文为博主原创文章,转载请附上博文链接!

















 1983
1983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









