



 本文详细介绍Hadoop在CentOS 7.0上的安装、环境配置、Hadoop配置步骤,包括核心配置文件调整、环境变量设定、HDFS格式化与启动,以及集群搭建流程。
本文详细介绍Hadoop在CentOS 7.0上的安装、环境配置、Hadoop配置步骤,包括核心配置文件调整、环境变量设定、HDFS格式化与启动,以及集群搭建流程。
hadoop安装配置及集群搭建
1、安装centos7.0
见https://blog.youkuaiyun.com/xin980724/article/details/106841228
2、环境配置
关闭防火墙
停止防火墙服务
systemctl stop firewalld
禁用防火墙,下次开机启动后防火墙服务不再启动
systemctl disable firewalld
免密登录见https://blog.youkuaiyun.com/xin980724/article/details/106859575
3、配置hadoop
配置Hadoop ./etc/hadoop目录下的文件
vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/jdk1.8.0_221
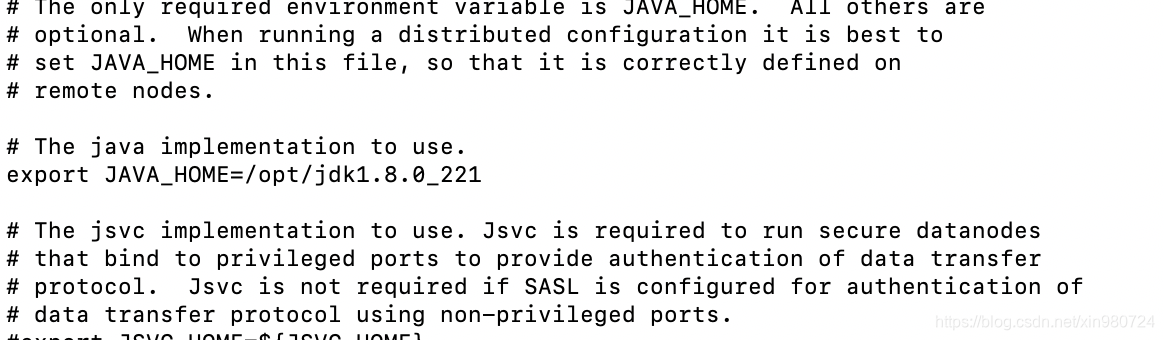
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.101:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
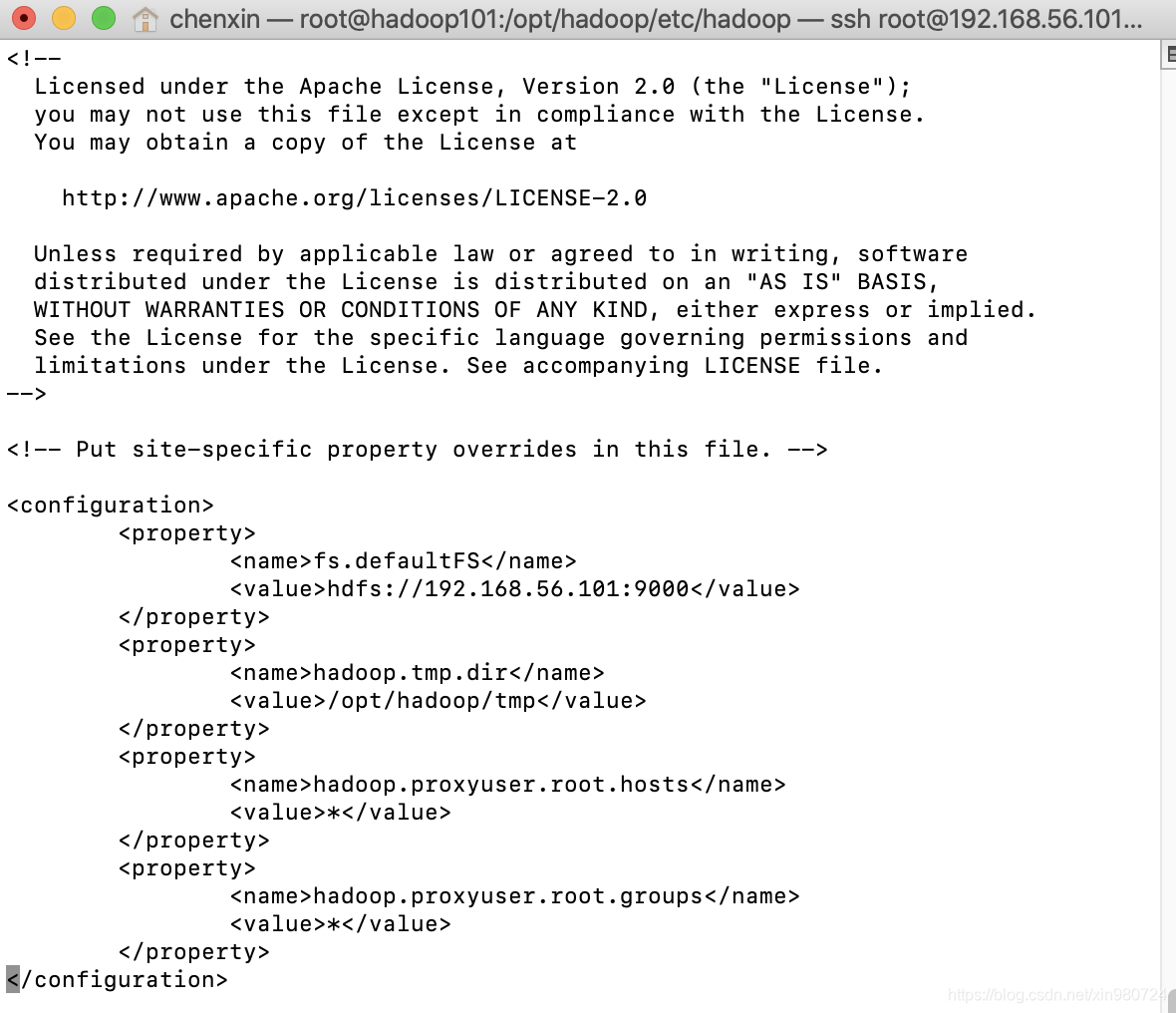
vi hdfs-site.xml
多台
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop001:50090</value>
</property>
</configuration>
一台
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
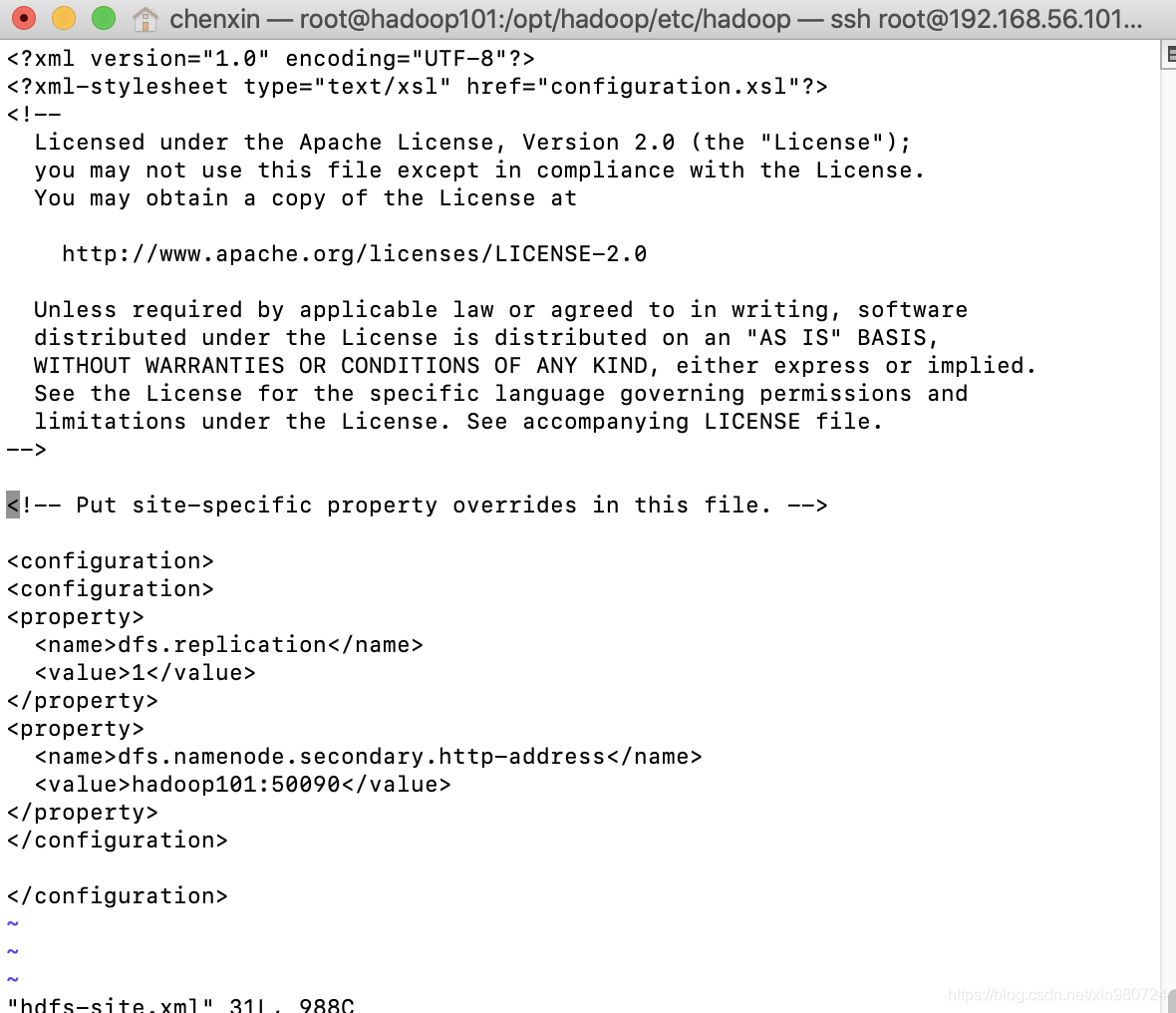
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 多台要下面两个 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop001:19888</value>
</property>
</configuration>
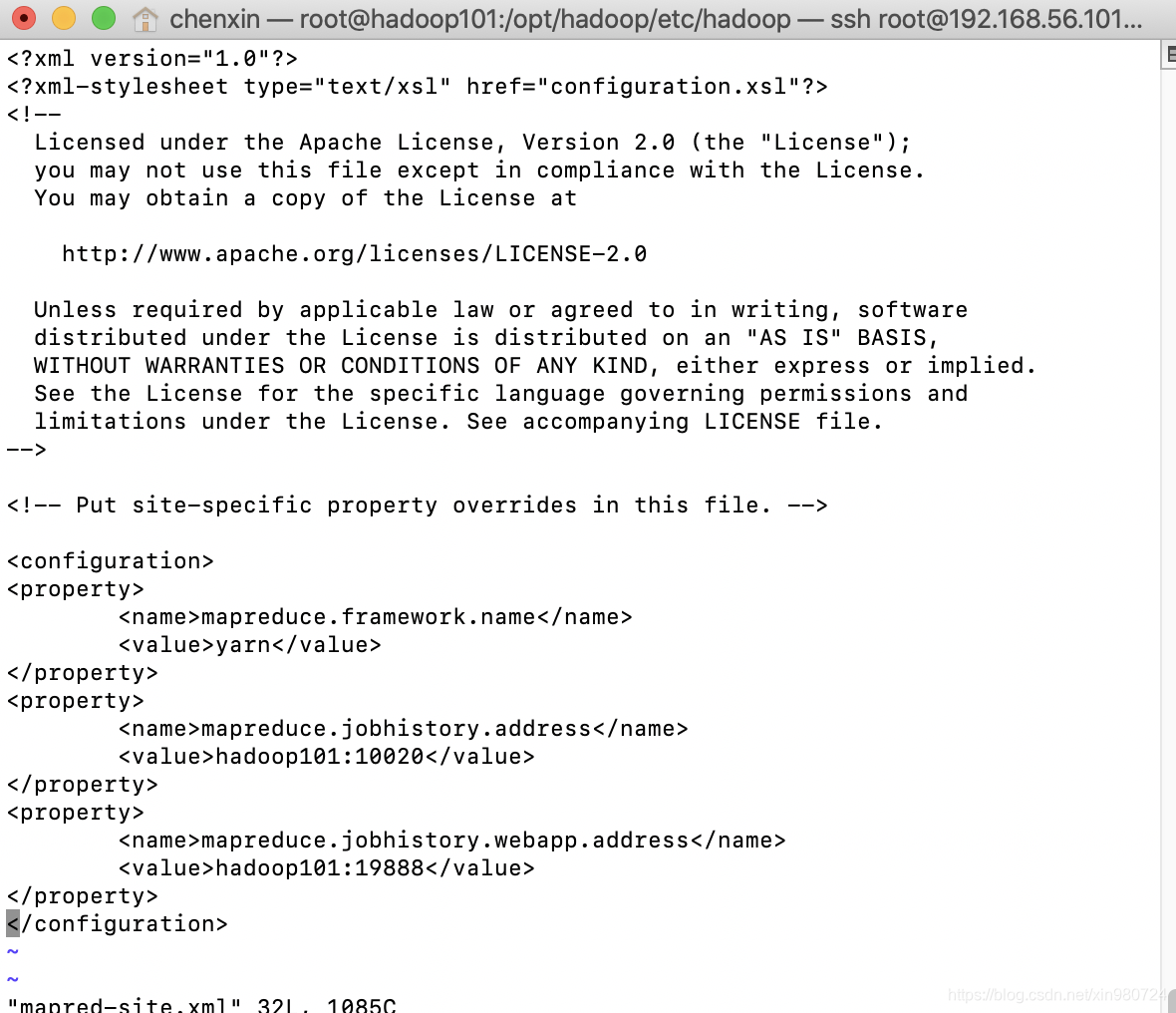
vi yarn-site.xml
<configuration>
<!-- reducer获取数据方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
<!-- 日志聚集功能使用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>jp
</property>
</configuration>
vi ./slaves
hadoop001
4、 Hadoop环境变量配置
vi /etc/profile
export HADOOP_HOME=/opt/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source /etc/profile
5、格式化HDFS
hadoop namenode -format
6、启动hadoop
start-all.sh
jps 查看启动项
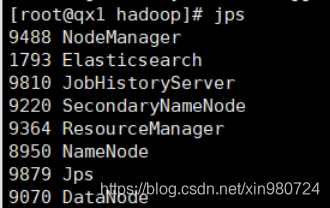
7、访问hadoop
http://192.168.56.101:50070 HDFS页面
http://192.168.56.101:8088 YARN的管理界面
8、 搭集群
先见https://blog.youkuaiyun.com/xin980724/article/details/106859575
复制好虚拟机 配好ip地址 弄好密钥
把上面 3 在复制的虚拟机中再做一遍 改成自己的ip地址

















 5034
5034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









