



告别“笨重”检测!VA-YOLO算法让疲劳驾驶识别更轻更快更准
在机动车保有量节节攀升的今天,便捷出行的背后潜藏着不容忽视的交通安全隐患,其中疲劳驾驶堪称“马路杀手”之一。疲劳状态下,驾驶员的反应速度、判断能力会急剧下滑,由此引发的事故致死率远高于其他类型事故。如何快速、精准地识别疲劳驾驶行为,成为交通安全领域的研究热点。而传统检测模型往往面临“精度与速度不可兼得”“部署成本高”的困境,轻量化改造迫在眉睫。本文结合笔者团队的最新研究,从环境搭建、数据集构建、模型改造到实验验证,完整拆解轻量化疲劳驾驶检测的实现路径。

一、研究前置:环境搭建全攻略
工欲善其事,必先利其器。为保障研究顺利推进,我们搭建了适配轻量化模型训练与测试的软硬件环境,兼顾性能与成本,具体配置如下:
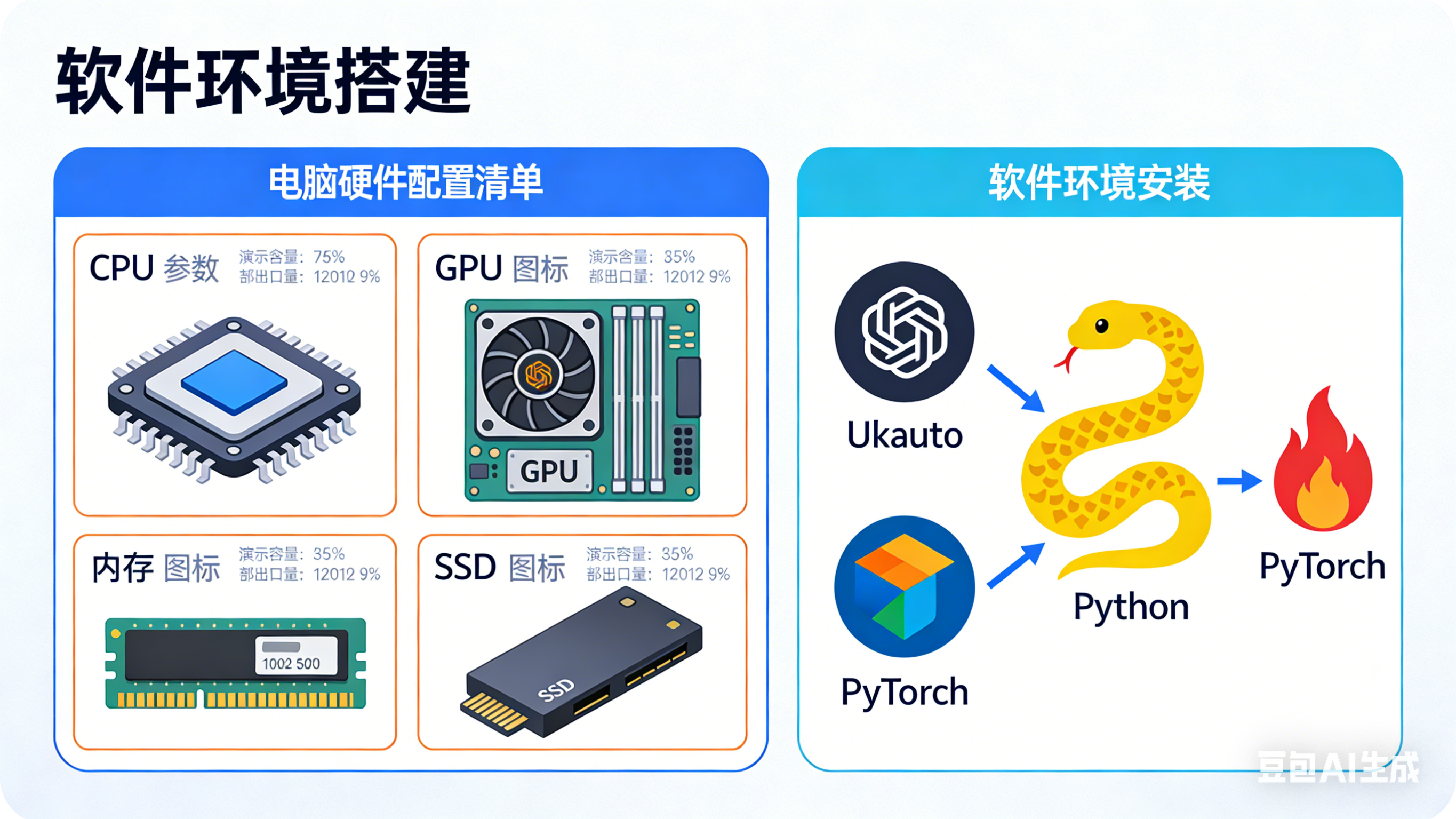
1.1 硬件环境
考虑到模型训练过程中需处理大量图像数据,同时兼顾轻量化模型的特性,硬件配置无需过度“顶配”,具体为:CPU选用Intel Core i7-12700H(14核20线程,主频2.7GHz,最大睿频4.7GHz),满足数据预处理的并行计算需求;GPU采用NVIDIA RTX 3060(6GB显存),可高效支撑模型训练过程中的张量运算,避免因显存不足导致的训练中断;内存配置32GB DDR4 3200MHz,保障数据集加载及模型运行时的内存供给;存储选用1TB SSD,提升数据集读取速度,减少训练过程中的IO等待时间。
1.2 软件环境
软件环境基于Python生态搭建,适配主流深度学习框架,具体版本及依赖如下:操作系统选用Ubuntu 20.04 LTS(稳定性强,对深度学习工具兼容性好);编程语言为Python 3.8(避免高版本带来的依赖冲突);深度学习框架采用PyTorch 1.12.1(搭配CUDA 11.6,充分利用GPU加速训练);数据处理工具包括OpenCV 4.6.0(图像读取、预处理)、NumPy 1.23.4(数组运算)、Pillow 9.2.0(图像增强操作);模型可视化工具为TensorBoard 2.10.0(实时监控训练损失、精度);其他依赖库包括scikit-learn 1.1.2(数据划分、指标计算)、tqdm 4.64.0(训练进度展示)。
1.3 环境配置步骤
-
安装Ubuntu 20.04 LTS系统,配置静态IP及镜像源(推荐阿里云或清华源),提升后续软件安装速度。
-
安装Python 3.8,通过apt命令:sudo apt update && sudo apt install python3.8 python3.8-venv python3.8-dev。
-
创建虚拟环境:python3.8 -m venv fatigue_env,激活环境:source fatigue_env/bin/activate。
-
安装CUDA 11.6及CuDNN 8.4.1,严格按照NVIDIA官方指南操作,确保GPU加速功能正常。
-
通过pip安装依赖库:pip install torch1.12.1+cu116 torchvision0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116,随后依次安装其他依赖库:pip install opencv-python4.6.0.66 numpy1.23.4 pillow9.2.0 tensorboard2.10.0 scikit-learn1.1.2 tqdm4.64.0。
-
验证环境:运行python -c “import torch; print(torch.cuda.is_available())”,输出True则说明GPU环境配置成功;运行import cv2,无报错则说明OpenCV安装成功。
二、数据基石:Fatigue-Driving数据集构建与增强
模型的性能离不开高质量数据集的支撑。驾驶场景中,驾驶员面部表情受光线、角度、遮挡等因素影响,呈现出极强的多样性,传统数据集往往存在数据量不足、场景覆盖不全面的问题,导致模型鲁棒性较差。为此,我们构建了“Fatigue-Driving”数据集,并通过精细化数据增强手段,提升数据的多样性与鲁棒性。

2.1 数据集原始数据来源
原始数据涵盖真实驾驶场景与模拟驾驶场景:真实驾驶场景数据通过在私家车、出租车、货车等不同车型内安装摄像头采集,涉及不同性别(男性占比62%,女性占比38%)、不同年龄层(18-60岁,分青年、中年、老年三个组别)的驾驶员,采集时间覆盖早、中、晚不同时段,包含晴天、阴天、夜间等不同光线条件;模拟驾驶场景数据通过驾驶模拟器采集,可精准控制驾驶员的疲劳程度(清醒、轻度疲劳、中度疲劳、重度疲劳),补充极端疲劳状态下的面部数据。原始数据集共包含12000张图像,其中训练集8400张、验证集2400张、测试集1200张。
2.2 精细化数据增强操作
为解决数据量不足及场景单一的问题,我们对原始图像进行了多维度精细化增强,具体操作如下:
-
明暗度调整:采用随机亮度、对比度调整,亮度变化范围为原始亮度的0.7-1.3倍,对比度变化范围为0.8-1.2倍,模拟不同光线条件下的面部图像。
-
旋转角度调整:随机旋转图像,旋转角度范围为-15°至15°,旋转后进行裁剪,确保面部区域完整,模拟驾驶员头部轻微晃动的场景。
-
缩放比例调整:随机缩放图像,缩放比例范围为0.8-1.2倍,缩放后保持图像尺寸一致,模拟摄像头与驾驶员距离变化的场景。
-
噪声添加:添加高斯噪声(方差范围0.001-0.01)和椒盐噪声(噪声密度范围0.01-0.05),模拟真实驾驶场景中摄像头拍摄的噪声干扰。
-
其他增强操作:包括随机水平翻转(概率0.5)、色域变换(调整RGB通道比例)等,进一步提升数据多样性。
增强后,Fatigue-Driving数据集规模扩充至48000张图像,训练集、验证集、测试集比例保持7:2:1。通过数据增强,模型可学习到更多面部细节特征,有效提升对复杂场景的适应能力。
三、模型核心:VA-YOLO轻量化算法设计
为实现疲劳驾驶检测的轻量化与高速化,同时兼顾检测精度,我们在YOLOv8n(YOLOv8系列的轻量化版本)基础上,提出了“VA-YOLO”目标检测算法,通过主干网络替换、注意力机制引入、损失函数优化三大核心改造,实现精度与速度的双重提升。
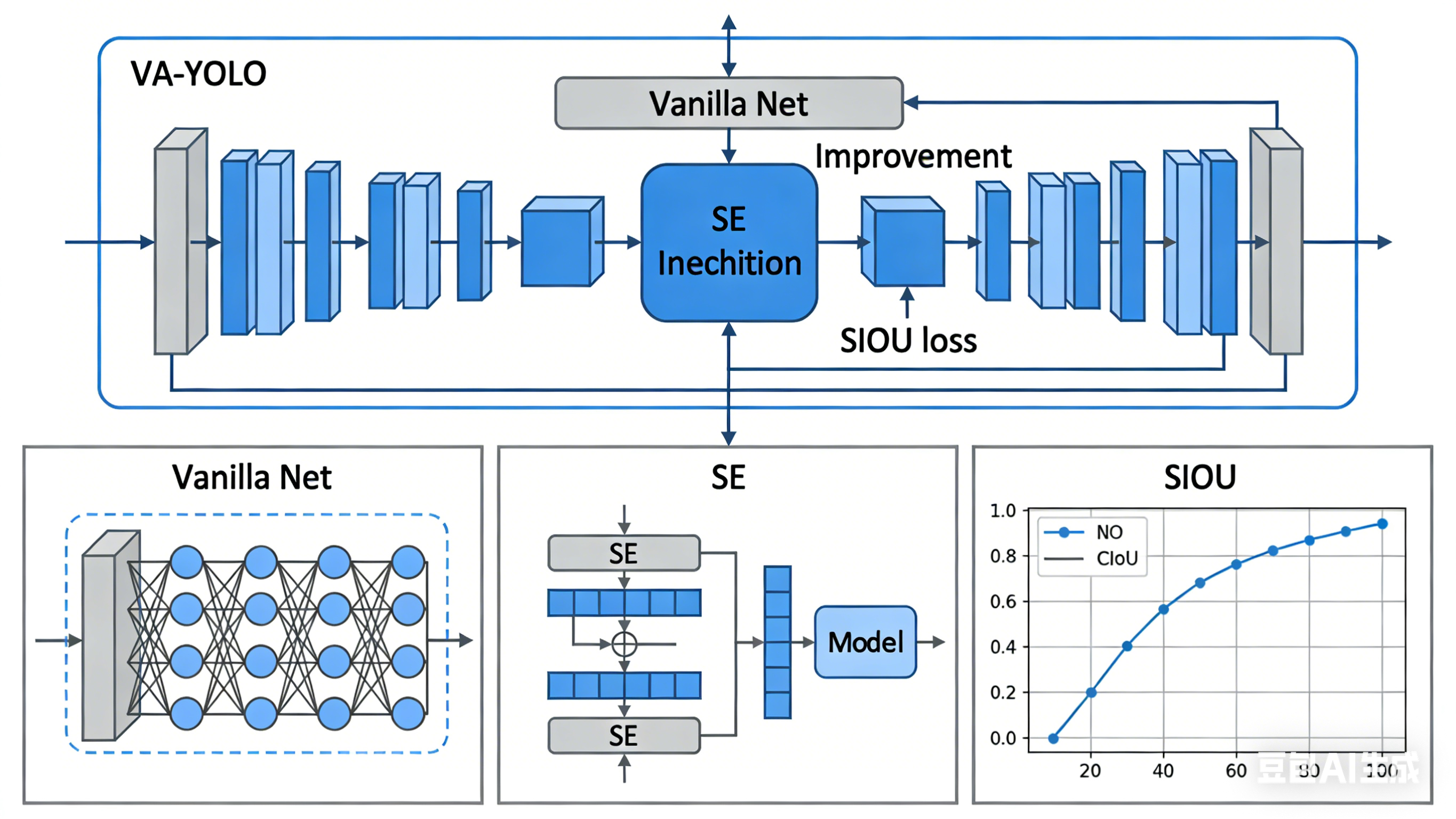
3.1 轻量级主干网络:Vanilla Net替代传统骨干
传统YOLO模型采用Darknet等复杂主干网络,虽能提取丰富特征,但参数量和计算量较大,难以满足边缘设备(如车载终端)的部署需求。VA-YOLO算法选用轻量级主干网络Vanilla Net替代传统骨干网络,Vanilla Net采用简洁的卷积结构,通过减少卷积层数量、降低卷积核尺寸(以3×3卷积为主)、采用深度可分离卷积等方式,大幅减少模型的参数量和计算量。具体而言,Vanilla Net去除了传统网络中的冗余卷积层,保留核心特征提取模块,同时通过通道剪枝技术,进一步压缩网络宽度,在保证特征提取能力的前提下,实现模型轻量化。
3.2 注意力机制引入:SE模块增强目标特征捕捉
疲劳驾驶检测的核心是准确捕捉驾驶员的面部疲劳特征(如眼睑闭合、头部低垂、打哈欠等),但复杂驾驶场景中,面部区域可能受背景干扰(如座椅、方向盘、窗外景物),导致模型对目标特征的关注度不足。为此,VA-YOLO算法引入SE(Squeeze-and-Excitation)注意力机制,通过对特征图进行全局池化(Squeeze操作)、自适应学习通道权重(Excitation操作),增强模型对重要特征通道的关注度,抑制无关背景特征的干扰。SE模块嵌入在主干网络的特征提取阶段,可自适应调整面部特征通道的权重,提升模型对面部区域的捕捉能力,进而提高检测精度。
3.3 损失函数优化:SIoU损失减小检测误差
边界框回归精度直接影响目标检测效果,传统YOLO模型采用CIoU损失函数,虽能考虑边界框的重叠度、中心点距离、宽高比等因素,但在处理遮挡、小目标(如面部细节区域)时,回归误差较大。VA-YOLO算法引入SIoU(Scaled IoU)损失函数,SIoU在CIoU的基础上,增加了对边界框尺度的惩罚项,通过优化边界框的回归方向,加快模型收敛速度,同时减小边界框的回归误差。尤其在疲劳驾驶检测中,对于眼睑、嘴巴等小尺寸疲劳特征区域,SIoU损失函数可显著提升边界框回归精度,进而提高疲劳状态识别的准确性。
四、实验验证:VA-YOLO算法性能测试
为验证VA-YOLO算法的性能,我们在Fatigue-Driving数据集上进行了对比实验,以YOLOv8n作为基准模型,从检测精度(mAP@0.5)、参数量、计算量(FLOPs)、检测速度(FPS)四个核心指标进行评估。
4.1 实验设置
训练参数:批量大小(batch size)设为32,训练轮数(epochs)为100,初始学习率为0.01,采用SGD优化器(动量0.9,权重衰减0.0005),学习率策略采用余弦退火衰减;测试环境:统一在本文搭建的软硬件环境中测试,确保实验结果的公平性。
4.2 实验结果与分析
实验结果如下表所示(表中数据为测试集上的平均结果):
| 模型 | 检测精度(mAP@0.5) | 参数量(M) | 计算量(GFLOPs) | 检测速度(FPS) |
|---|---|---|---|---|
| YOLOv8n | 82.1% | 3.16M | 8.7 | 65 |
| VA-YOLO | 87.4% | 2.15M | 6.2 | 88 |
| 从实验结果可以看出:与基准模型YOLOv8n相比,VA-YOLO算法在检测精度上提升了5.3个百分点(从82.1%提升至87.4%),参数量下降了1.01M(从3.16M降至2.15M,降幅约32%),计算量下降了2.5 GFLOPs(降幅约29%),检测速度提升了23 FPS(从65 FPS提升至88 FPS,提升约35%)。 |
分析原因:① Vanilla Net主干网络的引入,有效减少了模型的参数量和计算量,为检测速度的提升奠定了基础;② SE注意力机制增强了模型对面部疲劳特征的捕捉能力,减少了背景干扰,从而提升了检测精度;③ SIoU损失函数优化了边界框回归效果,尤其提升了小尺寸疲劳特征区域的检测精度。综合来看,VA-YOLO算法实现了“精度提升、轻量化、高速化”的三重目标,更适合部署在车载终端等边缘设备上,满足疲劳驾驶实时检测的需求。
五、总结与展望
本文围绕疲劳驾驶检测的轻量化需求,从数据集构建、模型设计到实验验证,开展了一系列研究工作:构建了精细化增强的Fatigue-Driving数据集,为模型训练提供了高质量数据支撑;提出了VA-YOLO轻量化算法,通过主干网络替换、注意力机制引入、损失函数优化,实现了检测精度与速度的双重提升。实验结果表明,VA-YOLO算法在轻量化程度和检测性能上均优于传统模型,具有良好的实际应用价值。
未来研究方向:① 进一步扩充数据集,增加特殊场景(如雨天、雾天、驾驶员佩戴口罩/墨镜)下的样本,提升模型的泛化能力;② 探索更高效的轻量级网络结构(如结合Transformer的轻量化模型),进一步提升检测速度;③ 结合多模态数据(如面部图像+生理信号),实现疲劳驾驶的多维度精准识别,为交通安全提供更全面的保障。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









