




 本文深入解析JAVA中的流操作,区分字节流与字符流,详细介绍FileReader、InputStreamReader、BufferedReader等类的功能与使用,以及它们在文件读取中的角色。
本文深入解析JAVA中的流操作,区分字节流与字符流,详细介绍FileReader、InputStreamReader、BufferedReader等类的功能与使用,以及它们在文件读取中的角色。
JAVA中的流可以按操作单元分为字节流和字符流两大类,字节流和字符流的用法几乎一样,区别在于字节流和字符流所操作的数据单元不同,字节流操作的单元是数据单元是8位的字节,字符流操作的是数据单元为16位的字符。
两种流的最顶级基类分别是:
Reader: 字符输入流抽象基类;
Write:字符输出流抽象基类;
InputStream:字节输入流抽象基类;
OutputStream: 字节输出流抽象基类;
当然,除了按操作单元划分,还可以更细节的按照功能划分。具体可见这篇博客
下面是我在学习中的一些笔记,比较零散,只介绍了输入流:
1字符流
- FileReader:实例化FileInputStream对象并传给父类InputStreamReader, 读取时通过转换流InputStreamReader将字节转换成CharSet中的字符。然后通过StreamDecoder类完成读。
- InputStreamReader:是字节流到字符流的桥梁。构造函数的参数类型是InputStream,也就是说它接受任意InputStream的子类型,然后作为中间的转换者,将字节转换成字符。此外接受定义字符集的参数,用于表示转换映射关系。只有FileReader这一个子类。
- BufferedReader:构造函数接受一个字符输入流对象(如FileReader、InputStreamReader)具体实现没看,实现ReadLine等功能,支持mark()。就是一个字符输入流的装饰器。
- CharArrayReader、StringReader:这两个是一类的,不像前面的流是从设备中读取数据。这两个类是将内存中的字符数组或字符串,构造函数需要传入目标字符数组,实现用读取流的方式读该数组,也就是用read()函数对数组进行读取。两者都支持mark()。
Reader接口中的方法:
- Reader:
- mark: 标记,与reset函数配合使用,回到标记点;
- reset:回到标记点,如果没有标记,一般回到流的开始处。
2字节流
- FileInputStream:使用文件路径、文件对象或描述。Reader和open()方法为native方法。有FileDescriptor类成员。
- ByteArrayInputStream:和CharArrayReader类似。
- FilterInputStream :构造函数的参数类型是InputStream。包含其他一些输入流,它将这些流用作其基本数据源,并对它们进行包装以提供一些额外的功能。FilterInputStream 类自身实现其实就是直接调用被包装的对象的方法,也就是说未添加任何转换。FilterInputStream 的子类可进一步重写这些方法中的一些方法,并且还可以提供一些额外的方法和字段以实现转换。
- BufferedInputStream:继承自FilterInputStream。提供的额外功能包括:mark()功能,有些类是不实现mark()函数的; 减少IO次数。BufferedInputStream中函数介绍:fill(),从源输入流中读取字节填充自身的buf(字节数组,即缓冲区);read(),从自身的缓冲区读取字节而不是进行IO操作,如果缓冲区被读完了,则继续填充缓冲区。
- DataInputStream:继承自FilterInputStream。允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型。比如:readInt()、readDouble()等;
- PipedInputStream:管道输入流应该连接到管道输出流;管道输入流提供要写入管道输出流的所有数据字节。通常,数据由某个线程从 PipedInputStream 对象读取,并由其他线程将其写入到相应的 PipedOutputStream。
一些总结
1.其实对于文件的操作,上述的这些类最终都是调用FilterInputStream中的read()函数,不同的类只是做不同的包装,实现不同的读取方式。
2.继承关系如下图所示(部分类)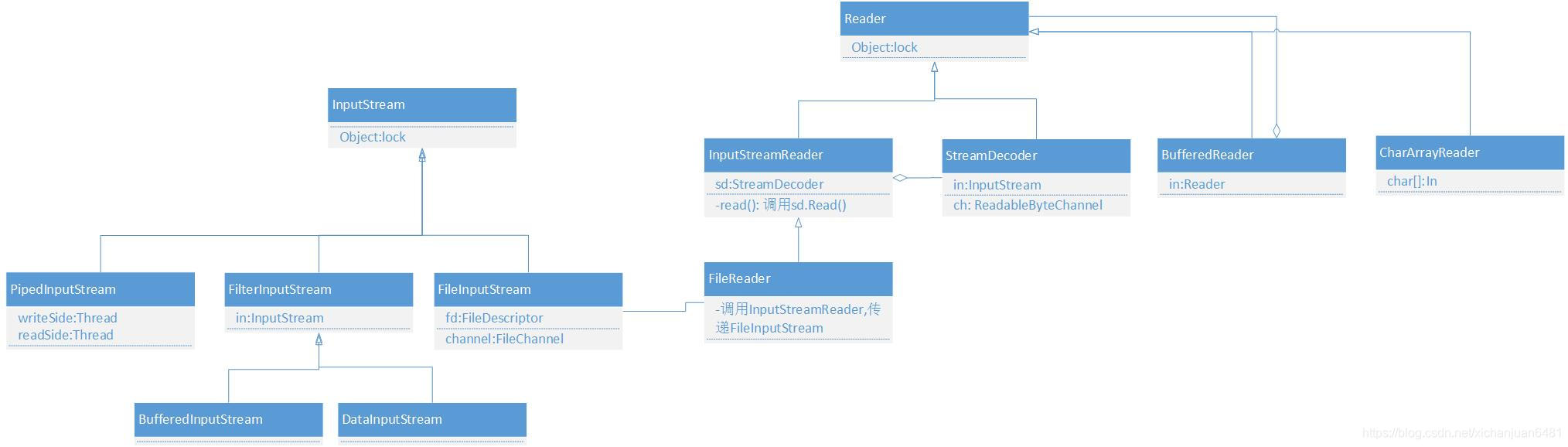

















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









