



 本文详细介绍了Hbase,一个基于GoogleBigTable的分布式列式数据库,涵盖了其特点(海量存储、高并发、稀疏和版本控制)、应用场景(海量数据存储、实时分析、用户画像等)、数据模型(RowKey、ColumnFamily等)以及Hbase的整体架构,包括Zookeeper和HRegionServer的角色。还介绍了如何启动和停止Hbase集群以及基本的HBaseshell操作。
本文详细介绍了Hbase,一个基于GoogleBigTable的分布式列式数据库,涵盖了其特点(海量存储、高并发、稀疏和版本控制)、应用场景(海量数据存储、实时分析、用户画像等)、数据模型(RowKey、ColumnFamily等)以及Hbase的整体架构,包括Zookeeper和HRegionServer的角色。还介绍了如何启动和停止Hbase集群以及基本的HBaseshell操作。
目录
简介
Hbase源于Google大数据三大论文之Big Table而来,是一个分布式海量列式非关系型数据库系统,可以提供超大规模数据集的实时随机读写。
Hbase是一个开源的、分布式的、版本化的NoSQL(即非关系型数据库),依托于Hadoop分布式文件系统HDFS提供分布式数据存储,利用MapReduce来处理海量数据,用Zookeeper作为其分布式协调服务,一般用于存储海量数据。HDFS与Hbase的区别在于,HDFS是文件系统,而Hbase是数据库。
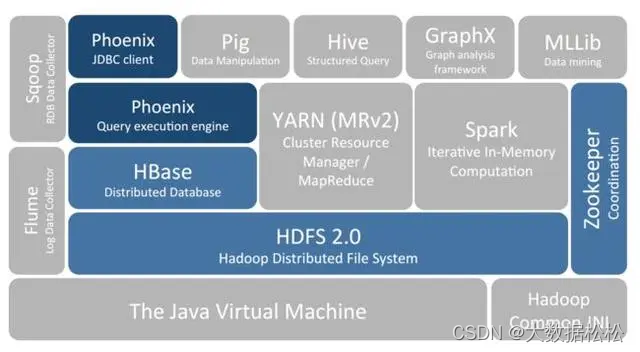
Hbase特点
- 海量存储:底层是基于HDFS存储海量数据
- 列式存储:Hbase表的数据是基于列族进行存储的,一个列族包含若干列
- 极易扩展:底层依赖HDFS,当磁盘空间不足时,只需要动态增加DataNode服务节点即可
- 高并发:支持高并发的读写请求
- 稀疏:稀疏主要是针对Hbase列的灵活性,在列祖中,你可以制定任意多的列,在列数据为空的情况下,是不占用存储空间的
- 数据的多版本:Hbase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳
Hbase的应用场景
-
海量数据存储: Hbase能够处理PB级别的数据量,适合于存储大规模的数据,如日志数据、监控数据、交易数据等;
-
低延迟读写:Hbase支持高效的随机读写操作,能够在毫秒级内完成数据访问,特别适合于需要实时访问和查询数据的场景;
-
高并发读写:Hbase可以支持大量的并发读写操作,处理数百万级别的并发访问请求,适合需要处理高并发访问的场景;
-
数据分析和挖掘:Hbase支持多种过滤器和聚合函数,可以对数据进行精确的过滤和统计分析,适合于需要进行数据分析和挖掘的场景;
-
实时计算和流处理:Hbase可以与Flink、Spark等实时数据处理框架结合使用,构建实时数据系统,如实时同步到消息队列等;
-
用户画像:特别是在进入封控等领域,Hbase构建用户画像,这是较大的稀疏矩阵,做个性化查询推荐;
-
CubeDB OLAP:Kylin是一个cube分析工具,底层的数据存储在Hbase中,满足在线报表查询的需求;
-
监控大屏:
Hbase的数据模型
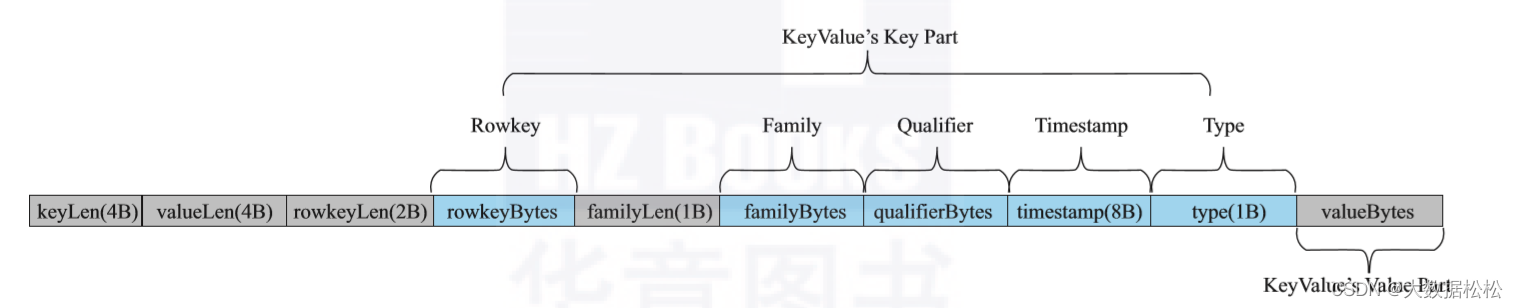
图源:胡争,范欣欣《HBase原理与实践》第二章《基础数据结构与算法》)
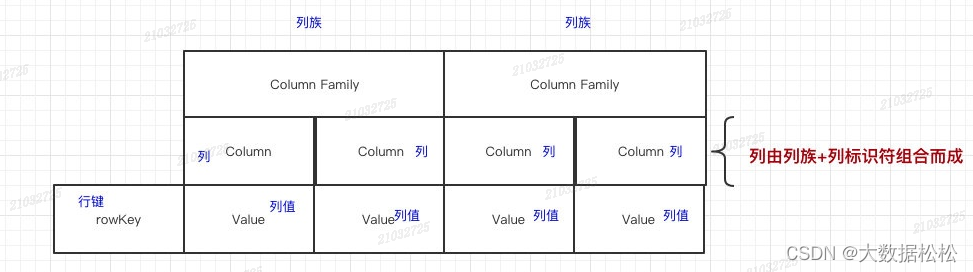
- 命名空间:类似于关系型数据库的database概念,每个命名空间下有多个表。Hbase自带的两个命名空间,分别是hbase和default,hbase中存放的是Hbase内置的表,default表是用户默认使用的命名空间。
- Table:类似于关系型数据库的表概念,不同的是,Hbase定义表时只需要声明列族即可,数据属性,比如超时时间(TTL)、压缩算法(Compression)等,都在列族的定义中定义,不需要声明具体的列。
- Row:一行逻辑数据。Hbase表中的每行数据都是由一个RowKey和多个Column(列)组成。一个行包含了多个列,这些列通过列族来分类,行中的数据所属列族只能从该表所定义的列族中选取,不能定义这个表中不存在的列族,否则报错:NoSuchCloumnFamilyException。
- RowKey:每行数据主键。Rowkey是由用户制定的一串不重复的字符串定义,是一行的唯一标识。数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。如果使用了之前定义的RoeKey,那么会将之前的数据更新掉。
- Column Family(列族):列族是多个列的集合。一个列族可以动态灵活的定义多个列。表的相关属性大部分都定义在列族上,同一个表里的不同列族可以有完全 不同的属性配置,但是同一个列族内的所有列都会有相同的属性。列族存在的意义是Hbase会把相同的列族的列尽快放在同一个机器上,你就给他们定义相同的列族。
- Column Qualifier(列):Hbase中的列是可以随意定义的,一个行中的列不限名字、不限数量,只限定列族。因此列必须依赖于列族存在。列的名称前必须带着所属的列族。例如info:name,info:age。
- TimeStamp(时间戳--版本):用户标识数据的不同版本(version)。时间戳默认由系统指定,也可以由用户显式指定。在读取单元格的数据时,版本号可以忽略,如果不指定,Hbase默认会获取最后一个版本的数据返回。
- Cell:一个列中可以存储多个版本的数据。而每个版本就称为一个单元格(Cell)。
- Region(表的分区):Region由一个表的若干行组成。在Region中行的排列按照行键(Roekey)字典排序。Region不能跨RegionServer,且当数据量大的时候,Hbase会拆分Region。
RowKey的设计原则
- 唯一原则:保证rowkey的唯一性。若Hbase中同一个表插入相同的rowkey,则原先的数据会被覆盖掉,设计RowKey的时候,要充分利用这个排序特点,将经常读取的数据存储到一块,将最近可能被访问的数据放到一块。
- 长度原则:Rowkey长度越短越好,一般不要超过16字节。因为rowkey是一个二进制码流,可以是任意字符串,最大长度64KB,实际应用中一般为10-100字节,以byte[]形式保存,如果过长,会影响存储效率。
- 散列原则:如果用时间戳作为RowKey的前缀会导致大量的数据堆积在一个分区进而导致热点问题。
- 加盐:在rowkey的前面分配随机数,当给rowkey随机前缀后,它就能分布到不同的region中,这里的前缀应该和你想要数据分布的不同region的数量有关。
rand(9)+kay - 预分区:通常hbase会自动处理region拆分,当region的大小到达一定阈值后,region将被拆分成两个,之后再两个region都能继续增长数据。当然这个过程中会出现:热点问题跟拆分合并风暴,压缩重写拆分后的region会引起磁盘的I/O压力。处理方式可以关闭hbase的自动管理拆分,然后手动调用hbase 的split(拆分)和major_compact(压缩),配合加盐,控制每台节点的负载均衡。
--1、手动设定预分区 Hbase> create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000'] --2、生成16进制序列预分区 create 'csdn','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'} --按照文件中设置的规则进行预分区,比如创建文件内容如下 aaaa bbbb cccc dddd --然后执行: create 'staff3','partition3',SPLITS_FILE => 'splits.txt' --4、使用JavaAPI创建预分区 //自定义算法,产生一系列 hash 散列值存储在二维数组中 byte[][] splitKeys = 某个散列值函数 //创建 HbaseAdmin 实例 HBaseAdmin hAdmin = new HBaseAdmin(HbaseConfiguration.create()); //创建 HTableDescriptor 实例 HTableDescriptor tableDesc = new HTableDescriptor(tableName); //通过 HTableDescriptor 实例和散列值二维数组创建带有预分区的 Hbase 表 hAdmin.createTable(tableDesc, splitKeys); - 哈希:在rowkey里面放弃时间戳信息,每次扫描都要扫面全表,或者准确知道rowkey的值单点查询;优点就是够散列,很好解决热点问题,缺点是扫面全表,遍历所有region,耗时。
比如: 原 本 rowKey 为 1001 的 , SHA1 后 变 成 : mm01903921ea24941c26a22f3eec24e0bb0e8ee8 在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的 rowKey 来 Hash 后作为每个分区的临界值。 - 反转:比如手机号、身份证前几位是比较固定的,但是后面位数是随机的,可以将手机号或者身份证反转之后作为rowkey,避免热点问题,但是会牺牲rowkey的有序性。
20240101000001 转成 10000010104202 20240101000002 转成 20000010104202
- 加盐:在rowkey的前面分配随机数,当给rowkey随机前缀后,它就能分布到不同的region中,这里的前缀应该和你想要数据分布的不同region的数量有关。
Hbase整体架构
- Zookeeper
- 实现了HMaster的高可用
- 保存了Hbase的元数据信息,是所有Hbase表的寻址入口
- 对HMster和HRegionServer实现了监控
- HMaster(master)
- 为HRegionServer分配Region
- 维护了整个集群的负载均衡
- 维护集群的元数据信息
- 发现失效的Region,并将失效的Region分配到正常的HRegionServer上
- HRegionServer(RegionServer)
- 负责管理Region
- 接收客户端的读写数据请求
- 切分在运行过程中 变大的Region
- Region
- 每个HRegion由多个Store构成
- 每个Store保存了一个列族(Columns Family),表有几个列族,则有几个Store
- 每个Store由一个MemStore和多个StoreFile组成。
Hbase集群的启动和停止
-
前提条件:先启动Hadoop和zookeeper
-
启动Hbase:start-hbase.sh
-
停止Hbase: stop-hbase.sh
HBase shell基本操作
- 进入Hbase 客户端命令操作界面
hbase shell
- 查看帮助命令
help
- 查看当前数据库中有哪些表
list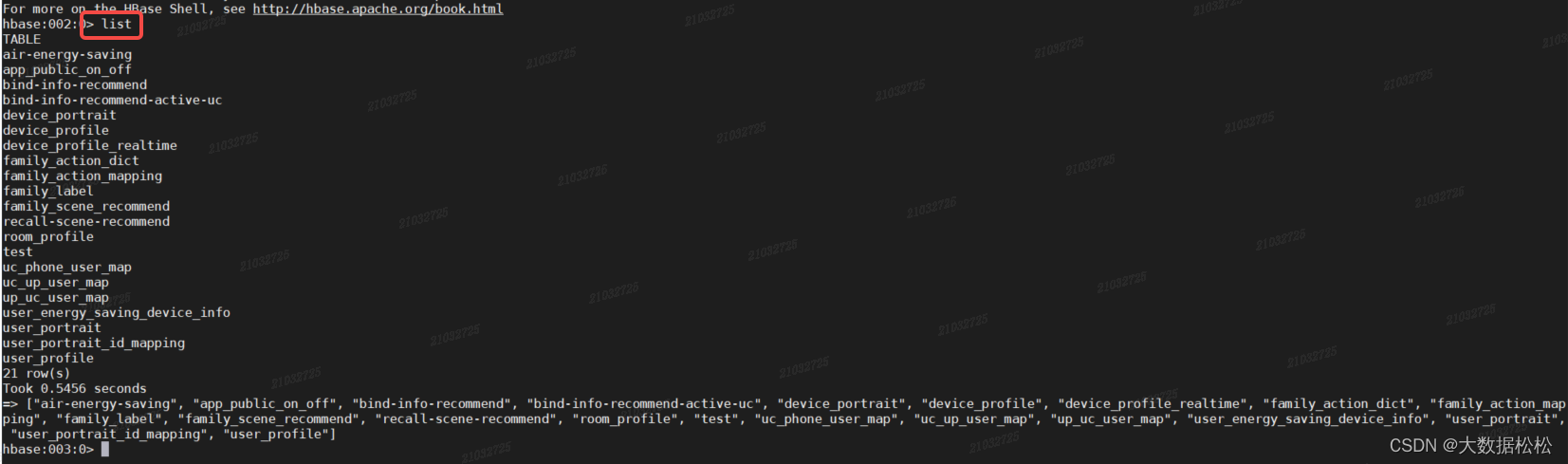
- 查看namespace语句
list_namespace
- 查看某个namespace命名空间下所有的表
list_namespace_tables 'default'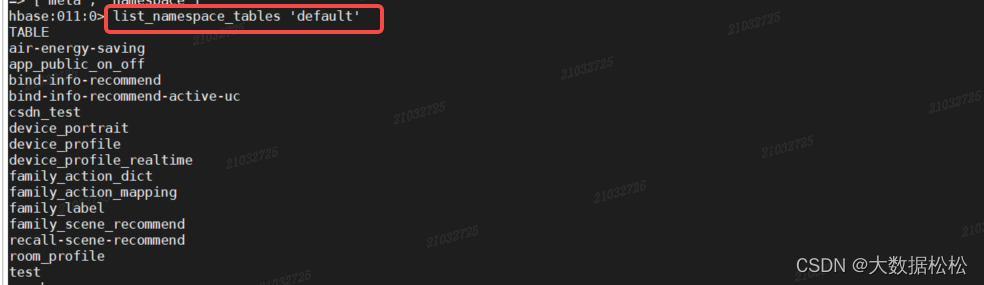
- 创建表语句
create 'csdn_test','base_info','extra_info'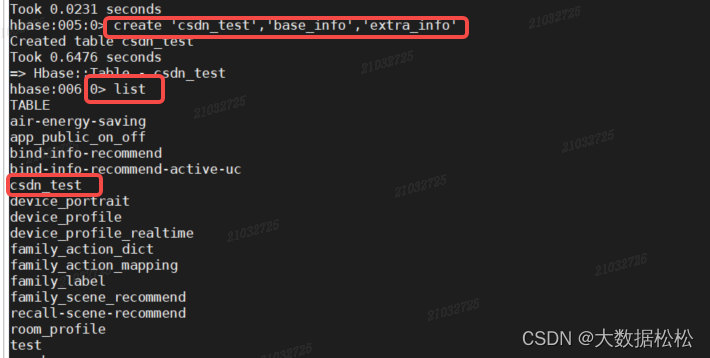
- 查看数据表
desc 'csdn_test'
- 激活并查看数据表状态
enable 'csdn_test' --激活表 is_enabled 'csdn_test' --查看表是否激活 is_disabled 'csdn_test' --查看表是否失效
- 添加数据语句
put 'csdn_test' , 'rk1','base_info:name','songsong' --向csdn_test表中插入rowKey为 rk1,列族为base_info中添加name列,值为songsong put 'csdn_test','rk1','base_info:age',18 --向csdn_test表中插入rowkey为rk1,列族为base_info的列age中插入 18 put 'csdn_test','rk1','base_info:address','beijing' --向csdn_test表中插入rowkey为rk3,列族为base_info的列address中插入 beijing put 'csdn_test','rk1','extra_info:prefer','美女'
- 查询数据语句
scan 'csdn_test' --查看全表 get 'csdn_test','rk1' --查看rowkey为rk1的详细信息 get 'csdn_test','rk1','base_info' --查看rk1某一列族的信息 get 'csdn_test','rk1','extra_info:prefer' --查看某一列族的某一个列值 scan 'csdn_test' ,{COLUMN => 'base_info'} --按照列族查看数据 scan 'csdn_test',{COLUMN => 'base_info',STARTROW => 'rk1' ,ENDROW => 'rk3'} --查询csdn_test表中列族为base_info,rk范围是[rk1, rk3)的数据(rowkey底层存储是字典序) --按rowkey顺序存储 scan 'csdn_test',{LIMIT => 10} --随机查看十条记录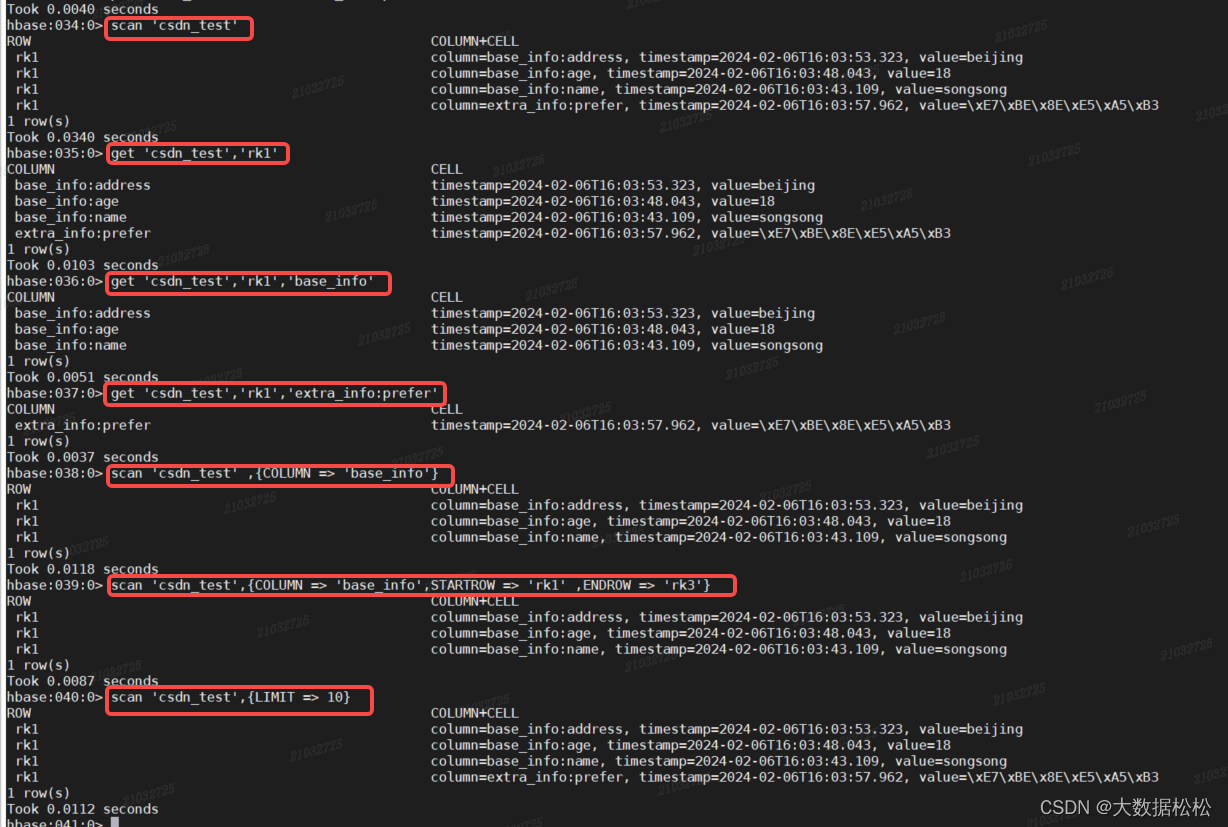
- 更新数据:同插入数据,会自动update
- 删除数据
delete 'csdn_test' ,'rk1','base_info:name' --删除rk1的base_info列族中的name列 alter 'csdn_test','delete' => 'extra_info' --删除列族extra_info truncate 'csdn_test' --清空数据 disable 'csdn_test' --表失效 drop 'csdn_test' --删除表 #如果不进行disable,直接drop会报错 ERROR: Table user is enabled. Disable it first.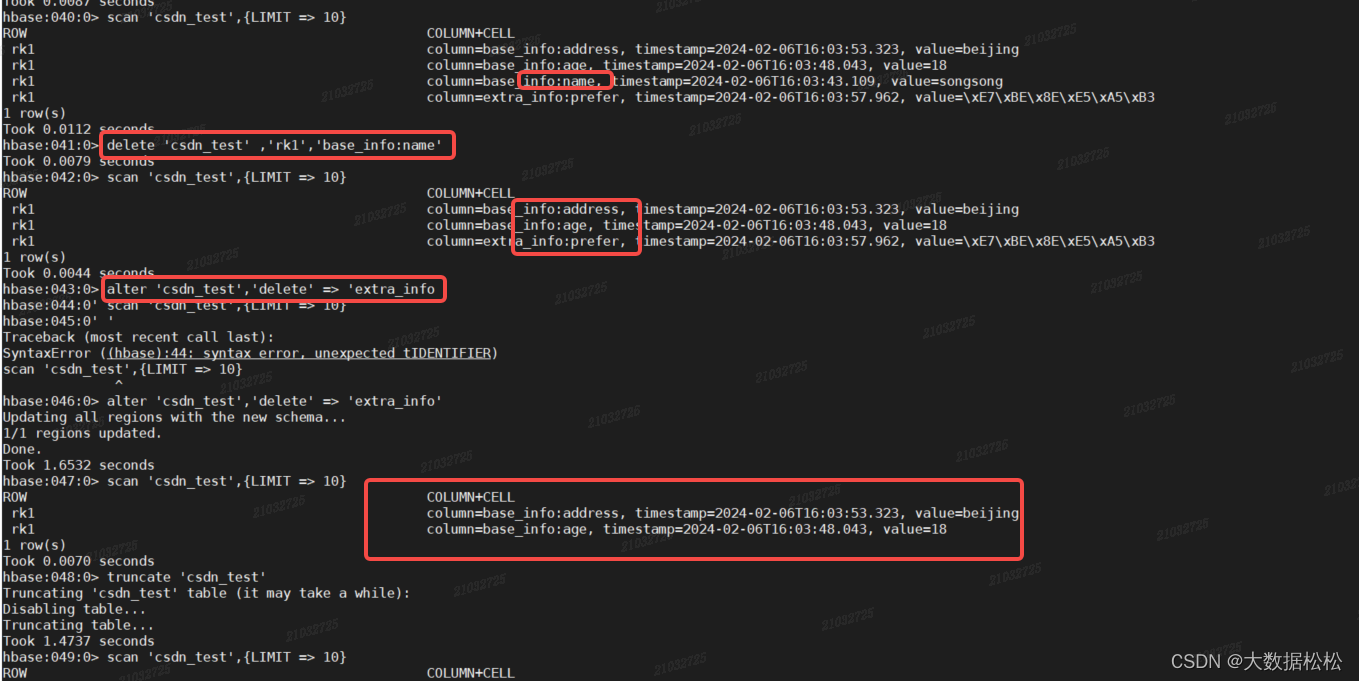



















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











