




 本文详细介绍如何搭建Hadoop完全分布式集群,包括配置多台服务器、设置HDFS和YARN节点、安装Zookeeper及JournalNode,以及启动和测试集群的全过程。
本文详细介绍如何搭建Hadoop完全分布式集群,包括配置多台服务器、设置HDFS和YARN节点、安装Zookeeper及JournalNode,以及启动和测试集群的全过程。
要搭建起一个hadoop完全分布式集群至少需要3台机器,各个机器上分别运行哪些节点,要运行的节点都有什么,现在梳理如下:

针对上面表格的名词解释:
node112: ip 为192.168.28.112的centos7服务器
node113: ip 为192.168.28.113的centos7服务器
node114: ip 为192.168.28.114的centos7服务器
nn:namenode,属于hdfs,相当于hdfs的老大
dn:datanode,属于hdfs,相当于hdfs的小弟
zk:zookeeper,负责hdfs的高可用(本质是nn的高可用)
zkfc:zookeeper failoverController(java程序,用来监听zk,实现nn挂掉后自动切换到备份的nn)
jn:journalnode(负责active的nn与standby的nn之间数据的同步)
rm:resourcemanager,属于yarn,相当于yarn的老大,可以跟主nn在一台机器上,考虑到rm和nn都是吃内存比较多,也可以分开机器来放,
注意:Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在配置为ResouceManager所在的机器上启动yarn。
nm:nodemanage,属于yarn,相当于yarn的小弟
yarn:hadoop2.x里才引入的资源管理器,mapreduce运行在yarn上,mr需要的cpu、内存等的调整都是由yarn来控制。
为甚么要这么设计搭建?
其实各个节点在服务器上怎么分布,没有一定的准则,但是也有几个原则要遵守:
两个nn不能在一台机器上;
dn至少也要3台机器吧,再说zk与jn的集群都要求是奇数个机器,最小也就是3台机器了;
zkfc是zk与nn之间的桥梁,zkfc会分别想zk与nn发送心跳以判断nn是否处于正常状态,必须要和nn在同一个机器上,有nn的机器就有zkfc;
nm一般要和dn对应起来,nm没有地方来配置它,只要改机器时dn,那么就是nm,nm就是用来管理dn的,dn的配置是在slaves文件里面。
基于上述原则才有了上边各个节点的分布表格。
现在开始配置hadoop2.6.5完全分布式集群的搭建。因为前边已经详细的讲过hadoop2.6.5伪分布式的搭建,因此这里不会再这么啰嗦。
node113上的操作:
一、vi /etc/hosts,加入如下内容:
192.168.28.112 node112 192.168.28.113 node113 192.168.28.114 node114
二、配置免密码登录,参考本人其他文章
三、mkdir -p /usr/local/hadoop
四、tar -zxvf hadoop-2.6.5_x64.tar.gz -C /usr/local/hadoop
五、cd /usr/local/hadoop/hadoop-2.6.5/etc/hadoop/
六、vi hadoop-env.sh:
export JAVA_HOME=/usr/local/java/jdk1.7.0_80
七、vi hdfs-site.xml:
<!--配置服务名--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--配置nn的名字,nn1和nn2这里是任意命名的--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--配置两个nn的rpc,rpc端口用于nn与client和dn的交互--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node112:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node113:8020</value> </property> <!--配置两个nn的http端口,http端口是hdfs后台管理的端口--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node112:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node113:50070</value> </property> <!--配置journalnode的url地址,jn用于同步两个nn之间的数据,两个nn一个是active,一个是standby--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node112:8485;node113:8485;node114:8485/mycluster</value> </property> <!--客户端使用下面的类找到active nn,固定的--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--配置私钥,文件名是什么就些什么--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!--配置jn的工作目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/hadoop/jnwork</value> </property> <!--配置自动切换(也允许手工切换)--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!--配置副本数,与dn个数一致--> <property> <name>dfs.replication</name> <value>3</value> </property>
八、创建jn的工作目录: mkdir -p /usr/local/hadoop/jnwork
九、vi core-site.xml:
<!--配置nn的入口(mycluster表示你前边配置的集群名字),原先伪分布式时配置的是hdfs://node113:9000--> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!--配置zk所在机器--> <property> <name>ha.zookeeper.quorum</name> <value>node112:2181,node113:2181,node114:2181</value> </property> <!--配置hadoop的工作目录--> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/data</value> </property> <property> <name>ipc.client.connect.max.retries</name> <value>100</value> </property> <property> <name>ipc.client.connect.retry.interval</name> <value>10000</value> </property>
十、mkdir -p /usr/local/hadoop/data
十一、slaves文件里面配置了datanode所在机器,journalnn替代了secondary nn,这点要知道,现在我们编辑slaves文件,vi slaves:
node112 node113 node114
十二、vi mapred-site.xml:
<!--指定mr放在yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
十三、vi yarn-site.xml:
<!--配置rn所在机器--> <property> <name>yarn.resourcemanager.hostname</name> <value>node113</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
十四、zk的安装,参考本人其他文章
十五、在node112和node114上重复1-14步的操作
十六、在安装了zk的机器上(node112,node113,node114)上分别启动zk,./zkServer.sh start
十七、在准备作为jn节点的机器上(node112,node113,node114)上分别执行 "./sbin/hadoop-daemon.sh start journalnode "来启动jn节点,并通过jps来查看是否启动成功.
在启动了zk和jn之后,三台机器上的jps查看java进程的情况分别如下所示:
node112:

node113:

node114:

其中,QuorumPeerMain是zk的进程,JournalNode是jn的进程。
十八、在任意一台nn上执行,这里选择node113: ./bin/hdfs namenode -format,在hadoop工作目录(/usr/local/hadoop/data)查看下fsimg是否生成了。
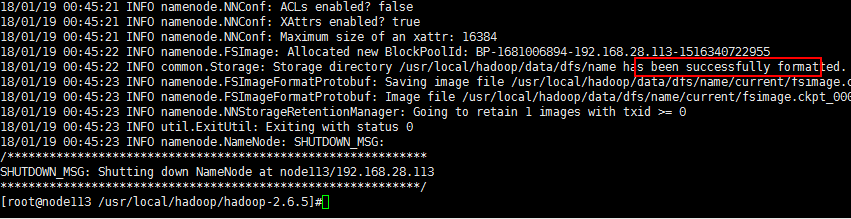
十九、启动(否则第二十步执行不成功)已经格式化过的nn:./sbin/hadoop-daemon.sh start namenode, 并通过jps来查看是否有相应java进程启动。
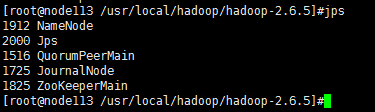
可以看到多了NameNode进程已经启动了,另外又多了个ZooKeeperMain进程。
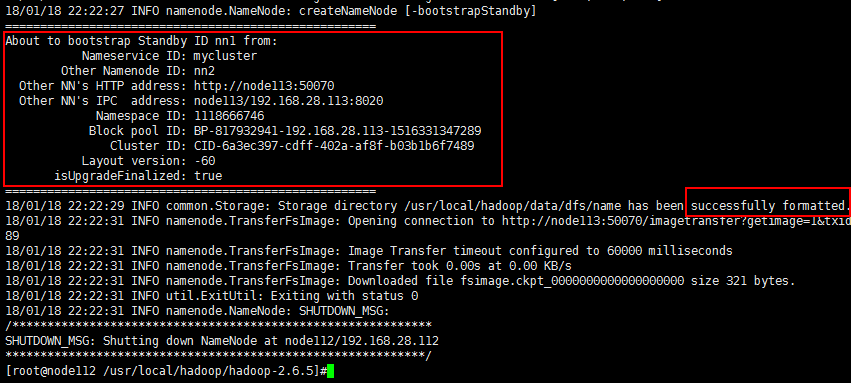
二十、在没有格式化的nn上执行命令,用以拷贝已经启动的nn上的fsimg,该命令是:./bin/hdfs namenode -bootstrapStandby 。执行完之后为确保万一,还是建议到hadoop工作目录(/usr/local/hadoop/data)查看下fsimg是否生成了。执行命令结果如下:
二十一、在node113上执行 ./bin/hdfs zkfc -formatZK ,这个命令会在zk上创建一个znode节点,作用就是用来检测与该znode节点对应的nn是否处于active状态。下图为该命令的部分输出信息:

那么我现在在3台机器上任意找一台安装了zk的机器,通过./zkCli.sh登录,查看一下是否有znode节点创建呢?
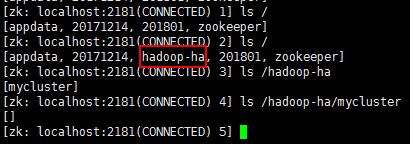
发现hadoop-ha这个节点已经被创建了,说明没有问题。
梳理一下现在3台机器上节点的启动情况:
[root@node112 /usr/local/hadoop/hadoop-2.6.5]#jps 8665 JournalNode 8830 Jps 8478 QuorumPeerMain
[root@node113 /usr/local/hadoop/hadoop-2.6.5]#jps 1912 NameNode 2100 Jps 1516 QuorumPeerMain 1725 JournalNode 1825 ZooKeeperMain
[root@node114 /usr/local/hadoop/hadoop-2.6.5]#jps 8639 JournalNode 8454 QuorumPeerMain 8718 Jps
二十二、好,现在配置基本差不多了,我们先把已经启动的jn(第十七步)和nn(第十九步)关闭掉,在node113(原先启动nn就是在node113执行的,两台机器都有nn,node112执行的./bin/hdfs namenode -bootstrapStandby,所以node113相当于主nn,./sbin/stop-dfs.sh 需要在active的主nn上执行)上执行命令: ./sbin/stop-dfs.sh
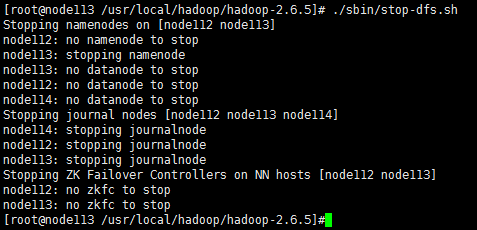
二十三、好现在如果没有问题的话就大功告成了,现在总共有node112,node113,node114共三台机器,在角色为主的acitve的namenode上(这里是node113)执行:
23.1 “ ./sbin/start-dfs.sh”就可以了,它会依次启动 nn,dn,jn,zkfc这些hdfs节点,下面为输出信息:
[root@node113 /usr/local/hadoop/hadoop-2.6.5]# ./sbin/start-dfs.sh Starting namenodes on [node112 node113] node112: starting namenode, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-namenode-node112.out node113: starting namenode, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-namenode-node113.out node114: starting datanode, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-datanode-node114.out node113: starting datanode, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-datanode-node113.out node112: starting datanode, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-datanode-node112.out Starting journal nodes [node112 node113 node114] node114: starting journalnode, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-journalnode-node114.out node113: starting journalnode, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-journalnode-node113.out node112: starting journalnode, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-journalnode-node112.out Starting ZK Failover Controllers on NN hosts [node112 node113] node113: starting zkfc, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-zkfc-node113.out node112: starting zkfc, logging to /usr/local/hadoop/hadoop-2.6.5/logs/hadoop-root-zkfc-node112.out
23.2 “ ./sbin/start-yarn.sh”就可以了,它会依次启动 rm,nm这些yarn节点,下面是输出信息:
[root@node113 /usr/local/hadoop/hadoop-2.6.5]#sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/hadoop-2.6.5/logs/yarn-root-resourcemanager-node113.out
node114: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.6.5/logs/yarn-root-nodemanager-node114.out
node112: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.6.5/logs/yarn-root-nodemanager-node112.out
node113: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.6.5/logs/yarn-root-nodemanager-node113.out
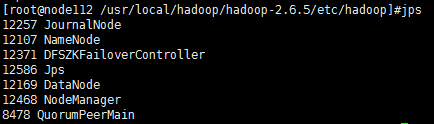
二十四、在三台机器上通过jps命令查看,看看与预先计划的各节点分布情况是否一致,查看三台机器的java进程:
node112应该有namenode,datanode,zookeeper,zookeeper failoverController,journalNode,nodemanager共六个进程,下图正好吻合:
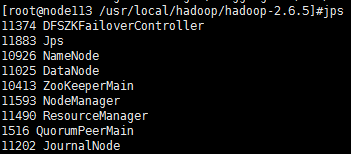
node113应该启动了namenode,datanode,zookeeper,zookeeperfailoverController,zookeeperMain,journalNode,resourcemanager,nodemanager共八个进程:
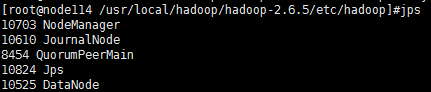
node114应该有datanode,zookeeper,journalNode,nodemanager共四个进程,下图也吻合:
二十五、通过http://node113:50070查看hdfs管理界面:
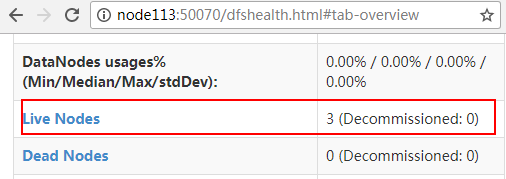
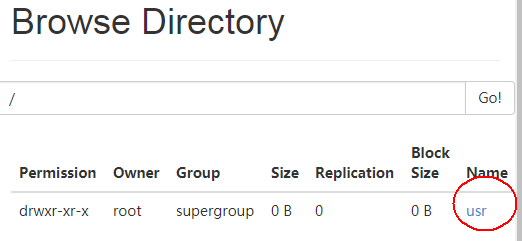
在hdfs工作根目录创建一个文件夹:
./bin/hdfs dfs -mkdir -p /usr/files
创建成功:
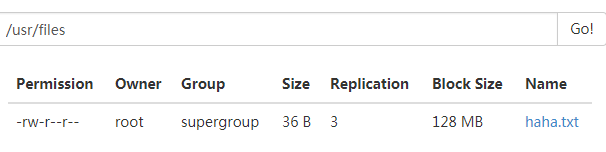
上传一个文件:
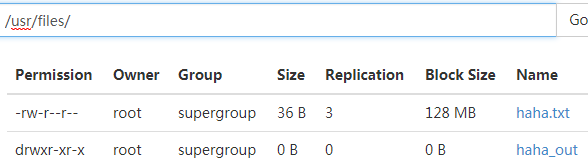
./bin/hdfs dfs -put /root/haha.txt hdfs://mycluster/usr/files/
上传也是成功的:
二十六、访问http://node113:8088查看yarn的管理界面,跑个mr任务看一下是否能正常显示mr任务的信息。
[root@node113 /usr/local/hadoop/hadoop-2.6.5/share/hadoop/mapreduce]#hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount hdfs://mycluster/usr/files/haha.txt hdfs://mycluster/usr/files/haha_out
查看yarn的管理界面:
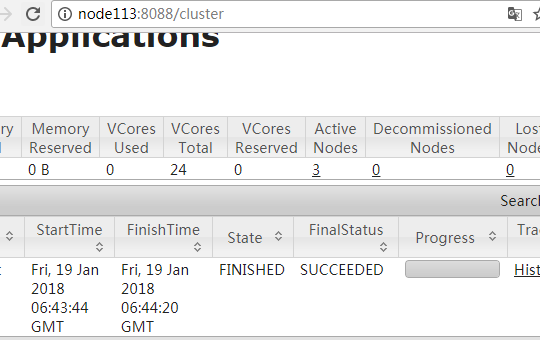
并且hdfs的管理界面也生成了haha_out目录,里面存放着执行结果:
二十七、hdfs和yarn管理着的mr都没有问题了,下篇教程再看看hive在集群中的测试。
总结与注意点:
要先在安装有zk的机器上启动zk,再在node113上执行 ./start-all.sh.而start-all.sh已经过时了,推荐使用./start-dfs.sh和./start-yarn.sh代替它。


















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









