




GA遗传算法
仿生物学交叉和变异
- 交叉:染色体交互位置
- 变异:染色体突变,绿巨人再现
所需的就是提取最优的保留下来,达尔文进化论
二进制编解码
编码
将问题抽象为适用于遗传算法的形式,将数值转换为二进制
用二进制表示十进制
- 给定区间范围
- 给定精度,也就是两个数间隔
- 进行编码,每个数值分配一个独一无二的二进制串
- 串所能表示的数值个数必须要 ≥ 数值解的个数
- 一个长度为n的串,能表示2^n个数
example:
- 区间范围是[1,10],长度为2的串精度(间隔)是多少?
(10-1)/(2^n-1)=3 - 区间长度为L,精度为E的情况下,二进制的串的长度为n,三者的关系是
L/(2^n-1)≤E - 要想达到1e-5的精度,对于区间长度10,串的长度n应该满足
10/(2^n-1)≤0.00001—>n ≥20
解码
索引:当前串是第几个串,可以通过二进制转10进制得到
example:
-
[1,0],10进制转换结果为2,对应数值表示
1+2*3=7 -
[1,1],10进制转换结果为3,对应数值表示
1+3*3=7 -
一般情况下,区间范围是[a,b]且b-a=L,串长为n,当前串的十进制为T,则该串对应的实值解为:
X = a + T * L/(2^n-1)
复制交叉变异
-
复制
- 将个体的适应度映射为概率进行复制,说白了生活能力强的评分高的,更大概率复制,且复制份数越多—
轮盘赌法 - 对适应度高的前N/4的个人进行复制,然后用这些个体把后N/4个体替换—
精英产生精英 - 产生新解的方式多种多样,当然可以随机
- 将个体的适应度映射为概率进行复制,说白了生活能力强的评分高的,更大概率复制,且复制份数越多—
-
交叉
- 按顺序,两两个体之间按概率交叉
- 完全可以相互交叉,3个、5个交叉,前N/2交叉,随机N/2选一个个体交叉,多端交叉都是可以的
-
变异
- 每个个体都进行变异
- 只对适应度低的后N/4,或者后N/2个体变异
- 可以按适应度大小映射变异,多个点位也可以变异
算法实现
策略选型
- 复制:按适应度大小映射为概览,轮盘赌复制
- 交叉:1和2,3和4,一定概率决定是否交叉,如果交叉,则二者选择随机一个段进行交叉
- 变异:按照一定的概率决定该个体是否变异,若变异,随机选择一个位点进行变异:按位取反
算法实现思想
-
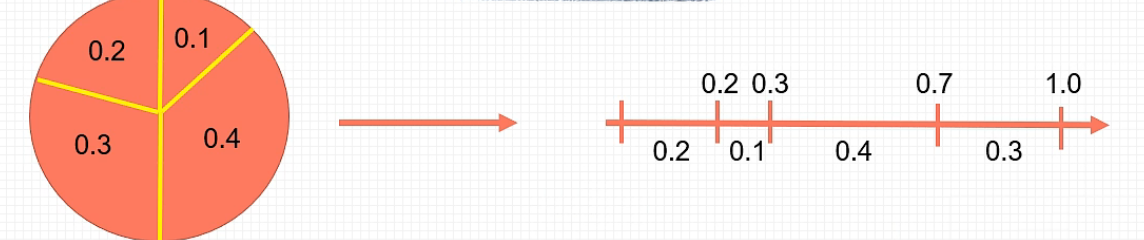
轮盘赌基本思想:适应度越高的解,越应该高概率复制,且复制的份数应该越多
-
exapmle:丢个随机数,看其所在区间范围,如果在0.3—0.7则是属于0.4块,0.4块+1,看其最后每个块的累计和,视频内讲解的其实是归并排序的思想
-
算法拓展
- 启发式的算法背后思想都是择优,好的根据一定策略实现更好,差的根据一定策略向好的发展,若下一次不好,那就保底:
保底机制+更新策略=寻得最优
PSO粒子群优化算法
已知A为全局最优,B和C如何移动才能到达A处,可以用数学去表达
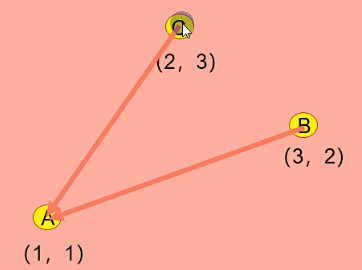
- 某个粒子点的移动,是有大小和方向的,想想向量
- example
- 上图就是(2,3)到(1,1),也就是(1,1)=(2,3)+(-1,-2)
- 推广也就是(x,y)=(2,3)+ rand *(-1,-2)
基本原理总结
-
D维空间内,N个粒子组合一个群体,其中第i个粒子用Xi(xi1,xi2,…xiD)表示
-
第i个粒子的飞行速度也是一个D维向量,用Vi(vi1,vi2,…viD)表示,一般会设置最大值
-
在第t代的第i个粒子向第t+1代进化时,会有如下机制更新
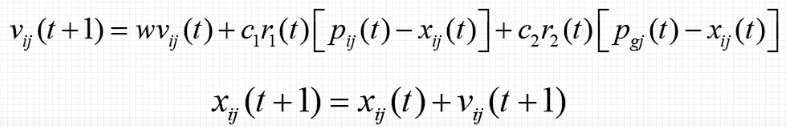
- wvij:惯性思想,w是惯性权重,一般是0.5-0.8
- 解释下,惯性就是按照上一次的方向
- pij:个体方向,c1是个体学习系数,一般是0.1-2
- 解释下,个体就是指自己单个粒子中最优的点
- pgj:全局方向,c2是全局学习系数,一般是0.1-2
- 解释下,全局指的就是多个粒子共同去找的最优的
- wvij:惯性思想,w是惯性权重,一般是0.5-0.8
-
example
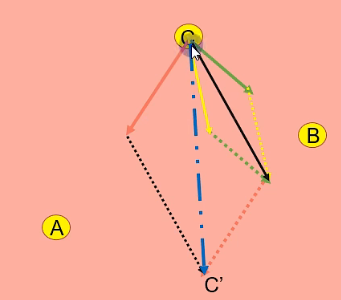
- 上图黄线就是惯性,B点是个体C的下一个要去的点,A是全局最优
- 黄线先和绿线合成为黑线,黑线再和橘线合成为蓝色虚线,蓝色虚线为最终结果C‘
- 当然如果C’还没现在好(适应度比较),就不动,还是在C点(保底机制)
- 解释下,适应度就是优化目标,一般都是优化损失函数越小,对应的适应度也就越高


















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











