




目录
一、Kafka 是什么?
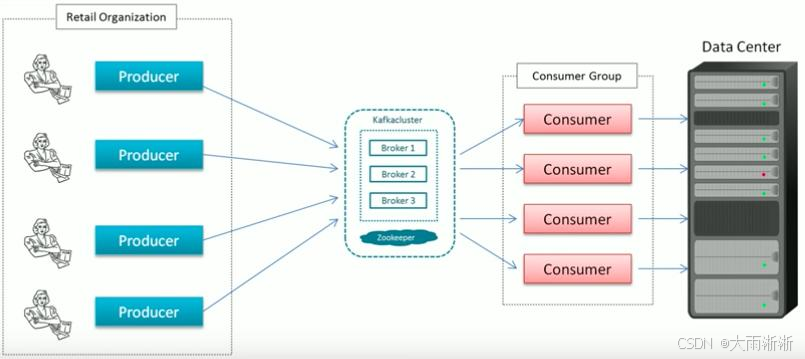
在当今数字化时代,分布式系统如同一张紧密交织的大网,将各种应用、服务和组件连接在一起。但随着系统复杂度的不断攀升,各个模块之间的通信问题也日益凸显,就好比城市交通,车流量一大,道路就容易拥堵,信息传输也变得迟缓甚至混乱。这时候,消息队列就像是一位智能交通指挥官闪亮登场,Kafka 则是其中的佼佼者。
Kafka 是一个分布式流处理平台,最初由 LinkedIn 开发,后捐赠给 Apache 基金会,成为了一个开源的顶级项目。它就像一条无比高效的信息高速公路,能够以惊人的速度处理海量消息,在大数据处理、实时数据传输等场景中表现卓越 ,是大数据领域的 “宠儿”。每秒几十万条的消息吞吐量,让其他消息队列望尘莫及。当面对海量日志采集、实时数据传输等场景时,Kafka 的优势就凸显出来了。想象一下,电商平台在促销活动期间,用户的浏览、下单、支付等行为数据如雪片般涌来,Kafka 可以轻松承接,快速将这些数据传递给后续的数据处理系统,确保实时分析、监控等功能不受影响,稳稳保障系统高效运行。 不仅如此,它还具备强大的可扩展性,其架构如同一个紧密协作的 “数据联邦”,由多个 Broker 组成集群,Topic 又能细分为多个分区,数据均匀分布在各个节点上。这种精妙设计使得它可以像搭积木一样,便捷地横向扩展。随着业务增长,数据量飙升,只需简单添加新的 Broker 节点,就能轻松应对,完全不用担心性能瓶颈。许多大型互联网公司,每日要处理数十亿条消息,依靠 Kafka 强大的扩展性,数据洪流被有序分流,系统平稳运行,为业务的持续拓展提供坚实支撑。
二、为什么要学习 Kafka
在当今数字化时代,数据如潮水般涌来,每秒产生的数据量堪称海量。而 Kafka,作为消息队列领域的佼佼者,以其卓越的性能、强大的功能和广泛的应用场景,成为众多开发者和企业的首选。学习 Kafka,不仅能提升个人技术实力,还能为实际项目带来极大的帮助。
(一)性能卓越,应对海量数据
Kafka 具有令人惊叹的高吞吐量,每秒能够处理几十万甚至数百万条消息 ,这得益于它独特的设计。在数据写入方面,Kafka 采用顺序写磁盘的方式,避免了随机读写的性能瓶颈。以电商平台为例,在 “双 11” 这样的购物狂欢节期间,大量的订单、支付、物流等消息如潮水般涌来。Kafka 能够轻松应对如此巨大的数据流量,快速地将这些消息写入磁盘,为后续的处理提供坚实保障。同时,Kafka 的零拷贝技术减少了数据在内存中的拷贝次数,大大提高了数据传输效率。在数据读取时,消费者可以以极快的速度从 Kafka 中拉取消息,实现低延迟的数据处理。在实时监控系统中,Kafka 能够快速地将监控数据传递给分析模块,让运维人员能够及时发现并解决问题。
(二)分布式架构,轻松实现扩展
Kafka 天生就是为分布式环境设计的,其分布式架构具有强大的扩展性。一个 Kafka 集群可以由多个 Broker 组成,每个 Broker 负责存储和处理一部分数据。当业务量增长时,只需简单地添加新的 Broker 节点,Kafka 就能自动将数据分布到新节点上,实现集群的无缝扩展。许多大型互联网公司,如阿里巴巴、腾讯等,每天都要处理海量的数据。它们通过使用 Kafka 的分布式架构,能够轻松应对数据量的增长,保证系统的稳定运行。此外,Kafka 的分区机制将一个 Topic 的数据分散到多个 Partition 中,不同的 Partition 可以分布在不同的 Broker 上,进一步提高了系统的并行处理能力和吞吐量。在大规模日志收集系统中,通过将日志数据按照不同的业务类型或时间进行分区存储,Kafka 能够高效地处理和管理这些日志数据。
(三)数据持久化,确保可靠存储
Kafka 将消息持久化到磁盘上,这意味着即使在系统出现故障或重启的情况下,消息也不会丢失。Kafka 使用日志文件来存储消息,每个分区对应一个日志文件,消息按照顺序追加到日志文件中。为了提高数据的可靠性,Kafka 还支持数据备份,每个分区可以有多个副本,这些副本分布在不同的 Broker 上。当某个 Broker 出现故障时,Kafka 可以自动从其他副本中恢复数据,确保数据的完整性和可用性。在金融交易系统中,每一笔交易记录都至关重要。Kafka 的数据持久化和备份机制能够保证交易数据的安全存储,即使在系统出现异常的情况下,也能确保数据不丢失,为金融业务的稳定运行提供了有力保障。
(四)广泛应用,提升职业竞争力
Kafka 在大数据处理、实时数据传输、日志收集等领域有着广泛的应用。在大数据处理领域,Kafka 常作为数据的输入和输出源,与 Hadoop、Spark 等大数据框架紧密结合。通过 Kafka,大数据框架可以实时地获取和处理海量的数据,实现数据的实时分析和挖掘。在实时数据传输场景中,Kafka 能够将实时产生的数据快速地传输到各个需要的系统中,实现数据的实时共享和交互。在日志收集方面,Kafka 可以收集和管理各种系统和应用的日志数据,为后续的日志分析和故障排查提供支持。掌握 Kafka 技术,能够让开发者在这些热门领域中如鱼得水,提升自己在职场上的竞争力。许多企业在招聘大数据开发工程师、后端开发工程师等职位时,都将 Kafka 技术列为重要的技能要求之一。
三、Kafka 核心概念剖析
(一)Topic
在 Kafka 的世界里,Topic(主题)就像是一个个不同类型的 “信息仓库”,是对消息进行逻辑分类的关键概念。它就好比图书馆里的不同书架,每个书架存放着不同类别的书籍,而 Topic 则存放着不同类型的消息 。在电商系统中,“订单消息”“物流消息”“用户消息” 等就可以分别对应不同的 Topic。生产者在生产消息时,会将消息发送到指定的 Topic 中,就像把书籍放到对应的书架上;消费者则通过订阅感兴趣的 Topic 来获取消息,如同读者从特定书架上挑选书籍阅读。每个 Topic 可以看作是一个消息队列的抽象,它为生产者和消费者提供了一个统一的交互接口,实现了消息的解耦和异步通信 。通过合理地划分 Topic,可以方便地对消息进行管理和处理,提高系统的可维护性和扩展性。例如,在一个大型的分布式系统中,不同的业务模块可以将各自的消息发送到对应的 Topic 中,其他模块只需订阅自己需要的 Topic,而无需关心消息的具体来源和生产者,从而降低了系统的耦合度。
(二)Partition
Partition(分区)是对 Topic 的进一步逻辑划分,它在 Kafka 的架构中扮演着至关重要的角色。每个 Topic 可以包含一个或多个 Partition,每个 Partition 都是一个有序的、不可变的消息队列 。Partition 的存在,就像将一个大型的仓库划分成多个小仓库,每个小仓库独立存储和管理一部分货物(消息)。当生产者发送消息到 Topic 时,消息会根据一定的分区策略被分配到不同的 Partition 中。常见的分区策略有轮询、按消息 Key 的哈希值分区等。按消息 Key 的哈希值分区时,如果消息的 Key 相同,那么这些消息就会被发送到同一个 Partition 中,这在一些需要保证消息顺序性的场景中非常重要。Partition 的主要作用之一是实现消息的并行处理。由于不同的 Partition 可以被不同的消费者并行消费,所以 Kafka 可以通过增加 Partition 的数量来提高系统的吞吐量和并发处理能力 。在一个实时数据处理系统中,有大量的用户行为数据需要处理,通过将这些数据按照用户 ID 进行分区,不同的消费者可以同时处理不同分区的数据,大大提高了数据处理的速度。此外,Partition 还实现了 Kafka 的水平扩展。当数据量不断增加时,可以通过增加 Partition 的数量来将数据分布到更多的 Broker 节点上,从而突破单机性能的瓶颈,实现系统的水平扩展 。比如,一个电商平台在促销活动期间,订单数据量剧增,通过增加订单 Topic 的 Partition 数量,并将这些 Partition 分布到更多的 Broker 上,就可以轻松应对大量订单数据的处理需求。
(三)Broker
Broker 是 Kafka 集群中的服务节点,它就像是一个繁忙的物流中转站,负责消息的存储和转发,是 Kafka 系统的核心组件之一 。Kafka 集群由多个 Broker 组成,每个 Broker 都可以存储多个 Topic 的多个 Partition 的数据 。当生产者发送消息到 Kafka 集群时,消息会被发送到某个 Broker 上,并存储在对应的 Partition 中;当消费者从 Kafka 集群拉取消息时,也是从 Broker 上获取消息。Broker 不仅负责消息的存储,还承担着消息分发的重要职责 。它会根据消费者的订阅信息,将消息准确无误地传递给相应的消费者。在一个分布式消息系统中,可能有多个消费者订阅了同一个 Topic,Broker 会根据一定的负载均衡策略,将消息均匀地分发给这些消费者,以提高系统的整体吞吐量 。例如,在一个实时监控系统中,有多个监控客户端订阅了 “系统状态消息” 的 Topic,Broker 会将系统状态消息及时地分发给各个监控客户端,确保它们能够实时获取系统的最新状态。此外,Broker 还支持数据的冗余备份,每个 Partition 都可以有多个副本,这些副本分布在不同的 Broker 上 。当某个 Broker 出现故障时,其他 Broker 上的副本可以接替其工作,保证系统的高可用性和数据的可靠性 。以金融交易系统为例,交易数据的可靠性至关重要,通过在多个 Broker 上存储交易数据的副本,即使某个 Broker 发生故障,也能确保交易数据不丢失,交易业务能够正常进行。
(四)Producer 与 Consumer
Producer(生产者)和 Consumer(消费者)是 Kafka 中与消息生产和消费密切相关的两个角色。Producer 负责将消息发送到 Kafka 集群中,它就像是一个勤奋的 “快递员”,不断地将各种 “包裹”(消息)投递到 Kafka 这个 “物流中心” 。在实际应用中,Producer 会根据业务需求,将各种类型的消息发送到指定的 Topic 中。在一个日志收集系统中,各个应用程序会作为 Producer,将产生的日志消息发送到 Kafka 的 “日志 Topic” 中。Producer 在发送消息时,有一些关键的配置参数需要关注。acks 参数用于控制消息发送的确认机制,它有三个取值:0、1 和 all 。当 acks=0 时,Producer 不会等待任何确认,直接发送消息,这种方式发送速度最快,但消息可靠性最低;当 acks=1 时,Producer 会等待 Leader 节点确认消息后再发送下一条消息;当 acks=all 时,Producer 会等待所有副本节点都确认消息后再发送下一条消息,这种方式消息可靠性最高,但延迟也会增加 。此外,retries 参数用于控制消息发送失败时的重试次数,batch.size 参数用于控制消息的批量发送,compression.type 参数用于控制消息的压缩方式等 。合理地配置这些参数,可以提高消息发送的效率和可靠性。
Consumer 则负责从 Kafka 集群中拉取消息并进行消费,它就像是一个 “收件人”,从 Kafka 这个 “物流中心” 领取自己需要的 “包裹”(消息) 。在一个数据分析系统中,Consumer 会从 Kafka 中拉取用户行为数据,然后进行分析处理。Consumer 在消费消息时,也有一些重要的配置参数 。group.id 参数用于标识消费者所属的消费组,同一个消费组内的消费者会共同消费一个或多个 Topic 的消息,并且一个分区只能被同一个消费组内的一个消费者消费 。这样可以实现消费者之间的负载均衡和容错 。auto.offset.reset 参数用于控制消费者在启动时的消费位置,它有两个取值:earliest 和 latest 。当 auto.offset.reset=earliest 时,消费者会从最早的消息开始消费;当 a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1705
1705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











