




目录
一、什么是 K8s
想象一下,你经营着一家繁忙的餐厅,厨房是你的 “数据中心”,厨师们是一个个 “容器”,每个厨师都在自己的 “容器” 里施展厨艺,精心准备着各种美味佳肴。
当用餐高峰来临,食客们的订单如潮水般涌来,你需要确保每个厨师都能高效地工作,同时合理分配任务,让菜品能够及时、准确地送到食客面前。这时候,你就需要一个 “餐厅管理大师”,他能够统筹规划,合理安排每个厨师的工作,确保整个厨房的运转有条不紊。
K8s 就像是这个 “餐厅管理大师”,只不过它管理的不是餐厅,而是容器。它是一个开源的容器编排系统,用于自动化部署、扩展和管理容器化应用程序。简单来说,K8s 可以帮助你更轻松地管理容器,让它们在集群中协同工作,就像厨师们在厨房里默契配合一样。
K8s 的全称是 Kubernetes,这个名字来源于希腊语,意为 “舵手” 或 “飞行员”,寓意着它能够像熟练的舵手掌控船只一样,精准地掌控容器化应用的运行。而 K8s 这个简称,则是因为 Kubernetes 这个单词太长,中间有 8 个字母,社区就用 8 来代替,是不是很有趣呢?
二、K8s 诞生背景与发展历程
在 K8s 出现之前,传统的应用部署方式可谓是困难重重。就好比你要组建一支足球队,传统部署方式就像是你要为每个球员分别准备一套完全独立的训练场地、装备和后勤保障,不仅成本高昂,而且管理起来极为复杂。一旦有球员受伤或者战术调整,整个体系都要大动干戈 。
具体来说,传统部署中应用的运行、配置、管理和所有生命周期都与当前操作系统紧密绑定。这就导致应用的升级更新、回滚等操作变得异常艰难。比如,你要更新一个应用的版本,可能需要重新安装整个操作系统以及相关依赖,这不仅耗时费力,还容易出现兼容性问题。而且,应用迁移也非常麻烦,如果要将应用迁移到一台新机器,几乎需要从头再来一遍,就像把整个足球队搬到一个新的城市,所有的基础设施都要重新搭建。
为了解决这些问题,容器技术应运而生。容器就像是一个个标准化的 “集装箱”,它可以将应用及其所有依赖项打包成一个独立的可运行单元。每个容器之间相互隔离,有自己的文件系统、网络和进程空间,并且可以共享主机的操作系统内核。这使得应用能够在不同的环境中轻松运行,而无需担心环境差异导致的兼容性问题,就好比把足球队的所有装备和球员都装进标准化的集装箱,无论运到哪里,都能迅速展开训练和比赛。
容器技术具有诸多优势。它非常轻量级,占用的资源更少,因为它不需要启动完整的操作系统。启动速度也极快,可以在几秒钟内启动,不像传统虚拟机需要几分钟的启动时间。同时,容器易于迁移,不受操作系统和硬件的限制,还能动态调整资源使用量,实现横向和纵向扩展。此外,容器之间相互隔离,一个容器的故障不会影响其他容器的运行,并且可以通过镜像来进行复制和部署,确保环境一致性和应用一致性。
随着 Docker 的出现,容器技术迎来了爆发式的发展。Docker 将容器技术推向了广泛关注和应用的高潮,在 DevOps、云计算等领域大放异彩。它引入了一整套管理容器的生态系统,包括高效、分层的容器镜像模型、全局和本地的容器注册库、清晰的 REST API 以及命令行等,为容器化应用的分发和管理提供了全面的解决方案。
然而,当容器的数量不断增加,应用规模逐渐扩大时,新的问题又出现了。就像足球队发展壮大,拥有了多个分队,此时仅靠容器技术就难以高效管理了,我们需要一个更强大的 “教练” 来统筹全局。于是,容器编排技术应运而生,K8s 便是其中的佼佼者。
K8s 的诞生并非偶然,它源自 Google 内部多年的实践经验。Google 在大规模容器管理方面有着丰富的经验,其内部的 Borg 系统为 K8s 的开发提供了重要的借鉴。2014 年,Google 开源了 Kubernetes 项目,将其强大的容器编排能力带给了广大开发者。
自诞生以来,K8s 经历了多个重要的发展阶段。2015 年 7 月,K8s 发布了 1.0 版本,这标志着 K8s 项目达到了一个重要的里程碑,具备了基本的容器编排和管理功能,开始在容器管理领域崭露头角。此后,K8s 不断发展壮大,功能也日益完善。在 1.16 版本中,Custom Resource Definitions (CRD) 正式发布,这一功能极大地扩展了 K8s 的灵活性和可扩展性,允许用户自定义资源类型,满足各种复杂的应用场景需求。到了 1.23 版本,K8s 推出了全面双栈支持,进一步提升了其网络性能和兼容性,使其能够更好地适应不同的网络环境。
如今,K8s 已经成为容器编排领域的事实标准,被广泛应用于各种规模的企业和项目中,为容器化应用的高效管理提供了坚实的保障,就像一位金牌教练,带领着容器化应用在数字化的赛场上屡创佳绩。
三、K8s 核心概念与组件
3.1 Pod:最小部署单元
在 K8s 的世界里,Pod 是最小的可部署和可管理的计算单元,就像是一个 “魔法盒子”,里面可以装一个或多个紧密相关的容器 。这些容器共享相同的网络命名空间、存储卷等资源,它们在这个 “盒子” 里协同工作,就像住在同一间公寓里的室友,共享客厅、厨房等公共区域。
举个例子,在一个电商应用中,我们可以把负责处理用户请求的 Web 容器和存储常用数据的缓存容器放在同一个 Pod 里。Web 容器就像是商店的前台,负责接待顾客(处理请求),缓存容器则像是商店的小仓库,存放着常用的商品信息(数据),它们通过localhost就能轻松通信,高效地为用户提供服务 。
Pod 具有短暂性,它可以被创建、启动、停止、销毁。如果 Pod 中的所有容器都终止,Pod 就会被认为已经完成任务。Kubernetes 负责将 Pod 部署到集群中的节点上,并确保它们运行在可用的资源上,这包括 CPU、内存等。同时,Pod 可以通过控制器(如 Deployment、StatefulSet)进行管理,这些控制器负责定义、创建、更新和删除 Pod 。
3.2 Node:工作节点
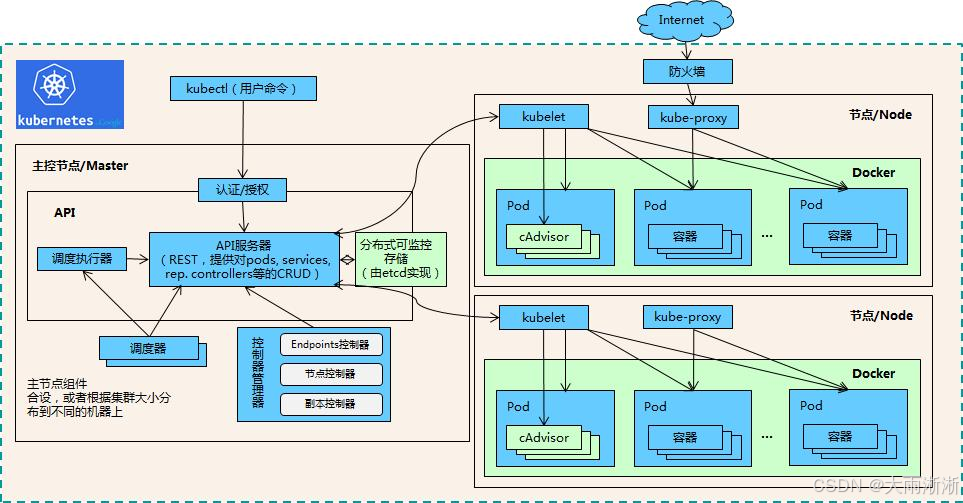
Node 是 K8s 集群中的工作节点,它可以是物理机,也可以是虚拟机,就像是一个个勤劳的 “小蜜蜂”,承担着运行 Pod 的重任 。每个 Node 上都运行着 Kubernetes 的 kubelet、kube-proxy 服务进程,这些服务进程负责 Pod 的创建、启动、监控、重启、销毁,以及实现软件模式的负载均衡器。
其中,kubelet 是运行在每个 Node 上的代理,它负责与 Master 节点通信,确保节点上运行的容器处于预期状态,就像是 Node 的 “大管家”,时刻关注着 Pod 的一举一动。kube-proxy 则负责维护节点上的网络规则,以及为服务提供负载均衡和代理功能,以确保服务之间的网络通信,它就像是一个智能的 “交通警察”,指挥着网络流量的走向 。
Node 包含的信息有 Node 地址(主机的 IP 地址,或 Node ID)、Node 的运行状态(Pending、Running、Terminated 三种状态)、Node Condition、Node 系统容量(描述 Node 可用的系统资源,包括 CPU、内存、最大可调度 Pod 数量等),以及内核版本号、Kubernetes 版本等其他信息。通过kubectl describe node命令,我们可以查看 Node 的详细信息 。
3.3 Service:服务发现与负载均衡
在 K8s 中,Service 是分布式集群架构的核心,它就像是一个 “超级代理”,为 Pod 提供了稳定的访问入口 。每个 Service 都拥有一个唯一指定的名字和一个虚拟 IP(Cluster IP、Service IP、或 VIP)及端口号,通过这个虚拟 IP 和端口号,客户端可以访问到 Service,而 Service 会将请求转发到它所关联的一组 Pod 上。
比如,在一个分布式系统中,有多个 Pod 共同提供用户认证服务。这些 Pod 的 IP 地址可能会因为各种原因(如 Pod 的重启、节点的故障等)而发生变化,这时候如果客户端直接通过 Pod 的 IP 地址来访问服务,就会面临频繁修改配置的问题 。而有了 Service,客户端只需要访问 Service 的虚拟 IP,Service 会自动将请求转发到可用的 Pod 上,实现了服务的负载均衡和高可用性,就像一个智能的转接员,将客户的需求准确地转接到合适的工作人员那里 。
Service 与其后端 Pod 副本集群之间是通过 Label Selector 来实现无缝对接的。通过设置不同的 Label 和 Label Selector,我们可以灵活地将 Service 与不同的 Pod 进行关联。同时,Service 还支持多端口设置,一个容器应用可以提供多个端口的服务,在 Service 的定义中也可以相应地设置多个端口号,以满足不同的业务需求 。
3.4 Deployment:应用部署与管理
Deployment 是 K8s 中用于管理应用部署和生命周期的高级控制器,它就像是一个经验丰富的 “指挥官”,负责指挥 Pod 的创建、更新、回滚等操作 。通过定义 Deployment,用户可以描述一个应用的期望状态,例如需要多少个副本、使用什么镜像以及如何进行滚动更新。Deployment 会根据这些定义自动创建和管理 Pod,确保应用始终处于期望状态 。
比如,我们要部署一个 Nginx 应用,通过创建一个 Deployment 对象,我们可以指定使用 Nginx 的某个镜像,期望运行 3 个副本,并设置滚动更新策略。当我们需要更新 Nginx 的版本时,只需要修改 Deployment 的配置,Kubernetes 会自动按照滚动更新策略,逐步替换旧版本的 Pod 为新版本的 Pod,确保服务在更新过程中持续可用 。
如果在更新过程中发现问题,我们还可以使用kubectl rollout undo命令将 Deployment 回滚到之前的版本,保障应用的稳定运行。此外,我们还可以根据实际需求,使用kubectl scale命令调整 Deployment 中 Pod 的副本数量,实现应用的弹性伸缩 。
3.5 控制平面组件
K8s 的控制平面就像是整个集群的 “大脑”,负责集群的全局决策和状态管理,通常部署在独立的 Master 节点上。它包含以下几个主要组件:
- API Server(kube-apiserver):它是集群的中央枢纽,就像是一个 “总管家”,处理所有 REST 请求(如 kubectl 命令),验证并更新集群状态到 etcd。它提供了 Kubernetes API,是唯一直接与 etcd 交互的组件,并且支持水平扩展,通过多实例实现高可用 。
- Scheduler(kube-scheduler):它是集群中的 “调度员”,负责将未调度的 Pod 分配到合适的 Node 上运行。它基于资源需求(CPU / 内存)、亲和性(Affinity)、污点(Taint)等规则选择节点,以确保 Pod 能够在最合适的节点上运行,实现资源的优化利用 。
- Controller Manager(kube-controller-manager):它是一个 “大管家”,运行多个控制器,确保集群实际状态与期望状态一致。其中,Deployment 控制器负责管理副本数及滚动更新;Node 控制器负责监控节点状态(如宕机时标记为不可用);Service 控制器负责创建云平台负载均衡器(如 AWS ELB);Endpoint 控制器负责维护 Service 与 Pod 的映射关系 。
- etcd:它是一个分布式键值数据库,就像是集群的 “记忆宝库”,存储集群的所有配置和状态数据(如 Pod、Service、Secret 等)。通常以奇数节点(如 3、5)组成集群,通过 Raft 协议保证数据一致性 。
- Cloud Controller Manager(可选):它主要用于集成云平台特性(如负载均衡器、存储卷),仅在公有云环境中需要。比如,它可以自动创建云存储(AWS EBS)或负载均衡器(GCP Load Balancer) 。
这些控制面组件相互协作,共同确保 Kubernetes 集群中的服务和应用程序能够按预期工作。它们之间的协作关系就像是一场精密的交响乐演出,每个组件都扮演着不可或缺的角色,共同奏响了 K8s 集群高效运行的乐章 。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9404
9404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











