






 本文介绍了如何使用Python进行Ajax爬虫,以今日头条为例,讲解了Ajax的基本概念、识别Ajax请求的方法,并详细阐述了通过分析请求URL和设置请求头来抓取并保存图片的过程。
本文介绍了如何使用Python进行Ajax爬虫,以今日头条为例,讲解了Ajax的基本概念、识别Ajax请求的方法,并详细阐述了通过分析请求URL和设置请求头来抓取并保存图片的过程。
一、Ajax简介
Ajax = 异步 JavaScript 和 XML 或者是 HTML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。
Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
二,基本库
import requests
#构造完整链接URL
from urllib.parse import urlencode
import json
import os
三、逻辑分析
怎么样判断该网页使用了Ajax技术,尔不是静态网页。
x-requested-with:XMLHttpRequest
1、访问今日头条网站:https://www.toutiao.com/,鼠标右击网页页面检查或者直接按F12,打开Chrome浏览器打开开发工具,切换到Network选项卡,随后重新刷新页面,可以发现这里出现了非常多的条目,如下图所示:

**** ajax技术的核心是XMLHttpRequest对象(简称XHR),继续找到XHR,选中它,这个选项里的就是动态页面(使用Ajax技术),还可以在今日头条的搜索栏搜索验证,比如搜索一下标题结果中的“街拍”两个字,可以发现在这个请求中有很多匹配的的结果。说明这些内容是由Ajax所加载的。一个页面写明了x-requested-with:XMLHttpRequest,页面由由Ajax所加载。
2.下面就可以分析Ajax请求了,Ajax的数据类型为xhr,这边可以在上面选择XHR,这样显示出来的就都是ajax请求,将网页从上拉到最下,可以看见请求逐渐变多。点击第一个请求,可以在右边看到显示出了不同的信息。
3.复制一下右边的Request URL,可以看到返回了json数据,所以我们的第一步就是分析请求URL,获取返回的JSON数据。点击每个Ajax请求时,可以看到他们的Request URL参数基本相同,唯一有变化的是offset,变化规律为每次多20,所以我们在实现方法是,传入offset作为参数。然后请求的方式为GET。
如下图:

四。图片抓取实现过程
1.,构造URL,补齐所有的参数,然后请求这个链接,如果返回的状态码为200,说明成功了,将结果转化为json模式并返回。
网页的Request URL:
https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset=20&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1578184342289
搞参数,构造URL,分2个部分:使用基础库:from urllib.parse import urlencode #构造完整链接URL
# 基础URL
baseUrl = 'https://www.toutiao.com/api/search/content/?'
# 参数
parameters = {
'aid':'24',
'app_name':'web_search',
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload':'true',
'count': '20',
'en_qc': '1',
'cur_tab':'1',
'from':'search_tab',
'pd': 'synthesis',
'timestamp':timestamp
}
# 构造成一个完整的URL
url = baseUrl + urlencode(parameters) #urlencode方法可以把字典类型转化这就搞定了,快试试哦!
2.再搞个头,不搞或许可以,直接在网页里找到复制一下九可以了,找到Request Headers,如图:
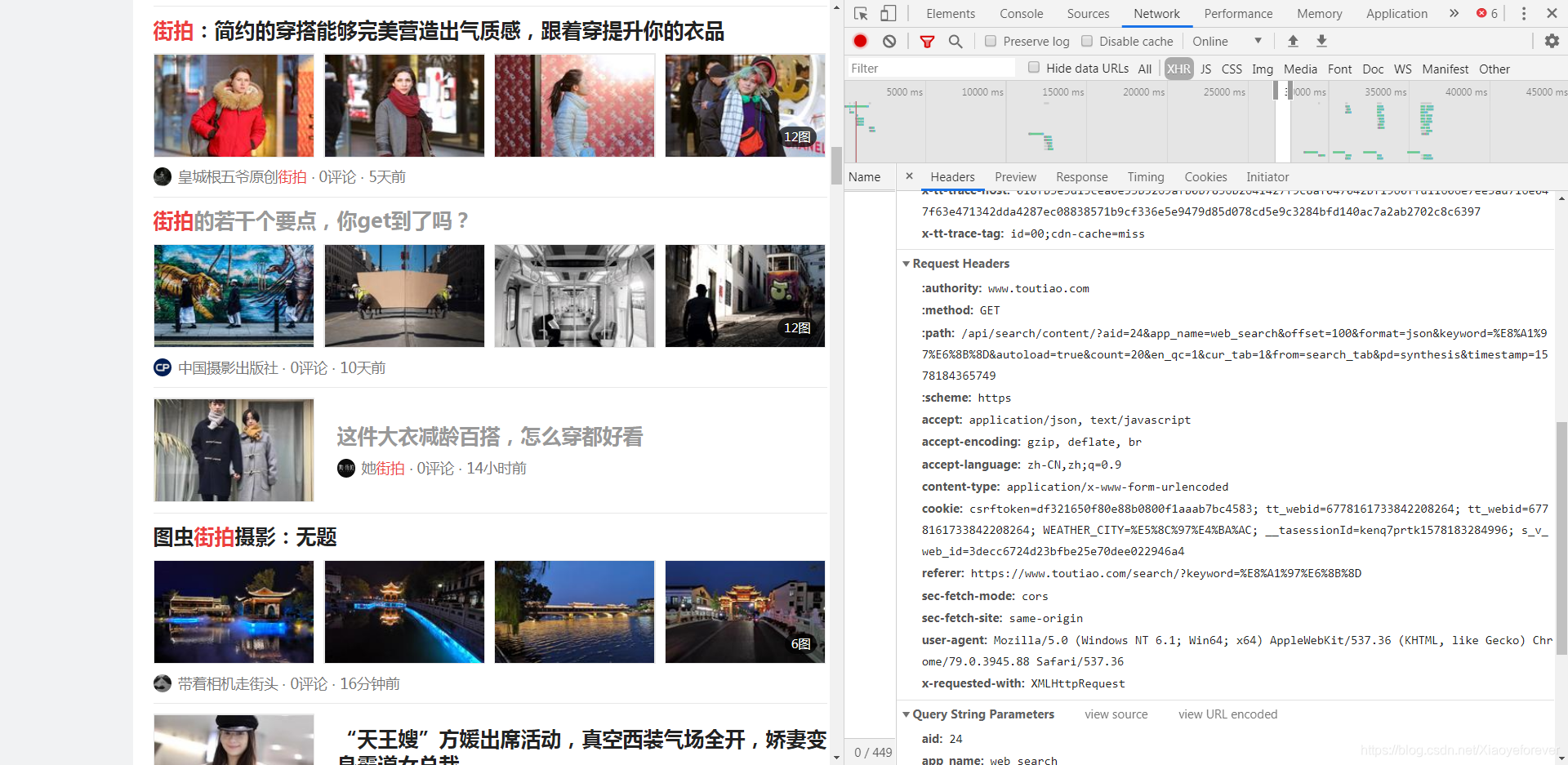
headers={
'authority':'www.toutiao.com',
'accept': 'application/json, text/javascript',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'content-type': 'application/x-www-form-urlencoded',
'cookie': 'csrftoken=bd5052e6c1b37a205ca0115f9f05f8c9; tt_webid=6778031144731543053; s_v_web_id=3decc6724d23bfbe25e70dee022946a4; __tasessionId=wel7sdqjx1578148353942',
'referer':'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}3.后面请求就可以了。。。。(完整代码,图片下载保存到本地文件夹里面)
import requests
#构造完整链接URL
from urllib.parse import urlencode
import json
import os
#请求的Requests Headers头部信息,不加入请求头的话返回的data为null
title_List=[]
img_list=[]
# 初始化__init__方法
def __init__(self,headers):
self.headers=headers
#1.通过ajax请求获取动态索引页面#请求网页具体信息的函数
def get_webPage_index(self,offset,keyword,timestamp):
# 基础URL
baseUrl = 'https://www.toutiao.com/api/search/content/?'
# 参数
parameters = {
'aid':'24',
'app_name':'web_search',
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload':'true',
'count': '20',
'en_qc': '1',
'cur_tab':'1',
'from':'search_tab',
'pd': 'synthesis',
'timestamp':timestamp
}
# 构造成一个完整的URL
url = baseUrl + urlencode(parameters) #urlencode方法可以把字典类型转化
print(url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
html=response.text
# 判断返回的状态码
self.get_page_parameter(html)
return None
except RecursionError:
print('请求索引页出错')
return None
#2.请求页面详情参数解析网页中的数据
def get_page_parameter(self,html_Data):
print("**************html_Data***********", type(html_Data),html_Data)
##将获取的ajax请求转换为json类型的数据 json.loads将已编码的 JSON 字符串解码为 Python 对象 json.dumps将 Python 对象编码成 JSON 字符串
# 将python字典类型变成json数据格式
# 将JSON数据解码为dict(字典)large_image_url
dict_data = json.loads(html_Data)
print("**************dict_data***********",type(dict_data),dict_data)
if dict_data:
for item in dict_data.get('data'):
if item.get('title') and item.get('large_image_url') is not None:
title_List.append(item.get('title'))
img_list.append(item.get('large_image_url'))
print("***********str_title*****************", item.get('title'))
print("***********large_image_url*****************", item.get('image_list'))
for title_Name, img_url in zip(title_List, img_list):
print("***************************************", title_Name, img_url)
self.make_dir(title_Name)
self.save_Img(img_url)
# 2.创建文件夹,需要读取文件夹名称folderName
def make_dir(self, title):
print("EFWEGEHRJRTJTYJTYJTYJTTYJYTJY")
save_path = "D:\\ttt"
folderName = str(title).replace('?', '_')
# print(folderName)
folderName = folderName.strip()
isExists = os.path.exists(os.path.join(save_path, folderName))
if not isExists:
# print(u'建了一个名字叫做', folderName, u'的文件夹!')
os.makedirs(os.path.join(save_path, folderName))
os.chdir(os.path.join(save_path, folderName)) ##切换到目录
return True
else:
# print(u'名字叫做', folderName, u'的文件夹已经存在了!')
return False
# 根据每个页面获取一个页面上所有的图片ip
def save_Img(self,url):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
# 获取图片链接,再去下载图片
try:
img = requests.get(url, headers=headers)
if img.status_code == 200:
print("*******************type(img)**********************", img) # <class 'requests.models.Response'>
f = open("123" + '.jpg', 'ab')
f.write(img.content)
print("&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&",img.content)
f.close()
# 判断返回的状态码
return None
except RecursionError:
print('请求索引页出错')
return None
headers={
'authority':'www.toutiao.com',
'accept': 'application/json, text/javascript',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'content-type': 'application/x-www-form-urlencoded',
'cookie': 'csrftoken=bd5052e6c1b37a205ca0115f9f05f8c9; tt_webid=6778031144731543053; s_v_web_id=3decc6724d23bfbe25e70dee022946a4; __tasessionId=wel7sdqjx1578148353942',
'referer':'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
keyword='街拍'
timestamp='1578163849071'
#实例化
ajax=Ajax_Text(headers)
#调用对象的方法
for page in range(0,21):
if page % 20==0:
ajax.get_webPage_index(page, keyword, timestamp)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









