




 本文介绍如何使用Java爬虫Webmagic爬取优快云文章,包括获取文章列表、分析文章详情页、解析HTML获取文章信息,并展示了实际的爬取效果。
本文介绍如何使用Java爬虫Webmagic爬取优快云文章,包括获取文章列表、分析文章详情页、解析HTML获取文章信息,并展示了实际的爬取效果。
一、背景介绍
本文是基于Webmagic提供的爬虫技术爬取的文章,虽然该技术已不再更新,但是现有的功能不影响正常使用,这点还是非常棒的,使用方面的问题直接看官方文档就行了,我这里只介绍个人爬取csdn的文章介绍。
官网中文文档地址是:http://webmagic.io/docs/zh/,
github地址是: https://github.com/code4craft/webmagic。
适合对象:java开发人员或者已经在本地安装了java环境而又不想再安装python环境的人(本人没错了)
二、爬取优快云文章
(一)获取文章列表
我们这次主要是爬取csdn首页推荐模块的文章来练练手。
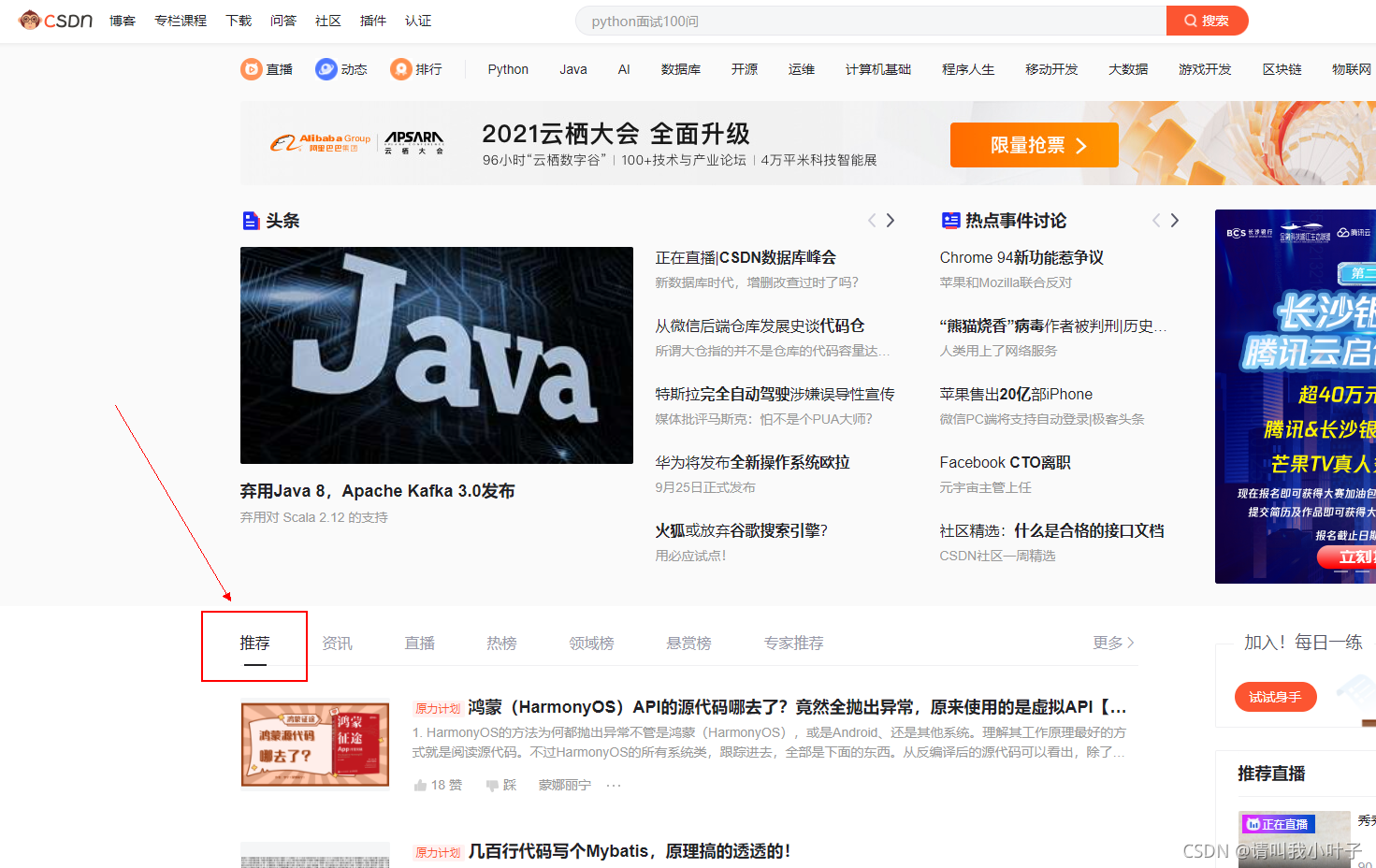
推荐模块的文章一看就是懒加载,一次性只会提供20篇文章,然后继续下拉才会进行新的请求获取新的文章。所以我们得找到获取文章的链接,通过f12打开控制台,当我们不停的获取推荐模块的文章时控制台network有个select_content一直在请求,因此就看下这个请求的返回值是不是我们想要的。
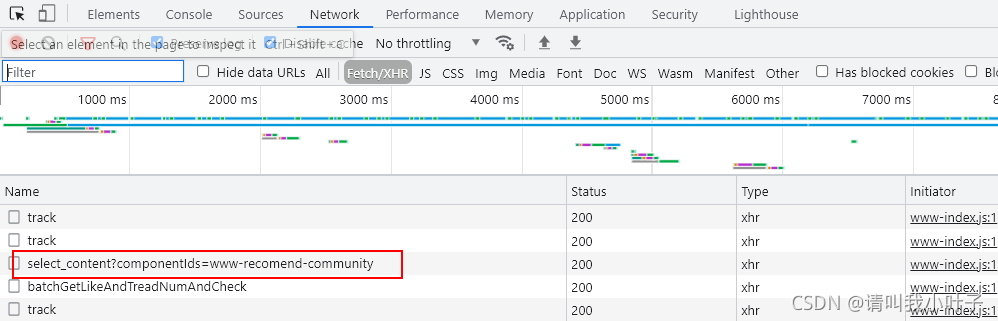
点进去select_content请求看到response有返回值,然后把返回值通过json.cn格式化以后发现返回的正是新的文章。因此这个接口正是我们需要的获取文章的接口,后面爬虫的入口就是这个链接。

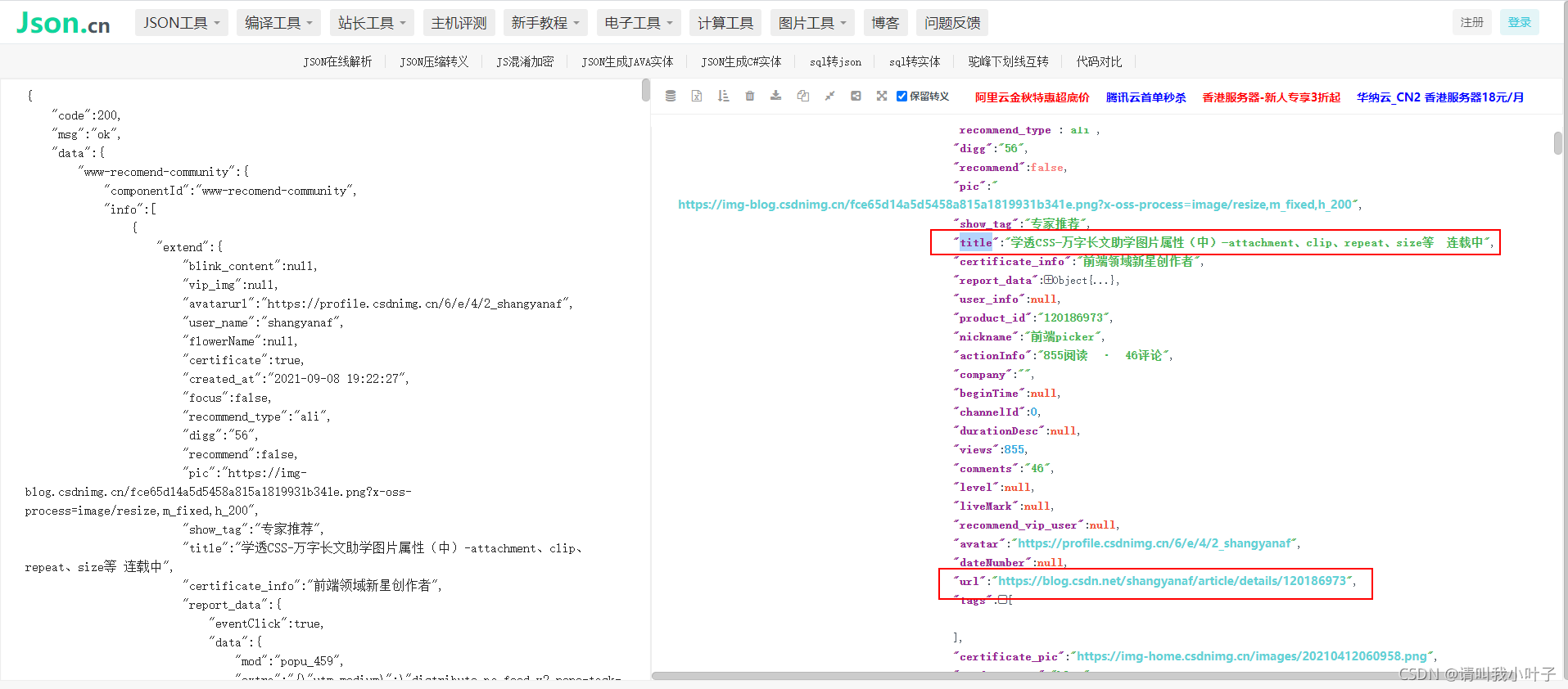
(二)文章具体分析
针对返回值中的随意一个url进行访问,然后针对访问后的页面进行分析,获取具体的html。
例如对https://blog.youkuaiyun.com/shangyanaf/article/details/120186973这个url进行访问分析。
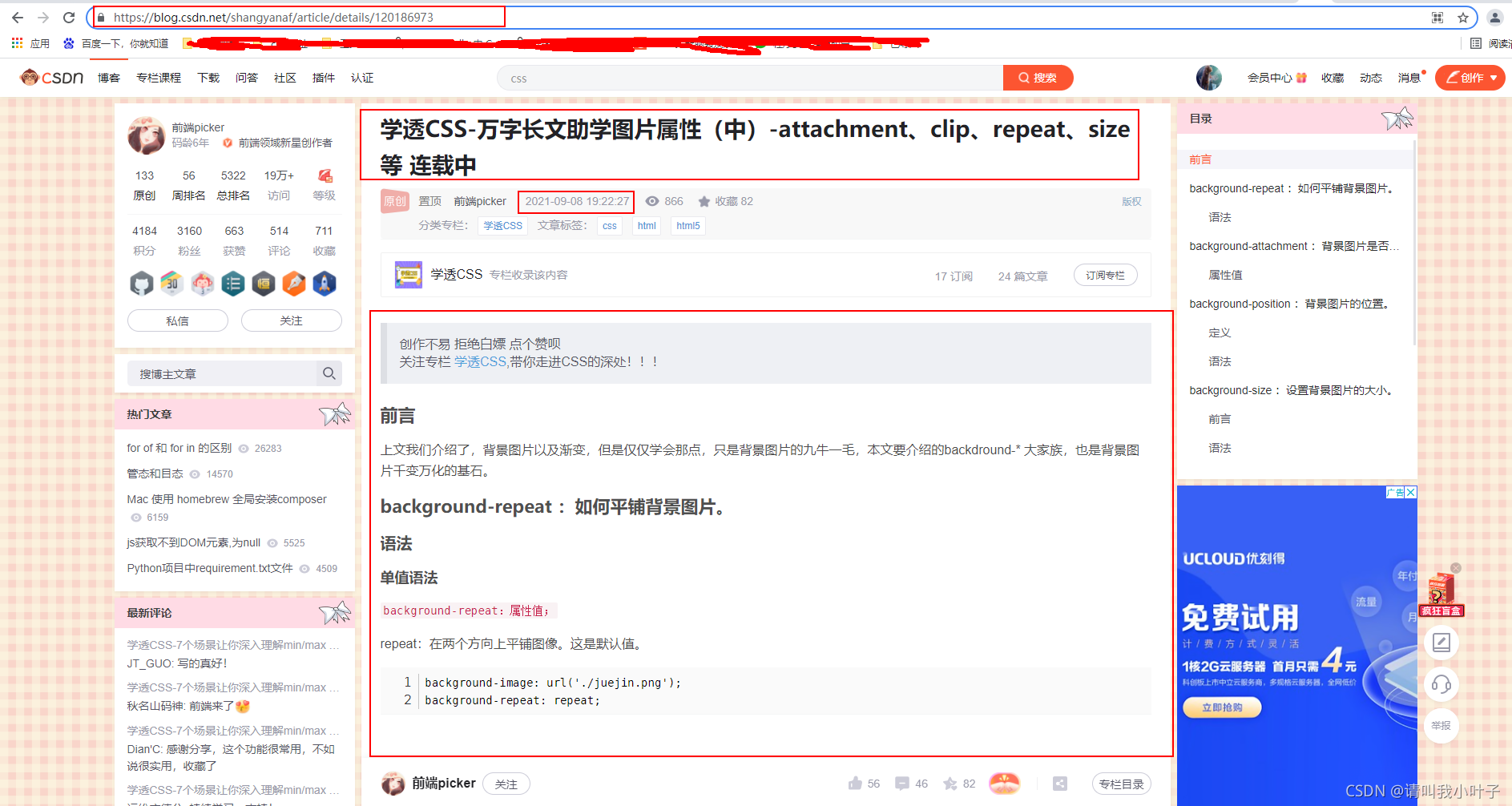
我们访问到文章以后如果想保存文章的名称、文章发布时间,文章内容,那么我们就打开f12控制台,看下html具体如何获取。
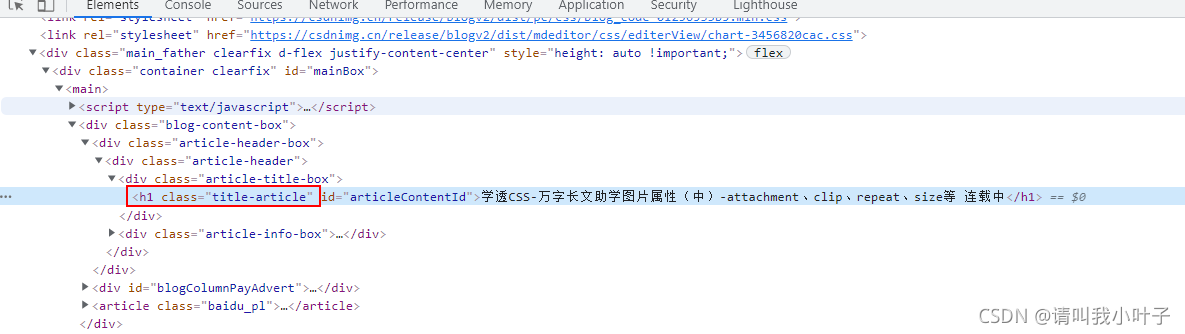
上图可以看到,文章的名称是class为title-article的h1的值,也能用h1的id:articleContentId来获取h1的值,后面我们的代码就是用h1的id来获取的值。
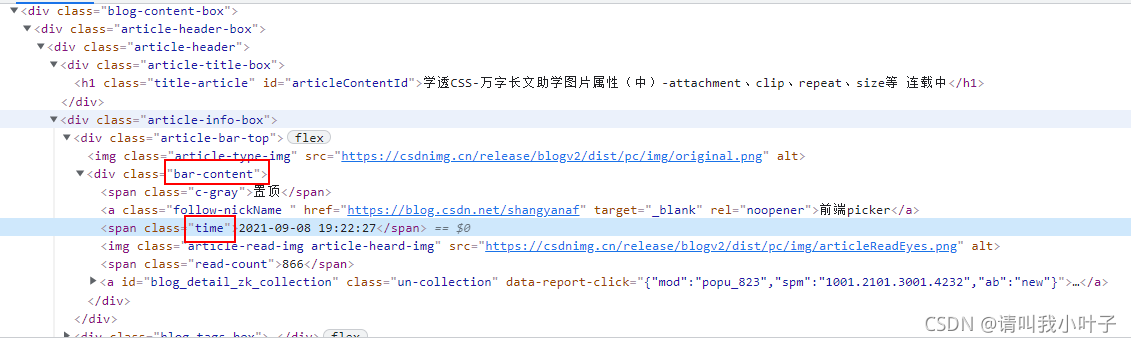
上图可以看到,文章的发布时间是class为bar-content的div下class为time的span的值。
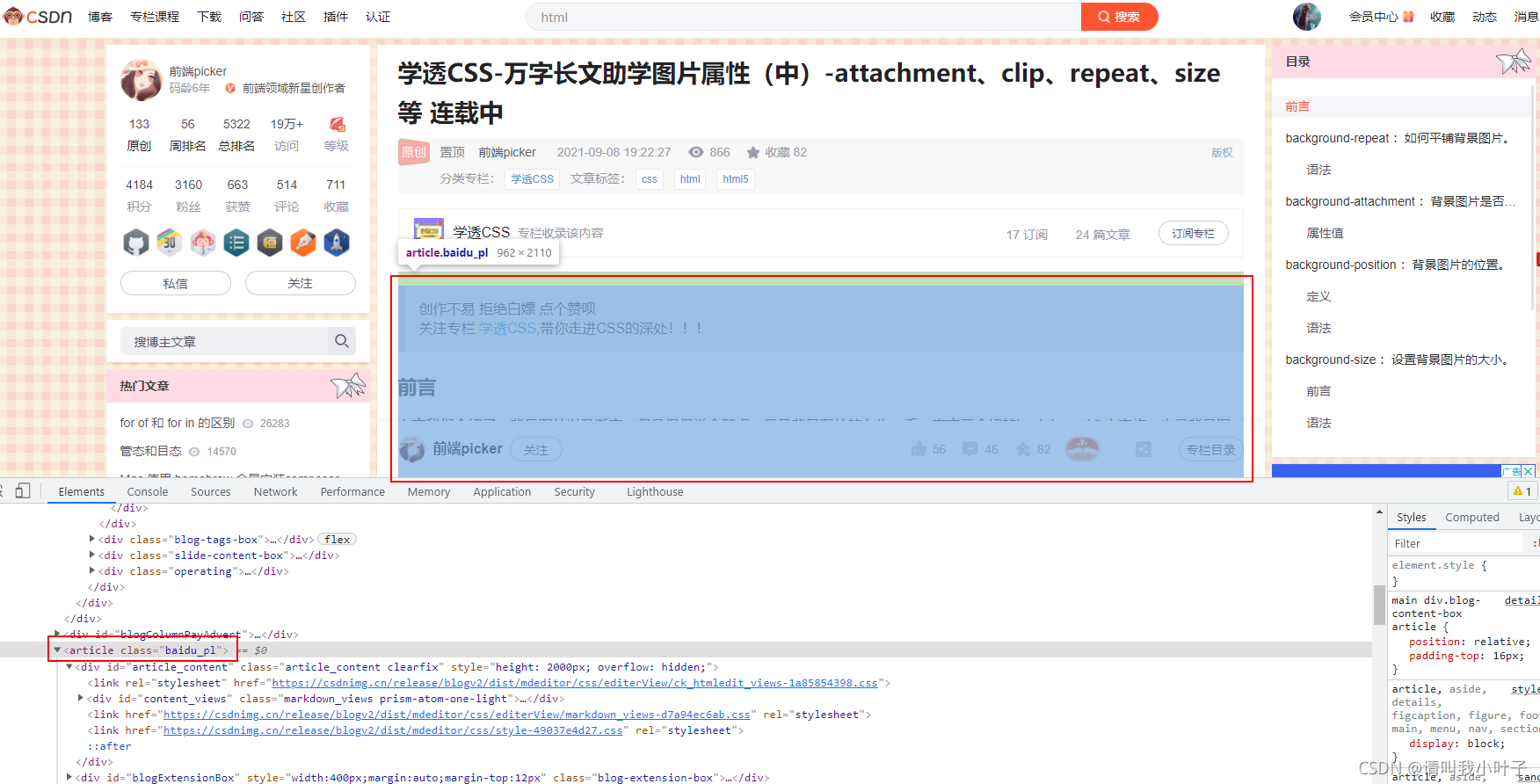
上图可以看到,文章的内容是class为baidu_pl的div下article的值。
(三)具体代码
package com.cloud.applets.controller.crawler.my;
import org.apache.commons.collections.CollectionUtils;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.JsonPathSelector;
import java.util.List;
/**
* @Description: Csdn爬虫
* @Author: yl
* @Date: 2021/9/23
*/
public class CsdnBlogProcessor implements PageProcessor {
private static final String LIST_URL = "https://cms-api\\.csdn\\.net/v1/web_home/select_content.*";
private Site site = Site
.me()
.setDomain("csdn") //下载好以后文件夹名
.setSleepTime(3000)
.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override
public void process(Page page) {
if (page.getUrl().regex(LIST_URL).match()) {
List<String> urlList = new JsonPathSelector("$.data.www-recomend-community.info[*].extend.url").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(urlList)) {
for (String url : urlList) {
page.addTargetRequest(url);
}
}
} else {
page.putField("title", page.getHtml().xpath("//h1[@id='articleContentId']") +"<br>");
page.putField("date",page.getHtml().xpath("//div[@class='bar-content']//span[@class='time']")+"<br>");
page.putField("content", page.getHtml().xpath("//article[@class='baidu_pl']"));
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
//爬虫的启动入口,url就是上面分析的select_content的具体地址,FilePipeline写入的是结果存放的地址
Spider.create(new CsdnBlogProcessor()).addUrl("https://cms-api.youkuaiyun.com/v1/web_home/select_content?componentIds=www-recomend-community")
.addPipeline(new FilePipeline("D:\\webmagic\\"))
.run();
}
}
代码解释:
这里解释一下process中的方法,所有的链接请求都会到process中,process中我们要判断这次请求是请求的selcet_content获取文章列表的链接还是具体文章的链接。
1)如果是获取文章列表的链接,那将稳藏列表中的文章的url放到TargetRequest中,这是后面我们要访问的文章的具体链接;
2)至于文章的url为什么要$.data.www-recomend-community.info[*].extend.url这样获取,看下图接口返回值的层级结构,由于屏幕大小有限,只能截图到title那,url是跟title一个层级的。而返回的info是数组,里面包含多个对象,要获取数组里面每个对象就得用 *了。

3)如果访问的是文章的具体链接,根据上面的分析,我们要输出文章名称、发布时间、具体内容,而他们在html中具体值的获取上面也分析了,在代码中的方式就如上面所示了。
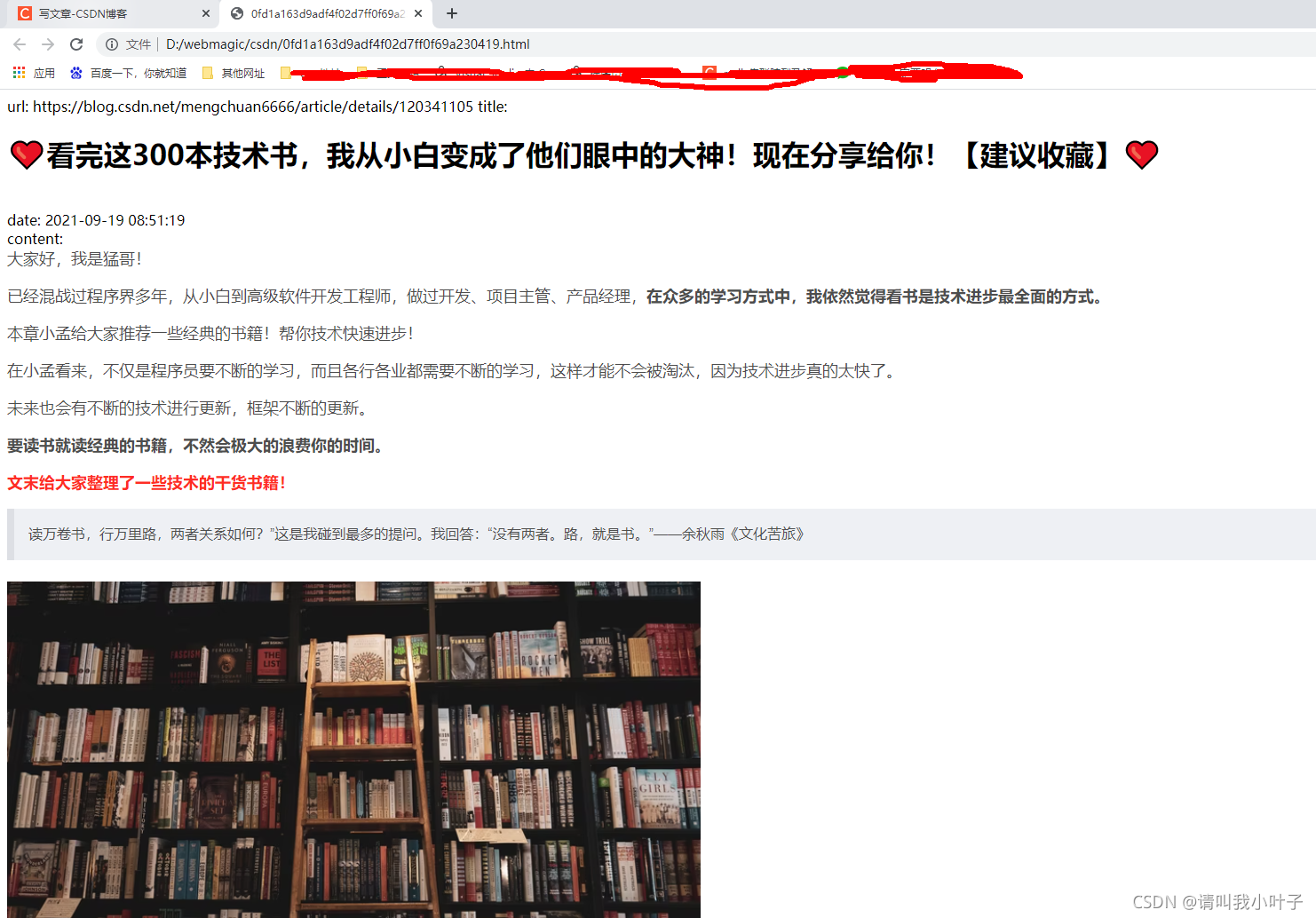
(四)效果
可以看到已经下载好了
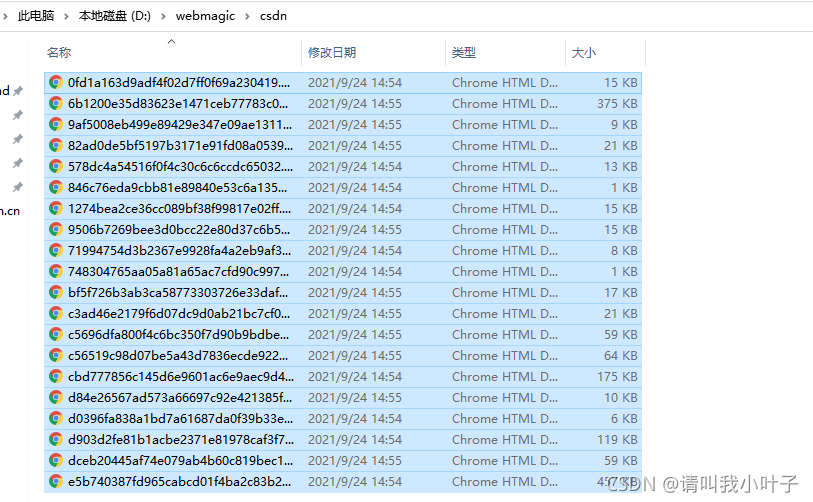
随便打开一篇文章,效果如下:

















 2744
2744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









