




一、背景
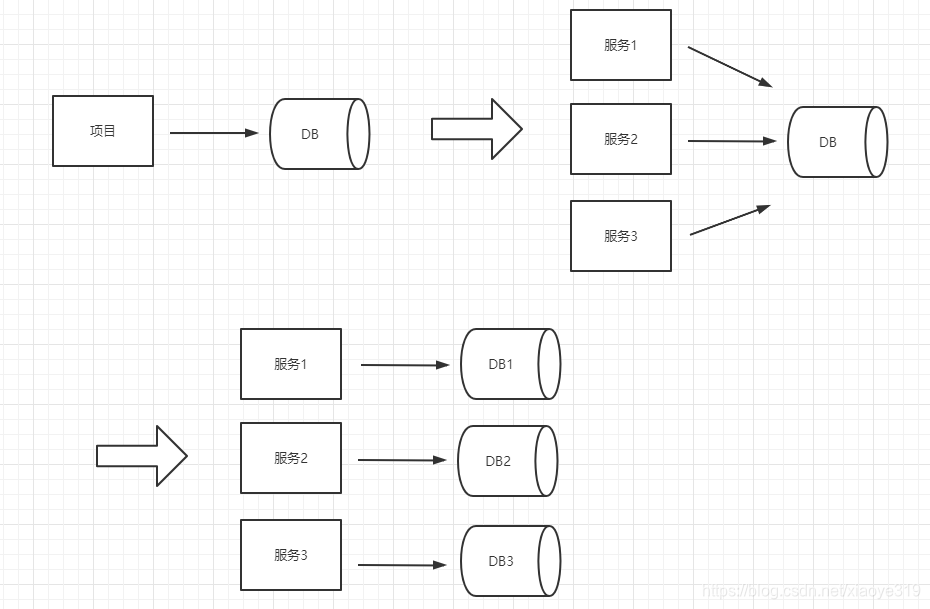
当我们新搭建一个项目时,在用户量没上来之前几乎都是先使用的单体项目,当用户量上来了单体项目不支持那么高的量的时候我们都会拆分项目,将单体的项目向分布式方向演进。如果这个时候我们的项目已经拆分成了多个分布式的项目了,但我们访问的还是同一个数据库,那么无论你拆分为多少个服务,其访问的数据库是同一个,当量上来以后无论你项目再怎么拆分还是会出现反应慢、超时等问题,究其原因还是因为数据库的连接数是有限的,这个时候就要考虑分库以及分库以后的分表了。
二、水平和垂直拆分
1、水平分库和垂直分库
2.1、水平分库
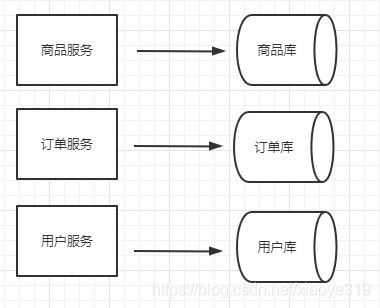
水平分库就是根据业务的不同访问不同的库,例如针对订单服务拆分出订单相关的库,针对商品服务来拆分出商品相关的库,不同的业务访问自己对应的业务库。
2.1、垂直分表
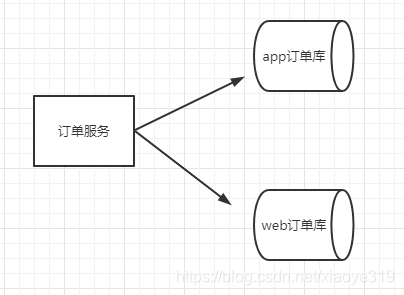
垂直分库就是同一个业务根据维度的不同进行分不同的库,例如订单服务对应的订单库可以根据来源的不同分为app订单库和web订单库。
2、水平分表和垂直分表
2.1、水平分表
2.1.1、何为水平分表
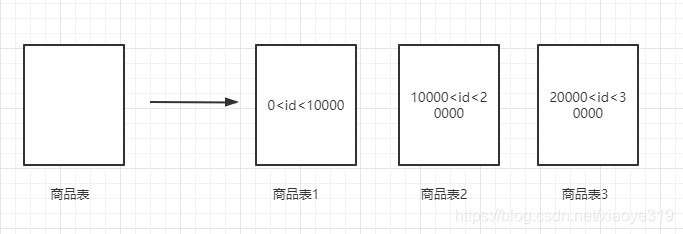
水平分表就是将一个表的数据分成多个表,例如根据id进行水平拆分,id范围为0-10000的数据落在表1,id范围为10000-20000的数据落在表2,id范围为20000-30000的数据落在表3。水平分表的前提是表的结构是一样的,不同的是落在表中的数据不同。
2.1.2、单表的数据量达到多少以后才需要进行水平分表呢?
 这是阿里的java开发规范上写的,单表超过500w行或者表容量超过2GB时才考虑进行分表,其实如果你的表索引用的好,单表达到1000w再拆分也是可以的,前提是数据量不要太大。
这是阿里的java开发规范上写的,单表超过500w行或者表容量超过2GB时才考虑进行分表,其实如果你的表索引用的好,单表达到1000w再拆分也是可以的,前提是数据量不要太大。
2.1、垂直分表
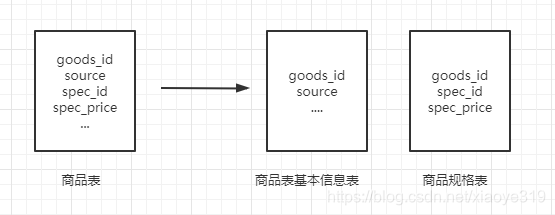
垂直分表就是表的字段过多,什么信息都放在一起,导致即使查询的只是基本信息也得查这个表,导致查到很多冗余字段,例如商品表中即包含商品的基本信息又包含商品规格信息,这个时候就需要将该表拆分成商品基本信息表、商品规格表。
三、可能出现的问题
1、跨库的关联查询
解决方案:
1.1、字段冗余
跨库查询不方便有时只能在自己的表中增加需要的字段,无形中增加了表的冗余字段,而且可能会越加越多,这就失去了分库分表的意义。
1.2、ETL
通过ETL将需要的数据同步一份到自己的库中,只要涉及同步的问题都得考虑数据一致性的问题。
1.3、全局表
一些通用表,大家都用的表只能在每个数据库都复制一份,但是当某个库的修改了怎么让别的库中的数据也同步修改,不然数据还是不一致性。
1.4、ER表
有关系的表得放一个数据库,例如订单表和订单详情表,要通过订单查询订单详情,如果跨库查询会导致关系更加复杂。因此可以加根据某个规则规定某个规则下的数据都放在同一个节点,例如order_id为1-1000的其订单表和详情表都放在节点1,order_id为1001-2000的都放在节点二。
2、分布式事务问题
至于分库分表中分布式事务的问题,在Mycat和Sharding-JDBC中各有对应的解决方案。
分布式事务的问题,有兴趣的请看我的另一篇博客:分布式事务以及解决方案
3、排序、分页、函数计算的问题
数据在不同的库或者不同的表中,当列表页进行排序、分页或者函数计算时怎么来查询,怎么做到跨库跨表进行数据综合对比然后获取想要的结果。只能在各个节点先做运算,然后将运算的结果进行聚合以后再返回,这无疑增加了各种困难。
4、全局主键唯一性问题
至于全局主键唯一性的问题,在Mycat和Sharding-JDBC中各有对应的解决方案,只不过原理还是跟我在雪花算法中讲的一样,有兴趣的可以看看。
有兴趣的请看我的另一篇博客:雪花算法以及具体实现
四、解决方案
1、使用mycat做分库分表
2、使用sharding-jdbc做分库分表
请看我的另一篇博客:Sharding-JDBC和Mycat在分库分表中的应用

















 1868
1868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









