



 本文深入解析了Java中LinkedList的底层实现原理,包括其基于双向循环链表的数据结构、添加、删除操作的源码分析,以及如何高效访问指定位置的元素。对比ArrayList,LinkedList在插入和删除上表现出更高的性能。
本文深入解析了Java中LinkedList的底层实现原理,包括其基于双向循环链表的数据结构、添加、删除操作的源码分析,以及如何高效访问指定位置的元素。对比ArrayList,LinkedList在插入和删除上表现出更高的性能。
Java集合的LinkedList底层详解
前一篇文章,已经讲过ArrayList的底层实现原理,今天学习LinkedList底层实现原理。
LinkedList类是List接口的实现类,它是一个集合,可以根据索引来随机的访问集合中的元素,还实现了Deque接口,它还是一个队列,可以当成双端队列来使用。虽然LinkedList是一个List集合,但是它的实现方式和ArrayList是完全不同的,ArrayList的底层是通过一个动态的Object[]数组实现的,而LinkedList的底层是通过链表来实现的,因此它的随机访问速度是比较差的,但是它的删除,插入操作很快。
- LinkedList是基于双向循环链表实现的,除了可以当作链表操作外,它还可以当作栈、队列和双端队列来使用。
- LinkedList同样是非线程安全的,只在单线程下适合使用。
- LinkedList实现了Serializable接口,因此它支持序列化,能够通过序列化传输。
基本属性:
|
1
2
3
|
transient
int
size =
0
;
//LinkedList中存放的元素个数[/size]
[size=
3
]
transient
Node<E> first;
//头节点
transient
Node<E> last;
//尾节点
|
LinkedList数据结构原理
LinkedList底层的数据结构是基于双向循环链表的,且头结点中不存放数据,每个节点都有一个前驱和后继,如下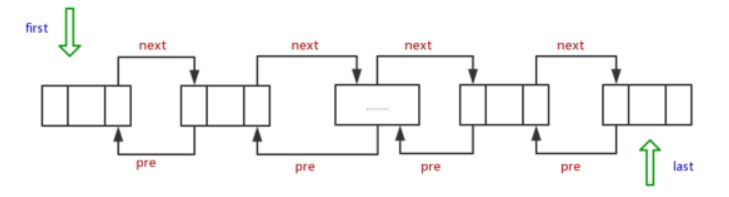
部分源码:
添加方法
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
public
class
LinkedList<E>
extends
AbstractSequentialList<E>
implements
List<E>, Deque<E>, Cloneable, java.io.Serializable {
transient
int
size =
0
;
//LinkedList中存放的元素个数
transient
Node<E> first;
//头节点
transient
Node<E> last;
//尾节点
//构造方法,创建一个空的列表
public
LinkedList() {
}
//将一个指定的集合添加到LinkedList中,先完成初始化,在调用添加操作
public
LinkedList(Collection<?
extends
E> c) {
this
();
addAll(c);
}
//插入头节点
private
void
linkFirst(E e) {
final
Node<E> f = first;
//将头节点赋值给f节点
//new 一个新的节点,此节点的data = e , pre = null , next - > f
final
Node<E> newNode =
new
Node<>(
null
, e, f);
first = newNode;
//将新创建的节点地址复制给first
if
(f ==
null
)
//f == null,表示此时LinkedList为空
last = newNode;
//将新创建的节点赋值给last
else
f.prev = newNode;
//否则f.前驱指向newNode
size++;
modCount++;
}
//插入尾节点
void
linkLast(E e) {
final
Node<E> l = last;
final
Node<E> newNode =
new
Node<>(l, e,
null
);
last = newNode;
if
(l ==
null
)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
}
|
添加方法默认是添加到LinkedList的尾部,首先将last指定的节点赋值给l节点,然后新建节点newNode,此节点的前驱指向l节点,data = e,next = null,并将新节点赋值给last节点,它成为了最后一个节点,根据当前List是否为空做出相应的操作。若不为空将l的后继指针修改为newNode,并且size++,modCount++;
删除方法:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
/*
LinkedList的删除操作,从前往后遍历删除
*/
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
|
返回指定位置的节点信息:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
//返回指定位置的节点信息
//LinkedList无法随机访问,只能通过遍历的方式找到相应的节点
//为了提高效率,当前位置首先和元素数量的中间位置开始判断,小于中间位置,
//从头节点开始遍历,大于中间位置从尾节点开始遍历
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
|
List实现类的使用场景
ArrayList,底层采用数组实现,如果需要遍历集合元素,应该使用随机访问的方式,对于LinkedList集合应该采用迭代器的方式
如果需要经常的插入。删除操作可以考虑使用LinkedList集合
如果有多个线程需要同时访问List集合中的元素,开发者可以考虑使用Collections将集合包装成线程安全的集合(Collections.synchronizedList(new LinkedList<>()))。
总结:
- LinkedList是一个功能很强大的类,可以被当作List集合,双端队列和栈来使用。
- LinkedList使用链表保存集合中的元素,因此随机访问的性能较差,但是插入删除时性能高
- LinkedList基于链表实现的,因此不存在容量不足的问题,所以没有扩容的方法
- 注意源码中的Node node(int index)方法。该方法返回双向链表中指定位置处的节点,而链表中是没有下标索引的,要指定位置出的元素,就要遍历该链表,从源码的实现中,我们看到这里有一个加速动作。源码中先将index与长度size的一半比较,如果index<size/2,就只从位置0往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部分不必要的遍历,从而提高一定的效率(实际上效率还是很低)。

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









