




 本文详细解释了InnoDB存储引擎中索引失效的原理,通过数据页结构和B+树的视角分析索引失效场景,包括聚簇索引、二级索引和联合索引的B+树结构,以及索引覆盖和回表的概念。
本文详细解释了InnoDB存储引擎中索引失效的原理,通过数据页结构和B+树的视角分析索引失效场景,包括聚簇索引、二级索引和联合索引的B+树结构,以及索引覆盖和回表的概念。
📚 全文字数 : 6k+
⏳ 阅读时长 : 8min
📢 关键词 : 数据页结构、索引的B+树结构、索引失效原理
场景再现,有多少朋友有过的?
面试官👴:我看你熟悉简历数据库索引,那索引失效有哪些场景?
我👦:巴拉巴拉,把从晚上背的6,7条失效场景一字不落的背出来了
我👦:心里想,这问题能难道我?
面试官👴:能具体一点吗,上一位面试者也是这么说的
我👦:额,心里想,我没背过这个知识点啊,芭比Q了
前言
文章开头的面试场景不是我编出来的,兄弟们,刚毕业一两年面试的我就出现过这种问题。仅仅问你失效场景,只要准备过面试的人都能答出来。但是再往下问问,就不知道怎么答了。
这篇文章将从InnoDB存储引擎的索引B+树和数据页的角度一起来看实际的索引失效问题,设计的内容比较多,关于【数据页】和【索引的知识结构】只是可以翻看我之前的文章有更详细的内容。
大纲
先看大纲,让自己知道今天要讲的内容。
什么是索引失效
我们知道创建索引的目的是为了提高查询速率,但并不是创建了索引就能让查询速率显著提高的。
稍不注意,你是在列上建了索引,可能你写的查询条件也是索引列,但最终执行计划没有走它的索引,从而走了全表扫描,这种建了索引而实际索引没用的情形就是索引失效。
从数据页看B+树
(1)在叶子节点一层,所有记录的主键按照从小到大的顺序排列,并且形成了一个双向链表,便于范围查询。叶子节点的每一个Key指向一条记录。
(2)非叶子节点取的是叶子节点里面Key的最小值。这意味着所有非叶子节点的Key都是冗余的叶子节点。同一层的非叶子节点也互相串联,形成了一个双向链表
在了解索引和索引失效之前,我们应该对数据页,数据页中数据的存储方式,如何构建B+树的这些原理搞清楚!
这些对后续理解为啥使用B+树,B+树的特性会有很大的帮助,而不是为了应付才去死记硬背一些没什么营养的答案。
数据页结构
MySQL读取数据都是以【数据页】为单位读取的,而不是需要读取一条记录的时候就读记录本身,以数据页为读取单位的话,需要将其整体读取内存中,但是各个数据页之间是不连续的。
而数据页默认大小为16KB,意味着每次至少是将16KB的内容疏导内存中。
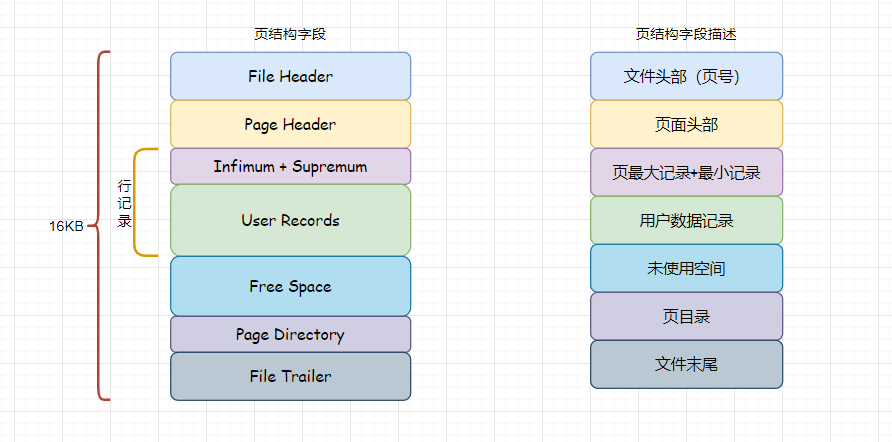
左侧的是组成数据页的7大部分,右侧是这几部分的简要说明。
不同数据页之间既然不是连续的,那怎么知道这个数据页的下个页在哪?
其实File Header中有两个指针,分别指向上一个数据页和下一个数据页
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 174万+
174万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









