




 本文深入探讨了Redis在分布式锁、异步队列、持久化机制、主从同步及集群部署等方面的应用与实践。详细介绍了SEINX实现分布式锁的方法、RDB与AOF持久化的优缺点以及如何利用Redis进行高效的数据处理。
本文深入探讨了Redis在分布式锁、异步队列、持久化机制、主从同步及集群部署等方面的应用与实践。详细介绍了SEINX实现分布式锁的方法、RDB与AOF持久化的优缺点以及如何利用Redis进行高效的数据处理。
如何通过Redis实现分布式锁
分布式锁需要解决的问题
互斥性
安全性
死锁
容错
SEINX 实现分布锁
SEINX key value:如果key不存在,则创建并赋值
时间复杂度:O(1)
返回值:设置成功,返回1;设置失败,返回0。
如果解决SEINX长期有效的问题
expire key seconds
设置key的生存时间,当key过期时(生存时间为0),会被自动删除
这串代码有设计问题 如果没有设置成功 就不会执行独立资源逻辑 缺点原子性得不到满足

set key value

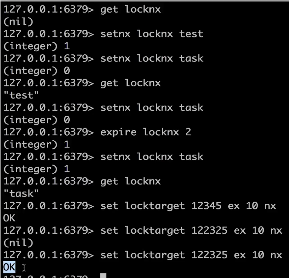
setnx locknx test 不存在就创建并赋值 第二次赋值不会进行改变
expire locknx task 设置过期时间 2秒
set locktarget 1234 ex 10 nx 应为还有没有过期 所以不能设置
大量的key同时过期的注意事项
集中过期,由于清理大量的key很耗时,会出现短暂的卡顿现象
解放方案:在设置key的过期时间的时候,给每个key加上随机值
如何使用Redis做异步队列
使用List作为队列,rpush生产消息,lpop消费消息
它的缺点:没有等待队列里有值就直接消费
弥补:可以通过在应用层引入sleep机制去调用lpop重试
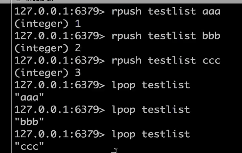
rpush 添加消息,
然后lpop取出消息
blpop key [key...]timeout:堵塞直到队列有消息或超时
缺点:只提供一个消费者消息
timeout 是时间 堵塞时间
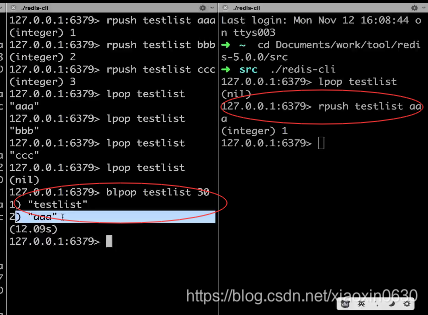
blpop testlist 30 testlist这key堵塞30 秒
另一个客户端shell rpush testlist aaa
那台客户端就获取到了消息
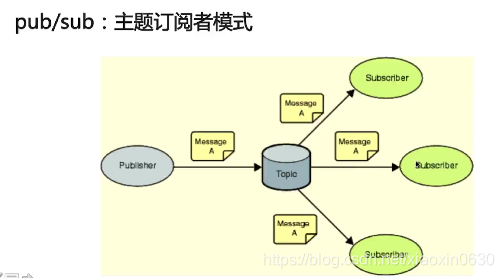
pub/sub:主题订阅者模式
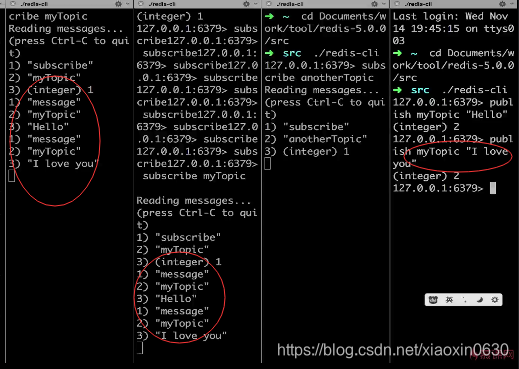
老师案例是四个客户端
第一个订阅一个频道
订阅一个myTopic 代码如下
subscribe myTopic
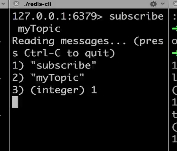
第三个没有订阅,
第四个 往myTopic中添加 "Hello"
第二客户端和第一次客户端 获取到 第四个客户端发送的
pub/sub的缺点
消息的分布是无状态,无法保证可达
Redis如何做持久化
RDB
RDB(快照)持久化:保存某个时间点的全量数据快照(配置文件进行配置,具体另找文件 这篇只是讲下面试)
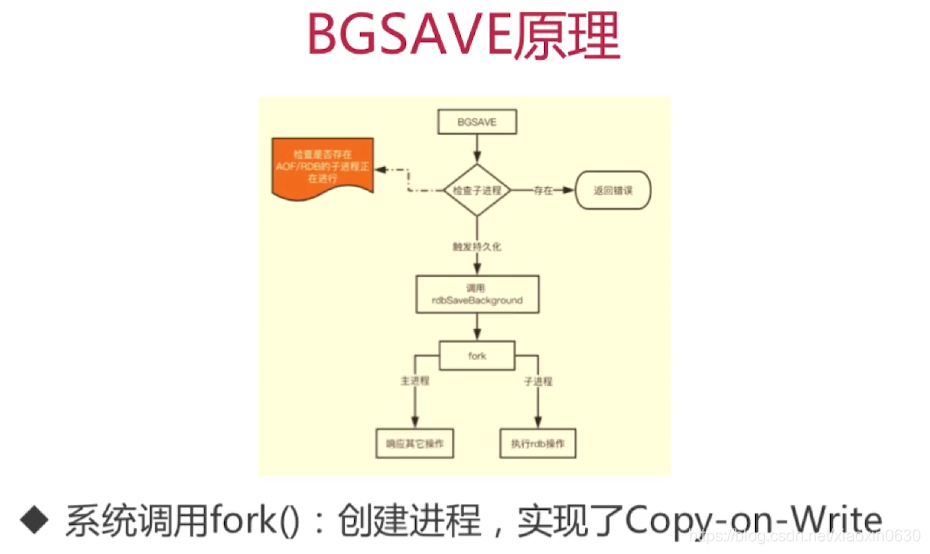
save:堵塞Redis的服务器进程,知道RDB文件被创建完毕
bgsave:fork出一个子进程来创建RDB文件,不堵塞服务器进程
自动化触发RDB持久化的方式
根据redis.conf配置的SAVE m m定时触发 (用的是BGsave)
主从复制时,主节点自动触发
执行Debug Reload
执行Shutdown且没有开启AOF持久化
AOF
AOF(持久化):保存写状态
记录下除了查询以外的所有变更数据库状态的指令
以append的形式追加保存到AOF文件中(增量)
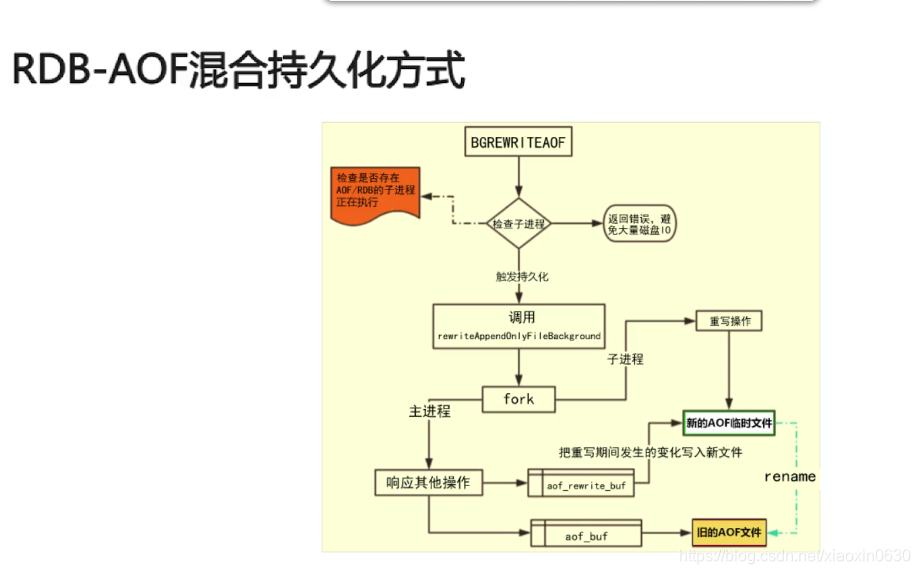
日志重写解决AOF文件太小不断增大的问题,原理如下:
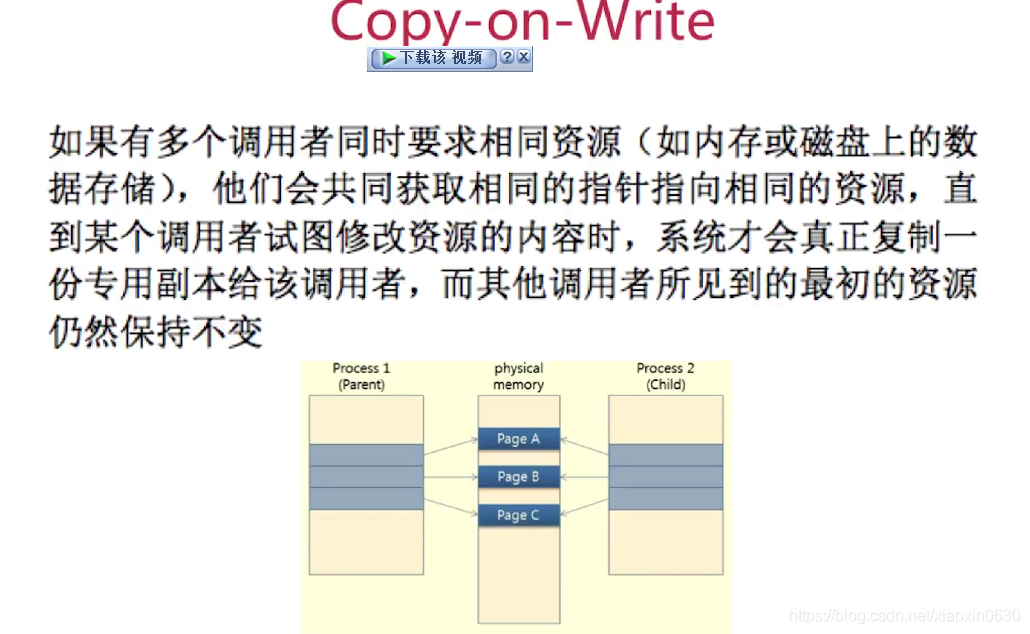
调用fork(),创建一个子进程
子进程吧新的AOF写到一个临时文件里,不依赖原来的AOF文件
主进程持续将新的变动同时写到内存和原来的AOF里
主进程获取子进程重写AOF的完成信号,往新AOF同步增强变动
使用新的AOF文件替换掉旧的AOF文件
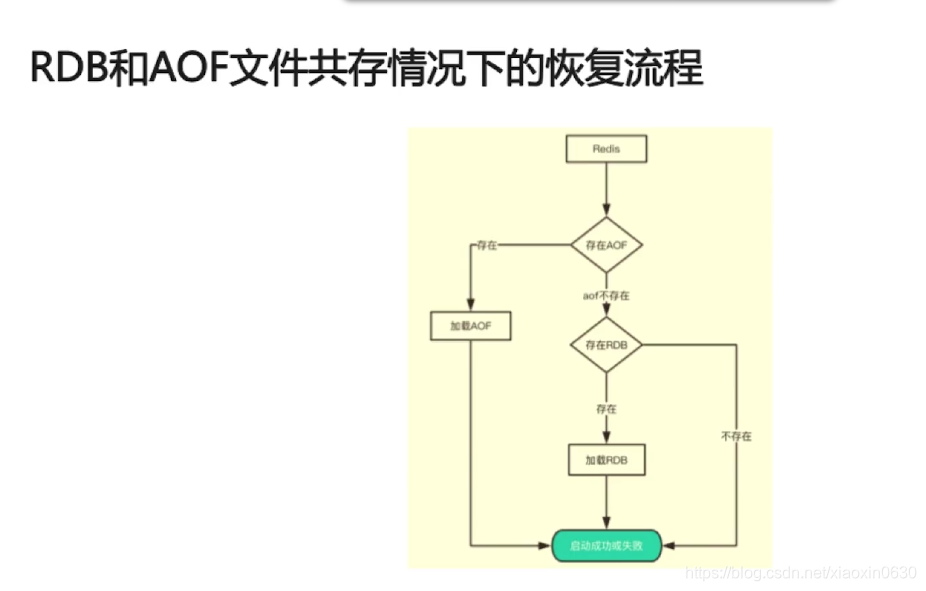
RDB和AOF的优缺点
RDB优点:全量数据快照,文件小,恢复快
RDB缺点:无法保存最近一次快照之后的数据
AOF优先:可读性高,适合保存增量数据,数据不易丢失
AOF缺点:文件体积大,恢复时间长
RDB-AOF混合持久化方式
使用Pipeline的好处
Pipeline和Linux的管道类似
Redis基于请求/响应模型,单个请求处理需要一一应答
Pipeline批量执行指令,节省多次IO往返的时间
有序依赖的指令建议分批发送
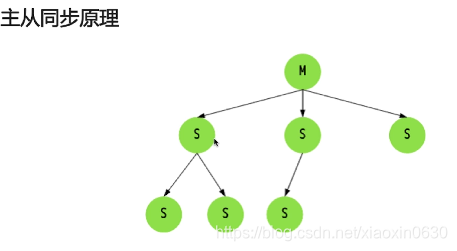
主从同步原理
全同步过程
Slave发送sync命令到Master
Master 启动一个后台进程,将Redis中的数据快照保存文件中
Master将保存数据快照期间接收到的写命令缓存起来
Master完成写文件操作后,将该文件发送Slave
使用新的RDB文件替换掉旧的RDB文件
Master将这期间收集的增量写命令发送到Slave段
增量同步过程
Master接受到用户的操作指令,判断是否需要传播到Slave
将操作记录追加到AOF文件
将操作传播到其他Slave:1、对齐主从库;2、往响应缓存写入指令
将缓存中的数据发送给Slave
解决主从同步Master宕机后的主从切换问题:
监控:检查主从服务器是否允许正常
提醒:通过API向管理员或者其他应用程序发送故障通知
自动故障迁移:主从切换
流言协议Gossip
在杂乱无章中寻求一致
每个节点都随机地与对方通信,最终所有节点的状态达成一致
种子节点定期随机向其他节点发送节点列表以及需要传播的消息
不保证消息一定会传播给所有节点,但是最终会趋于一致
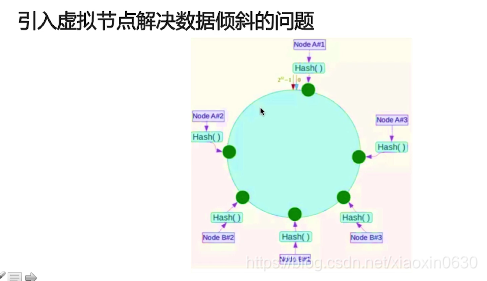
如何从海量数据里快速找到所需?
集群
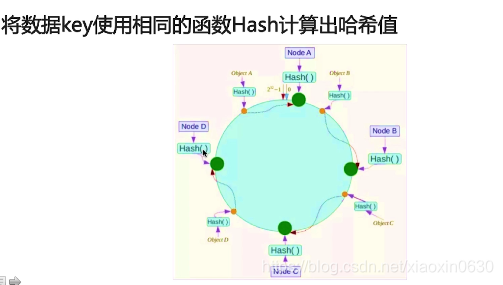
分片:按照某种规则去划分数据,分散存储在多个节点上
起始位的左边是 2^32-1
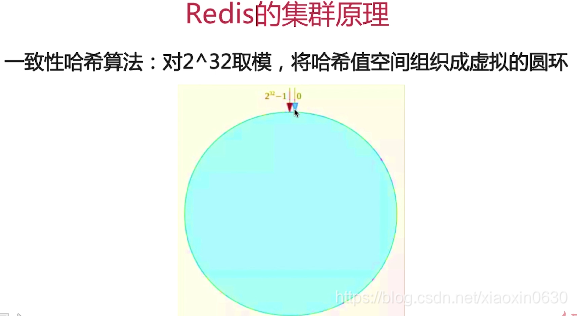
顺时针 一个个服务器进行连接 传递数据
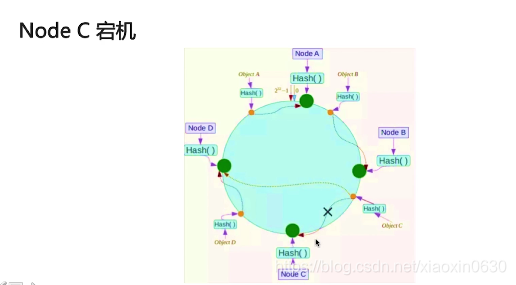
Node C 宕机 它就会顺时针找到里自己最近分服务器
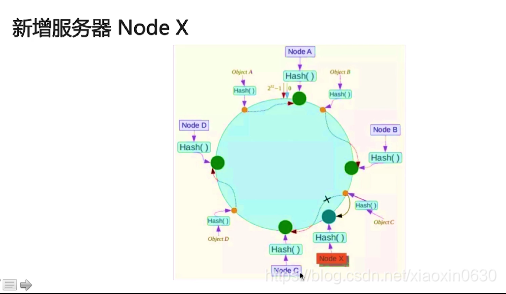
增加服务器只需要在c的位置操作就行
Redis 集群 修改少,扩展性大
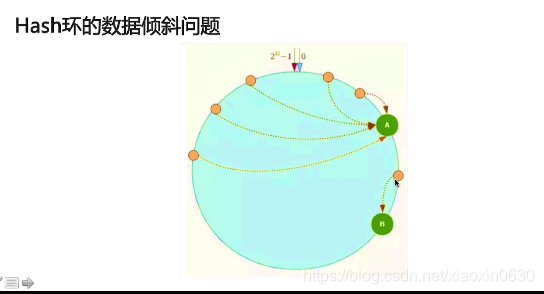
但是集群也是有缺点
它的缺陷就是 如果服务器分配不均匀 都会往自己近的服务器传数据
添加编号或者在IP方向进行修改

















 1946
1946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









