




主要内容:一致性读 当前读
 在可重复读隔离级别之下:事务A:k=1; 事务B: k=3
在可重复读隔离级别之下:事务A:k=1; 事务B: k=3
在读提交隔离级别之下:事务A: K = 2;事务B: K=3
(大白话)原理:在可重复读隔离级别之下,查询操作所遵循的是一致性试图中给出的数据,更新操作所遵循的是当前读中所给出的数据。
MVCC:多版本并发控制。在我的理解里面,就是回滚操作
transaction id:在InnoDB中,每一个事务都有自己唯一的事务ID,叫做transaction id。它是在事务开始的时候向InnoDB的事务系统申请的,是按照申请顺序严格递增的。
row trx_id: 每行数据有多个版本(每更新一次,就对应一个新的版本)。行内数据的更新是由事务的一系列操作引起的,为了记录下每次的数据版本,采用的方法是:把transaction id赋值给这个数据版本,记为:row trx_id。
下图表示,同一行数据的不同版本,分别为;V1 V2 V3 V3: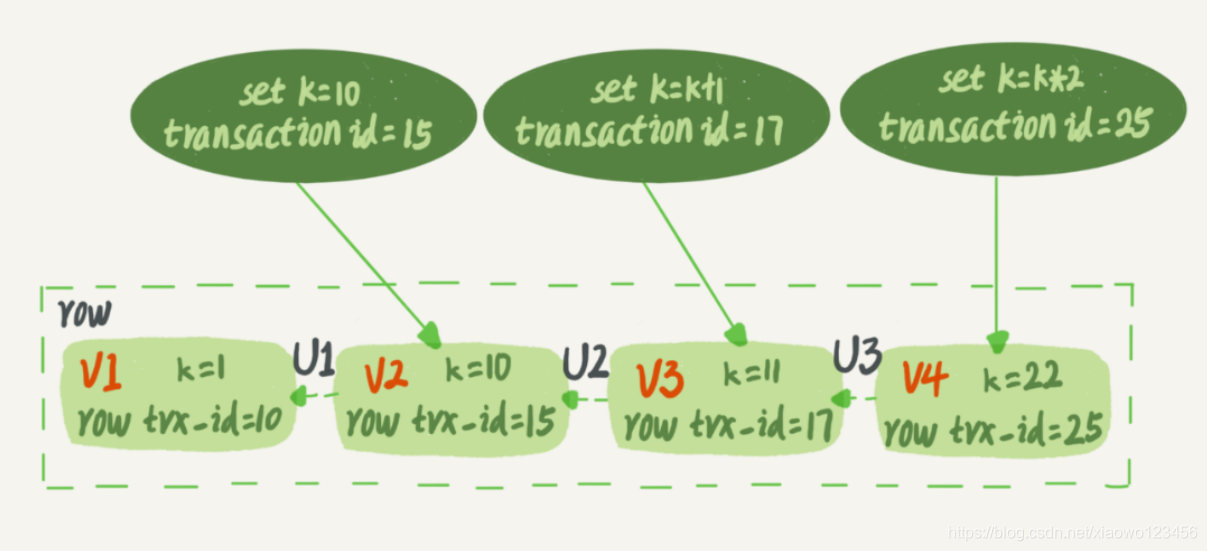 上图中的三个虚线箭头就是对应的undo log(回滚日志)。另外,行内数据V1, V2, V3并不是真实存在的,而是由undo log和V4的值推算出来的到的。
上图中的三个虚线箭头就是对应的undo log(回滚日志)。另外,行内数据V1, V2, V3并不是真实存在的,而是由undo log和V4的值推算出来的到的。
快照:在可重复读隔离级别之下,对整个数据库中数据的一些记录。根据一致性视图,可以从当前值,恢复想要事务ID时的值。
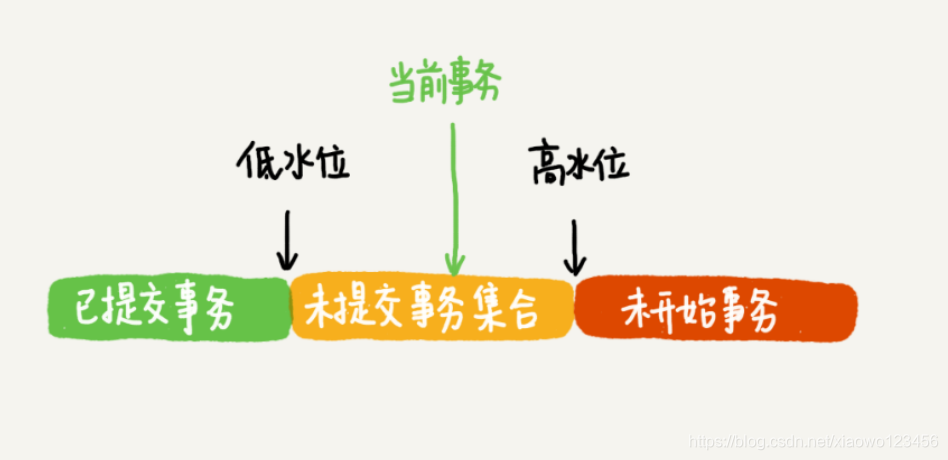
当前事务的一致性试图:数组+高水位
~~~~数组:在InnoDB中,为每个事务构建了一个数据,用来保存这个事务启动瞬间,当前正在”启动了但是还没有提交“的所有事务的ID
~~~~高水位:如下图所示
 可重复读隔离级别----查询逻辑:
可重复读隔离级别----查询逻辑:
一个数据版本呢,对一个事务视图,除了自己的更新总是可见以外,有三种情况:
1 版本未提交,不可见
2 版本已提交,但是在视图创建后提交,不可见
3 版本已提交,在视图创建前提交,可见
可重复读隔离级别----更新逻辑:
更新数据,都是先读后写,只能读当前的值,也称为”当前读“
查询逻辑+更新逻辑,则可以解释图一当中的结果值。
数据库学习之事务隔离级别
最新推荐文章于 2024-12-02 09:39:39 发布
 本文深入解析了可重复读隔离级别的工作原理,探讨了一致性读与当前读的区别,以及多版本并发控制(MVCC)如何在不阻塞读操作的情况下实现并发更新。通过理解事务ID、数据版本(rowtrx_id)和回滚日志,读者将掌握在不同隔离级别下事务间的可见性规则。
本文深入解析了可重复读隔离级别的工作原理,探讨了一致性读与当前读的区别,以及多版本并发控制(MVCC)如何在不阻塞读操作的情况下实现并发更新。通过理解事务ID、数据版本(rowtrx_id)和回滚日志,读者将掌握在不同隔离级别下事务间的可见性规则。

















 1956
1956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









