







 本文深入探讨Java中的Set集合,包括Set、HashSet与TreeSet的特点及其实现原理。详细解析了如何利用hashCode和equals方法保证元素的唯一性,以及TreeSet如何进行元素排序。
本文深入探讨Java中的Set集合,包括Set、HashSet与TreeSet的特点及其实现原理。详细解析了如何利用hashCode和equals方法保证元素的唯一性,以及TreeSet如何进行元素排序。
上一篇文章Java技术栈.基础篇—详说集合之二介绍了List接口和其实现类,今天对Set接口和其实现类做下介绍。
Set简介
Set:用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。
对象的相等性
引用到堆上同一个对象的两个引用是相等的。如果对两个引用调用hashCode方法,会得到相同的结果,如果对象所属的类没有覆盖Object的hashCode方法的话,hashCode会返回每个对象特有的序号(java是依据对象的内存地址计算出此序号的),所以两个不同的对象的hashCode值是不可能相等的。
如果想要让两个不同的Person对象视为相等的,就必须覆盖从Object继承下来的hashCode方法和equals方法,因为Object hashCode方法返回的是该对象的内存地址,所以必须重写hashCode方法,才能保证两个不同的对象具有相同的hashCode,同时也需要两个不同对象比较equals方法会返回true
Set没有特有的方法,直接继承自Collection。
---| Itreable 接口 实现该接口可以使用增强for循环
---| Collection 描述所有集合共性的接口
---| List接口 可以有重复元素的集合
---| ArrayList
---| LinkedList
---| Set接口 不可以有重复元素的集合
HashSet
---| Itreable 接口 实现该接口可以使用增强for循环
---| Collection 描述所有集合共性的接口
---| List接口 可以有重复元素的集合
---| ArrayList
---| LinkedList
---| Set接口 不可以有重复元素的集合
---| HashSet 线程不安全,存取速度快。底层是以哈希表实现的。 哈希表里边存放的是哈希值,基于HashMap实现,HashSet底层使用HashMap来保存所有元素,因此HashSet 的实现比较简单,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成。HashSet存储元素的顺序并不是按照存入时的顺序(和List显然不同), 是按照哈希值来存的所以取数据也是按照哈希值取得。
由于Set集合是不能存储重复元素的集合,HashSet也具备这一特性的。HashSet通过元素的hashcode()和equals方法进行判断元素是否重复。
当你试图把对象加入HashSet时,HashSet会使用对象的hashCode来判断对象加入的位置。同时也会与其他已经加入的对象的hashCode进行比较,如果没有相等的hashCode,HashSet就会假设对象没有重复出现。
简单一句话,如果对象的hashCode值是不同的,那么HashSet会认为对象是不可能相等的。
因此我们自定义类的时候需要重写hashCode,来确保对象具有相同的hashCode值。
如果元素(对象)的hashCode值相同,是不是就无法存入HashSet中了?当然不是,还需要继续使用equals 进行比较。如果 equals为true 那么HashSet认为新加入的对象重复了,所以加入失败。如果equals 为false那么HashSet 认为新加入的对象没有重复,新元素可以存入。
源码解析
package java.util;
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
// HashSet是通过map(HashMap对象)保存内容的
private transient HashMap<E,Object> map;
// 定义一个虚拟的Object PRESENT是向map中插入key-value对应的value
// 因为HashSet中只需要用到key,而HashMap是key-value键值对;
// 所以,向map中添加键值对时,键值对的值固定是PRESENT
private static final Object PRESENT = new Object();
// 默认构造函数 底层创建一个HashMap
public HashSet() {
// 调用HashMap的默认构造函数,创建map
map = new HashMap<E,Object>();
}
// 带集合的构造函数
public HashSet(Collection<? extends E> c) {
// 创建map。
// 为什么要调用Math.max((int) (c.size()/.75f) + 1, 16),从 (c.size()/.75f) + 1 和 16 中选择一个比较大的树呢?
// 首先,说明(c.size()/.75f) + 1
// 因为从HashMap的效率(时间成本和空间成本)考虑,HashMap的加载因子是0.75。
// 当HashMap的“阈值”(阈值=HashMap总的大小*加载因子) < “HashMap实际大小”时,
// 就需要将HashMap的容量翻倍。
// 所以,(c.size()/.75f) + 1 计算出来的正好是总的空间大小。
// 接下来,说明为什么是 16 。
// HashMap的总的大小,必须是2的指数倍。若创建HashMap时,指定的大小不是2的指数倍;
// HashMap的构造函数中也会重新计算,找出比“指定大小”大的最小的2的指数倍的数。
// 所以,这里指定为16是从性能考虑。避免重复计算。
map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16));
// 将集合(c)中的全部元素添加到HashSet中
addAll(c);
}
// 指定HashSet初始容量和加载因子的构造函数
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
// 指定HashSet初始容量的构造函数
public HashSet(int initialCapacity) {
map = new HashMap<E,Object>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
}
// 返回HashSet的迭代器
public Iterator<E> iterator() {
// 实际上返回的是HashMap的“key集合的迭代器”
return map.keySet().iterator();
}
//调用HashMap的size()方法返回Entry的数量,得到该Set里元素的个数
public int size() {
return map.size();
}
//调用HashMap的isEmpty()来判断HaspSet是否为空
//HashMap为null。对应的HashSet也为空
public boolean isEmpty() {
return map.isEmpty();
}
//调用HashMap的containsKey判断是否包含指定的key
//HashSet的所有元素就是通过HashMap的key来保存的
public boolean contains(Object o) {
return map.containsKey(o);
}
// 将元素(e)添加到HashSet中,也就是将元素作为Key放入HashMap中
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// 删除HashSet中的元素(o),其实是在HashMap中删除了以o为key的Entry
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
//清空HashMap的clear方法清空所有Entry
public void clear() {
map.clear();
}
// 克隆一个HashSet,并返回Object对象
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}
// java.io.Serializable的写入函数
// 将HashSet的“总的容量,加载因子,实际容量,所有的元素”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out HashMap capacity and load factor
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
// Write out size
s.writeInt(map.size());
// Write out all elements in the proper order.
for (Iterator i=map.keySet().iterator(); i.hasNext(); )
s.writeObject(i.next());
}
// java.io.Serializable的读取函数
// 将HashSet的“总的容量,加载因子,实际容量,所有的元素”依次读出
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in HashMap capacity and load factor and create backing HashMap
int capacity = s.readInt();
float loadFactor = s.readFloat();
map = (((HashSet)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
}
从上述HashSet源代码可以看出,它其实就是一个对HashMap的封装。所有放入HashSet中的集合元素实际上由HashMap的key来保存,而HashMap的value则存储了一个PRESENT,它是一个静态的Object对象。
HashSet的绝大部分方法都是通过调用HashMap的方法来实现的,因此HashSet和HashMap两个集合在实现本质上是相同的。
根据HashMap的一个特性: 将一个key-value对放入HashMap中时,首先根据key的hashCode()返回值决定该Entry的存储位置,如果两个key的hash值相同,那么它们的存储位置相同。如果这个两个key的equalus比较返回true。那么新添加的Entry的value会覆盖原来的Entry的value,key不会覆盖。因此,如果向HashSet中添加一个已经存在的元素,新添加的集合元素不会覆盖原来已有的集合元素。
通过一个实际的例子来真正理解下HashMap和HashSet存储元素的细节:
class Name
{
private String first;
private String last;
public Name(String first, String last)
{
this.first = first;
this.last = last;
}
public boolean equals(Object o)
{
if (this == o)
{
return true;
}
if (o.getClass() == Name.class)
{
Name n = (Name)o;
return n.first.equals(first)
&& n.last.equals(last);
}
return false;
}
}
public class HashSetTest
{
public static void main(String[] args)
{
Set<Name> s = new HashSet<Name>();
s.add(new Name("abc", "123"));
System.out.println(
s.contains(new Name("abc", "123")));
}
}上面程序中向HashSet里添加了一个new Name(“abc”,”123”)对象之后,立即通过程序判断该HashSet里是否包含一个new Name(“abc”,”123”)对象。粗看上去,很容易以为该程序会输出true。
实际上会输出false。因为HashSet判断两个对象相等的标准是想通过hashCode()方法计算出其hash值,当hash值相同的时候才继续判断equals()方法。而如上程序我们并没有重写hashCode()方法。所以两个Name类的hash值并不相同,因此HashSet会把其当成两个对象来处理。
所以,当我们要将一个类作为HashMap的key或者存储在HashSet的时候。通过重写hashCode()和equals(Object object)方法很重要,并且保证这两个方法的返回值一致。当两个类的hashCode()返回一致时,应该保证equasl()方法也返回true。当给上述Name类增加如下方法:
public void hashCode(){
return first.hashCode()+last.hashCode();
}此时我们测试的方法会返回true。
参考1
总结
元素的哈希值是通过元素的hashcode方法来获取的, HashSet首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals方法 如果 equls结果为true ,HashSet就视为同一个元素。如果equals 为false就不是同一个元素。
哈希值相同equals为false的元素是怎么存储呢,就是在同样的哈希值下顺延(可以认为哈希值相同的元素放在一个哈希桶中),也就是哈希一样的存一列。
图1:hashCode值不相同的情况
图2:hashCode值相同,但equals不相同的情况。
HashSet:通过hashCode值来确定元素在内存中的位置。一个hashCode位置上可以存放多个元素。
HashSet如何判断两个元素重复
通过hashCode方法和equals方法来保证元素的唯一性,add()返回的是boolean类型。
判断两个元素是否相同,先要判断元素的hashCode值是否一致,只有在该值一致的情况下,才会判断equals方法,如果存储在HashSet中的两个对象hashCode方法的值相同且equals方法返回的结果是true,那么HashSet认为这两个元素是相同元素,只存储一个(重复元素无法存入)。
注意:HashSet集合在判断元素是否相同先判断hashCode方法,如果相同才会判断equals。如果不相同,是不会调用equals方法的。
HashSet 和ArrayList集合都有判断元素是否相同的方法,
boolean contains(Object o)
HashSet使用hashCode和equals方法,ArrayList使用了equals方法。
实例:
使用HashSet存储字符串,并尝试添加重复字符串,
回顾String类的equals()、hashCode()两个方法。
public class Demo {
public static void main(String[] args) {
// Set 集合存和取的顺序不一致。
Set hs = new HashSet();
hs.add("世界军事");
hs.add("兵器知识");
hs.add("舰船知识");
hs.add("汉和防务");
// 返回此 set 中的元素的数量
System.out.println(hs.size()); // 4
// 如果此 set 尚未包含指定元素,则返回 true
boolean add = hs.add("世界军事"); // false
System.out.println(add);
// 返回此 set 中的元素的数量
System.out.println(hs.size());// 4
Iterator it = hs.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
} 使用HashSet存储自定义对象,并尝试添加重复对象(对象的重复的判定)
public class Demo {
public static void main(String[] args) {
HashSet hs = new HashSet();
hs.add(new Person("jack", 20));
hs.add(new Person("rose", 20));
hs.add(new Person("hmm", 20));
hs.add(new Person("lilei", 20));
hs.add(new Person("jack", 20));
Iterator it = hs.iterator();
while (it.hasNext()) {
Object next = it.next();
System.out.println(next);
}
}
}
class Person {
private String name;
private int age;
Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
System.out.println("hashCode:" + this.name);
return this.name.hashCode() + age * 37;
}
@Override
public boolean equals(Object obj) {
System.out.println(this + "---equals---" + obj);
if (obj instanceof Person) {
Person p = (Person) obj;
return this.name.equals(p.name) && this.age == p.age;
} else {
return false;
}
}
@Override
public String toString() {
return "Person@name:" + this.name + " age:" + this.age;
}
}
TreeSet
问题:现在有一批数据,要求去除重复元素,而且要排序。ArrayList 、 LinkedList可以顺序存储但不能去除重复数据。HashSet可以去除重复,但是是无序。
public class Demo5 {
public static void main(String[] args) {
TreeSet ts = new TreeSet();
ts.add("ccc");
ts.add("aaa");
ts.add("ddd");
ts.add("bbb");
System.out.println(ts); // [aaa, bbb, ccc, ddd]
}
} ---| Itreable 接口 实现该接口可以使用增强for循环
---| Collection 描述所有集合共性的接口
---| List接口 有序,可以重复,有角标的集合
---| ArrayList
---| LinkedList
---| Set接口 无序,不可以重复的集合
---| HashSet 线程不安全,存取速度快。底层是以hash表实现的。
---| TreeSet 红-黑树的数据结构,默认对元素进行自然排序(String)。如果在比较的时候两个对象返回值为0,那么元素重复。红黑树
红黑树是一种特定类型的二叉树。
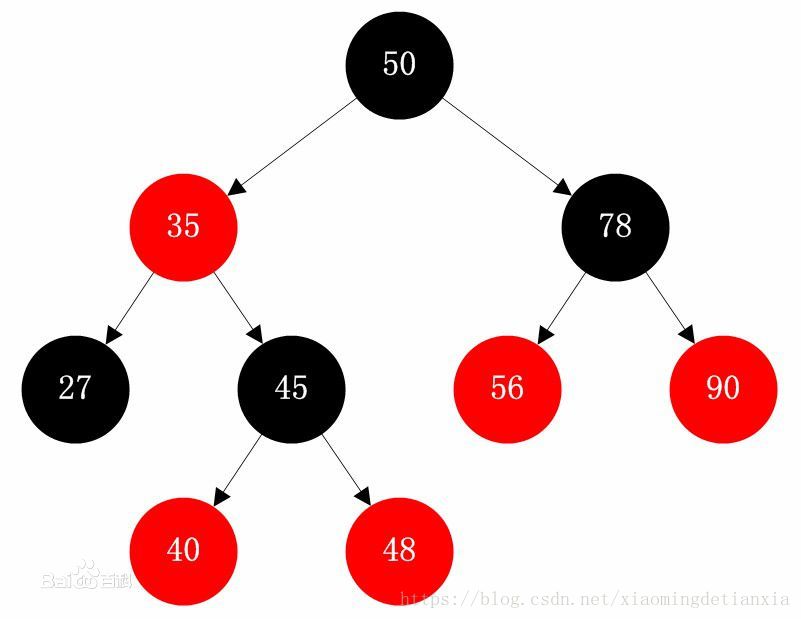
红黑树算法的规则: 左小右大。
既然TreeSet可以自然排序,那么TreeSet必定是有排序规则的:
1:让存入的元素自定义比较规则
2:给TreeSet指定排序规则
方式一:元素自身具备比较性
元素自身具备比较性,需要元素实现Comparable接口,重写compareTo方法,也就是让元素自身具备比较性,这种方式叫做元素的自然排序也叫做默认排序。
方式二:容器具备比较性
当元素自身不具备比较性,或者自身具备的比较性不是所需要的。那么此时可以让容器自身具备。需要定义一个类实现接口Comparator,重写compare方法,并将该接口的子类实例对象作为参数传递给TreeMap集合的构造方法。
注意
(1)当Comparable比较方式和Comparator比较方式同时存在时,以Comparator的比较方式为主;
(2)在重写compareTo或者compare方法时,必须要明确比较的主要条件相等时要比较次要条件。(假设姓名和年龄一致的人为相同的人,如果想要对人按照年龄的大小来排序,如果年龄相同的人,需要如何处理?不能直接return 0,因为可能姓名不同(年龄相同姓名不同的人是不同的人)。此时就需要进行次要条件判断(需要判断姓名),只有姓名和年龄同时相等的才可以返回0.)
通过return 0来判断唯一性,若 添加元素时返回结果为0,则说明元素重复。
问题
(1)为什么使用TreeSet存入字符串,字符串默认输出是按升序排列的?
因为字符串实现了一个接口,叫做Comparable 接口.字符串重写了该接口的compareTo 方法,所以String对象具备了比较性。那么同样道理,我们自定义元素(例如Person类,Book类)想要存入TreeSet集合,就需要实现该接口也就是要让自定义对象具备比较性。
存入TreeSet集合中的元素要具备比较性,比较性要实现Comparable接口,重写该接口的compareTo方法
TreeSet属于Set集合,该集合的元素是不能重复的,TreeSet如何保证元素的唯一性
通过compareTo或者compare方法中的来保证元素的唯一性。
添加的元素必须要实现Comparable接口。当compareTo()函数返回值为0时,说明两个对象相等,此时该对象不会添加进来。

















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









