




 本文详细介绍了在CentOS7系统中,使用Hadoop2.9.2搭建完全分布式集群的步骤,包括准备虚拟机、修改IP和主机名、安装必要软件、配置Hadoop和JDK、设置环境变量、配置主机名和Hadoop配置文件、关闭防火墙、克隆虚拟机、修改克隆后的IP和主机名、配置SSH免密登录、启动和停止Hadoop集群以及一些额外的辅助操作。
本文详细介绍了在CentOS7系统中,使用Hadoop2.9.2搭建完全分布式集群的步骤,包括准备虚拟机、修改IP和主机名、安装必要软件、配置Hadoop和JDK、设置环境变量、配置主机名和Hadoop配置文件、关闭防火墙、克隆虚拟机、修改克隆后的IP和主机名、配置SSH免密登录、启动和停止Hadoop集群以及一些额外的辅助操作。
本次搭建是基于centos7、Hadoop2.9.2进行搭建
1、先准备一台虚拟机
2、修改IP
- #>vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.101
NETMASK=255.255.255.0
GATWAY=192.168.159.2
DNS1=192.168.159.2重启网卡服务
#>systemctl restart network
ping 一下百度
#>ping www.baidu.com
在Windows中的cmd里ping一下刚刚配置的IP地址
$>ping 192.168.159.101
如果两个都能ping通,那么证明网络配置没问题。
这时可以使用xShell链接虚拟机进行搭建
3、修改主机名
#>hostnamectl set-hostname hadoop01
4、安装必要的软件
#>yum install vim
#>yum install net-tools
5、将Hadoop和jdk拷贝到Hadoop01
我所使用的事filezille进行拷贝
- 创建文件夹方便管理
#>mkdir /opt/module - 上传文件

- 解压文件
#>tar -zxf hadoop-2.9.2.tar.gz
#>tar -zxf jdk-8u201-linux-x64.tar.gz - 删除tar包
#>rm -rf hadoop-2.9.2.tar.gz
#>rm -rf jdk-8u201-linux-x64.tar.gz - 在/opt目录下创建符号链接方便管理
#>cd /opt
#>ln -s /opt/module/hadoop-2.9.2 hadoop
#>ln -s /opt/module/jdk1.8.0_201 jdk
6、配置环境变量
#>vim /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
##JAVA_HOME
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
生效环境变量
#>source /etc/profile
测试环境变量
#>java -version
#>hadoop version
7、配置Hadoop的主机名的全局变量
#>vim /etc/hosts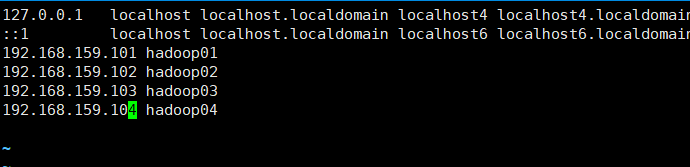
8、修改Hadoop的配置文件
#>cd /opt/hadoop/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/opt/jdk
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01/</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/dfs/name/</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/dfs/data</value>
</property>
</configuration>vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<property>
</configuration>vim slaves
hadoop02
hadoop03
hadoop049、关闭防火墙
#>systemctl stop firewalld
#>systemctl disable firewalld
10、关机,进行克隆
由于我配置的是四台虚拟机,所以需要克隆三台
11、修改克隆的四台IP
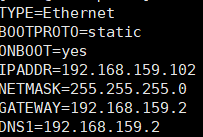
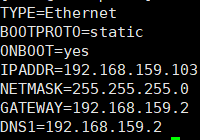
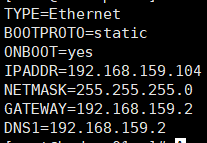
使用xShell连接
12、修改每一台主机的主机名
#>hostnamectl set-hostname hadoop02
#>hostnamectl set-hostname hadoop03
#>hostnamectl set-hostname hadoop04
13、配置ssh免密登录
#>cd ~/.ssh
在hadoop01主机上生成密钥对
-
#>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
在Hadoop02-04上创建.ssh的文件夹
- #>mkdir ~/.ssh
将hadoop01的公钥文件id_rsa.pub远程复制到hadoop01、hadoop02、hadoop03、hadoop04,并放到/root/.ssh/authorized_keys
-
#>scp id_rsa.pub root@hadoop03:/root/.ssh/authorized_keys
使用ssh登录每一台机器看看需不需要密码,如果不需要密码就配置成功
- #>ssh hadoop02
14、启动Hadoop集群
#>start-all.sh
停止Hadoop集群
#>stop-all.sh
15、一些杂项
启动Hadoop后可以使用jps查询进程
这是namenode该有的进程
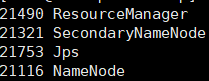
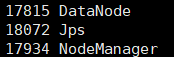
这是其他datanode该有的进程
使用脚本一键查询jps
在每一台虚拟机上创建符号连接
#>ln -s /opt/jdk/bin/jps /usr/local/bin/jps
查询出来的效果
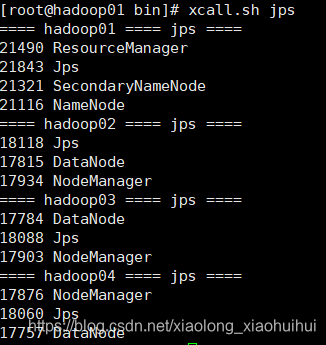
关于脚本我会在下载中分享我的脚本,或者自己写
脚本地址:https://download.youkuaiyun.com/download/xiaolong_xiaohuihui/11058937
结语,Hadoop集群配置到这结束了,启动Hadoop时出现问题,就去/opt/hadoop/logs下查看相对于的日志文件,发现错误到百度查询相对应的解决方案

















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









