




一、master/slave方案
1、搭建master服务器
$:mongod --dbpath=./../data --master --oplogSize 64 --port 5566
2、搭建slave服务器
$:mongod --slave --source 10.10.20.48:5566 --dbpath=./../dataSlave --port 5567 --slavedelay 10 --only test --autoresync
3、尝试从slave插入数据
$:mongod 10.10.20.48:5567
$:use masterSlave
$:db.info.insert({“name”:”luo”})
此处报错:not master
4、尝试从master插入数据,slave查看数据
$: mongod 10.10.20.48:5566
$:use masterSlave
$:db.info.insert({“name”:”luo”})
此处插入数据成功
$:db.info.find()
{ "_id" : ObjectId("548e954b0cd7253b60dc1601"), "name" : "luo" }
从slave查看:
$:mongod 10.10.20.48:5567
$:use masterSlave
$:db.info.find()
{ "_id" : ObjectId("548e954b0cd7253b60dc1601"), "name" : "luo" }
查询成功。
5、结论
能够指定需要备份的数据库,按照设置的时间间隔进行自动备份,slave服务器只能进行查询操作。
优点:无需修改代码。
缺点:不支持故障切换。
二 :Replica Set,中文翻译叫做副本集,不过我并不喜欢把英文翻译成中文,总是感觉怪怪的。其实简单来说就是集群当中包含了多份数据,保证主节点挂掉了,备节点能继续提供数据服务,提供的前提就是数据需要和主节点一致

Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务,这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做Read Preference Modes,同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。我开始也不相信必须要有仲裁节点,但是自己也试过没仲裁节点的话,主节点挂了备节点还是备节点,所以咱们还是需要它的。
支持故障切换。
三 :分片与副本集结合
1)架构图:
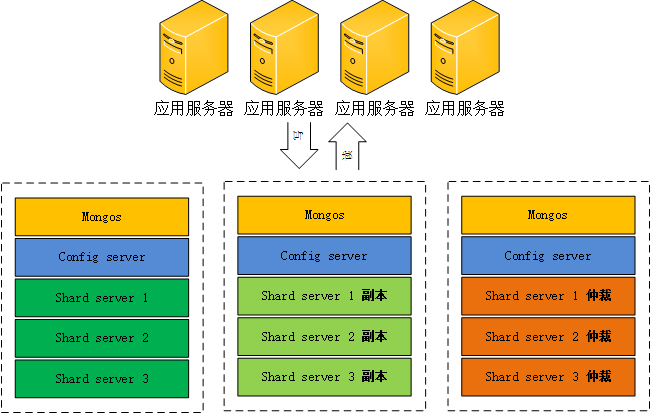
2)四个组件:mongos、config server、shard、replica set
mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
config server,顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。
Shard,和大数据存储HDFS分片存储的思想的东西。
Replica set,副本集服务器。
3)优点:
支持大数据存储(避免单机性能问题),
支持故障切换。
缺点:分片查询影响查询性能。

















 1503
1503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









