




 本文详细介绍了使用Scrapy框架编写爬虫的步骤,包括新建工程目录、定义Items、编写Spider选择器、设置Pipelines进行数据存储,以及常见的错误处理。此外,还提及了如何爬取列表页中所有URL的技巧。
本文详细介绍了使用Scrapy框架编写爬虫的步骤,包括新建工程目录、定义Items、编写Spider选择器、设置Pipelines进行数据存储,以及常见的错误处理。此外,还提及了如何爬取列表页中所有URL的技巧。
最近又要新写一个网站的爬虫,虽然写了好几个了,但每次写都要再来现看一遍资料,觉得还是有必要写一篇,记录一下。
一、编写步骤
1、新建工程目录
进入打算存储代码的目录中,命令行运行下列命令:
scrapy startproject 目录或爬虫名称
2、用pycharm打开此目录,可看到如下目录结构

3、items.py文件中定义item,主要是网页中要提取的一个单位数据元中包含的字段。

4、新建一个spider类,需要特别注意文件名称不能与工程名称相同,否则会导致文件内的引用出错(错误列表2)!

且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
#coding=utf-8 import scrapy import sys reload(sys) sys.setdefaultencoding('utf-8') from alexaurl.items import AlexaurlItem from alexaurl.Logger import mylog class DmozSpider(scrapy.spiders.Spider): name = "alexaurl" allowed_domains = ["alexa.cn"] start_urls = [] urls = { "http://www.alexa.cn/siterank" : u'总榜' } for classify_url in urls: for j in range(1, 2): start_urls.append(classify_url+"/"+str(j)) def parse(self, response): province = '' for sel1 in response.xpath("//div[@class='siterank-list']/dl/dd/a[@class='on']"): province = sel1.xpath('text()').extract()[0] for sel in response.xpath("//div[@class='layout wrap']/dl/dd/ul//li"): item = AlexaurlItem() item['ranking'] = int(sel.xpath("div[@class='rank-index']/text()").extract()[0]) item['domain'] = sel.xpath("div[@class='info-wrap']/div[@class='domain']/a/text()").extract()[0] item['classify'] = province yield item
编写选择器提取Item:
使用开发者工具找到要提取的每个Item所在的位置
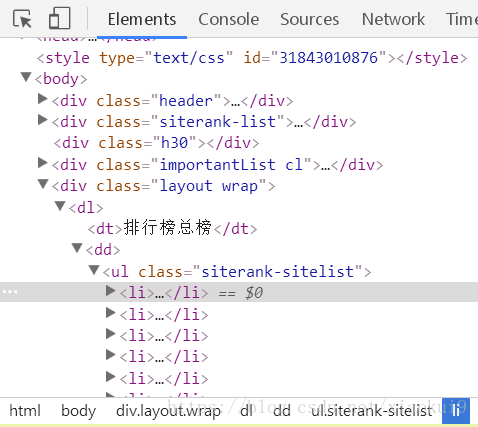
//div[@class='layout wrap']/dl/dd/ul//li//:两个斜杆表示所有的li节点
[@class='']或者[@id='']:表示指定属性,在选择器的任意一级都可以加指定属性来过滤
sel.xpath("div[@class='rank-index']/text()").extract()[0])
/text():用于提取该节点包含的内容
.extract():用于序列化该节点为unicode字符串并返回list,所以取具体的值,还需要用[0]来获取元素值。
另外还可以用re()来使用正则表达式过滤,例如sel.xpath('//title/text()').re('(\w+):')
5、使用pipelines.py进行数据存储
在settings.py里定义
# Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'alexaurl.pipelines.AlexaurlPipeline': 300, 'alexaurl.pipelines.JsonWithEncodingPipeline': 300, }
#Mysql数据库的配置信息 MYSQL_HOST = '127.0.0.1' MYSQL_DBNAME = 'aaa' #数据库名字,请修改 MYSQL_USER = 'root' #数据库账号,请修改 MYSQL_PASSWD = 'aaa' #数据库密码,请修改 MYSQL_PORT = 3306 #数据库端口
在pipelines.py中编写
JsonWithEncodingPipeline类是实现记录到json文件中,AlexaurlPipeline类实现的是存储至数据库中。
# -*- coding: utf-8 -*- import json import codecs from twisted.enterprise import adbapi import MySQLdb import MySQLdb.cursors import sys reload(sys) sys.setdefaultencoding("utf-8") from alexaurl.Logger import mylog import time # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class AlexaurlPipeline(object): count = 0 def __init__(self,dbpool): self.dbpool=dbpool def process_item(self, item, spider): query = self.dbpool.runInteraction(self._conditional_insert,item)#调用插入的方法 query.addErrback(self._handle_error, item, spider)#调用异常处理方法 return item @classmethod def from_settings(cls,settings): '''1、@classmethod声明一个类方法,而对于平常我们见到的则叫做实例方法。 2、类方法的第一个参数cls(class的缩写,指这个类本身),而实例方法的第一个参数是self,表示该类的一个实例 3、可以通过类来调用,就像C.f(),相当于java中的静态方法''' dbparams = dict( host=settings['MYSQL_HOST'],#读取settings中的配置 db=settings['MYSQL_DBNAME'], user=settings['MYSQL_USER'], passwd=settings['MYSQL_PASSWD'], charset='utf8',#编码要加上,否则可能出现中文乱码问题 cursorclass=MySQLdb.cursors.DictCursor, use_unicode=False, ) dbpool = adbapi.ConnectionPool('MySQLdb', **dbparams)#**表示将字典扩展为关键字参数,相当于host=xxx,db=yyy.... return cls(dbpool)#相当于dbpool付给了这个类,self中可以得到 #写入数据库中,请自行修改 def _conditional_insert(self, tx, item): sql="insert into " params = (item["ranking"], ) tx.execute(sql, params) #错误处理方法 def _handle_error(self, failure, item, spider): mylog.error(failure) mylog.error('failure item:'+str(item)) print failure class JsonWithEncodingPipeline(object): '''保存到文件中对应的class 1、在settings.py文件中配置 2、在自己实现的爬虫类中yield item,会自动执行''' def __init__(self): self.file = codecs.open('info.json', 'w', encoding='utf-8')#保存为json文件 def process_item(self, item, spider): line = json.dumps(dict(item)) + "\n"#转为json的 self.file.write(line)#写入文件中 return item def spider_closed(self, spider):#爬虫结束时关闭文件 self.file.close()
二、出错列表
1、KeyError: 'Spider not found: alexaurl'
网上说的原因主要有:没有定义name,settings里面的SPIDER_MODULES没有定义。
最后发现原因可在输出中找出来是由于出的第2个错误导致的(因为把那几行注释掉就可以正常运行了)
2、scrpy ImportError: No module named items,下列语句出错
from alexaurl.items import AlexaurlItem网上搜索,原因是之前将alexaurl_spider.py文件的名称命名成alexaurl.py了,这样会导致引入出错。
https://stackoverflow.com/questions/10570635/scrapy-importerror-no-module-named-items
三、番外:
另外之前的爬虫做过,就是爬取一个页面里面列表对应的所有的url的网页内容,记录一下:
可参考http://ju.outofmemory.cn/entry/19798
1、主要是在parse函数最后返回要写成
yield Request(detail_link, meta={'item': item}, callback=self.parse2)
变量detail_link就是要进一步爬取的链接的url,变量item就是要定义一个item传进去parse2函数,在parse2函数里可以对item赋值。
2、然后parse2函数里面可以和在parse函数中一样利用response.xpath获取进一步要爬取的url页面里的信息,通过response.meta['item']来获取item变量
def parse2(self, response): try: item = response.meta['item'] content_size = response.xpath("/html/script[1]/text()").extract()[0]
最后返回
return item

















 2013
2013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









