




 本文介绍了如何使用Python编写一个URL采集器,通过百度搜索关键词获取网站链接,并结合Exp进行批量验证。通过分析百度搜索的URL参数,作者构建了一个简单的爬虫,过滤无效链接,并在链接后附加Exp进行测试,最终将成功利用的链接保存在文本文件中。此外,文章还提及了验证模块的实现,通过检查页面内容中的特定标记来确定Exp是否有效。
本文介绍了如何使用Python编写一个URL采集器,通过百度搜索关键词获取网站链接,并结合Exp进行批量验证。通过分析百度搜索的URL参数,作者构建了一个简单的爬虫,过滤无效链接,并在链接后附加Exp进行测试,最终将成功利用的链接保存在文本文件中。此外,文章还提及了验证模块的实现,通过检查页面内容中的特定标记来确定Exp是否有效。
前言:
最近几天在整理从各处收集来的各种工具包,大大小小的塞满了十几个G的硬盘,无意间发现了一个好几年前的0day。心血来潮就拿去试了一下,没想到真的还可以用,不过那些站点都已经老的不像样了,个个年久失修,手工测了几个发现,利用率还挺可观,于是就想配合url采集器写一个批量exp的脚本。于是就有了今天这一文。结尾附上一枚表哥论坛的邀请码一不小心买多了。先到先得哦。
开始:
环境,及使用模块:
Python3
Requests
Beautifulsuop
Hashlib
老规矩先明确目标
- 需要编写一个url采集器,收集我们的目标网址,
- 需要将我们的exp结合在其中。
先看一下exp 的格式吧,大致是这样的:
exp:xxx/xxx/xxx/xxx
百度关键字:xxxxxx
利用方式在网站后加上exp,直接爆出管理账号密码,
像这样:www.baidu.com/xxx/xxx/xxxxxxxxx
PS:后面都用这个代替我们的代码中
再放个效果图 没错就是这样。直接出账号密码哈哈哈。
没错就是这样。直接出账号密码哈哈哈。

url采集模块:
首先我们要编写一个基于百度搜索的url采集器。我们先来分析一下百度的搜索方式,
我们打开百度,输入搜索关键字 这里用芒果代替。
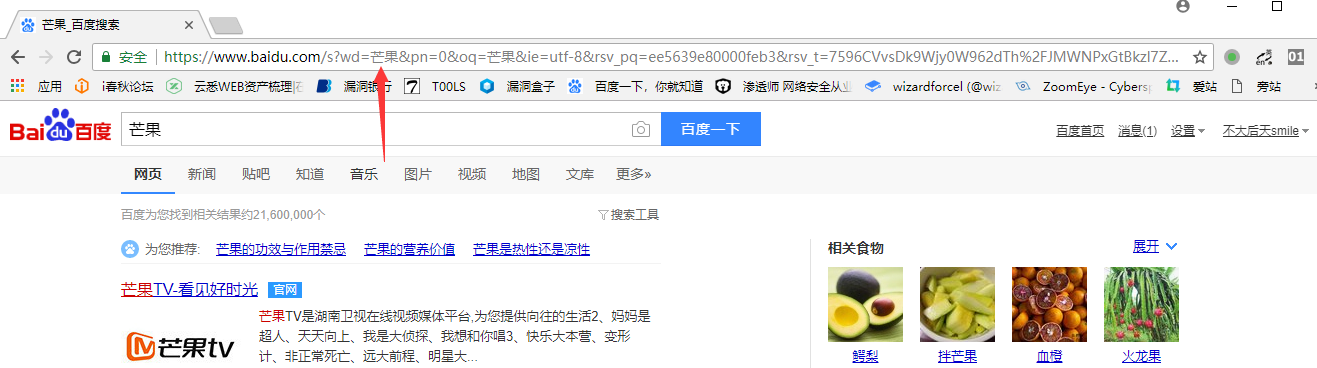 可以看到wd参数后跟着我们的关键字,我们点击一下第二页看下页码是哪个参数在控制。
可以看到wd参数后跟着我们的关键字,我们点击一下第二页看下页码是哪个参数在控制。
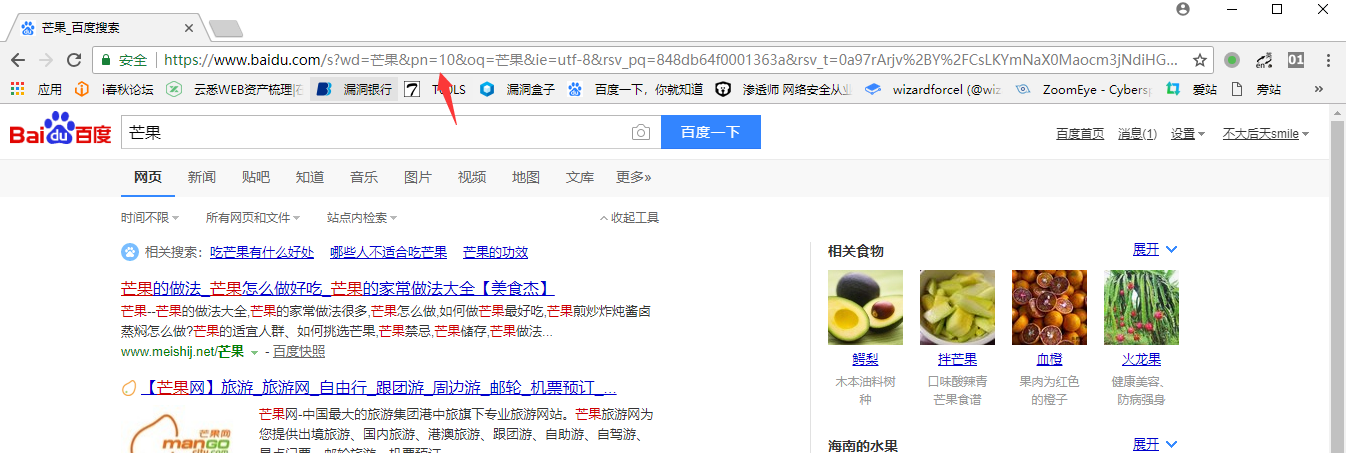 好的我们和前面url对比一下会发现pn参数变成了10,同理我们开启第三页第四页,发现页码的规律是从0开始每一页加10.这里我们修改pn参数为90看下是不是会到第十页。
好的我们和前面url对比一下会发现pn参数变成了10,同理我们开启第三页第四页,发现页码的规律是从0开始每一页加10.这里我们修改pn参数为90看下是不是会到第十页。
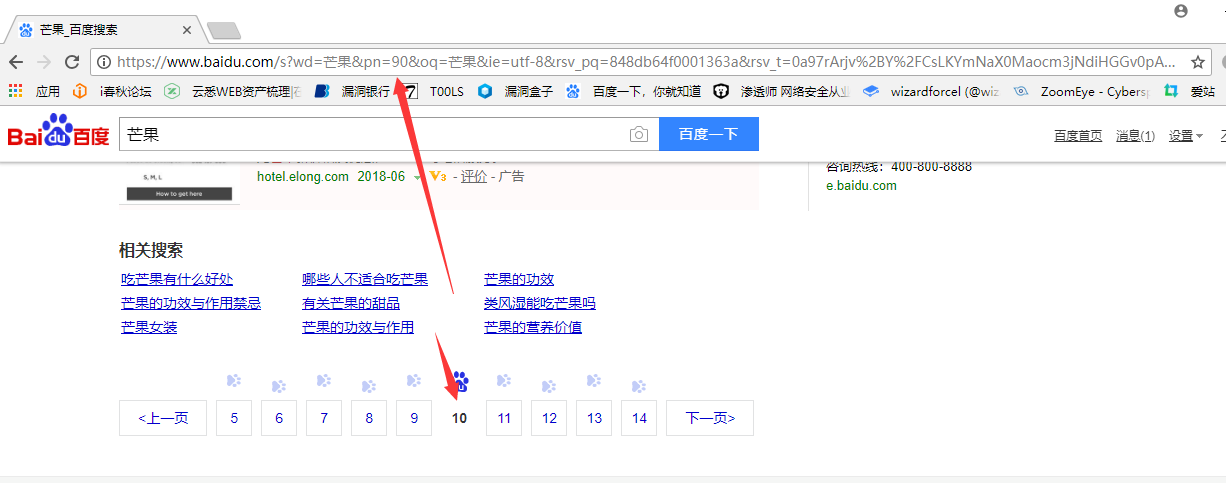
可以看到真的变成第十页了,证明我们的想法是正确的。我们取出网址如下
https://www.baidu.com/s?wd=芒果&pn=0
这里pn参数后面的东西我们可以不要,这样就精简很多。
我们开始写代码。我们先需要一个main函数打开我们的百度网页,我们并利用for循环控制页码变量,实现打开每一页的内容。
先实现打开一页网站,代码如下
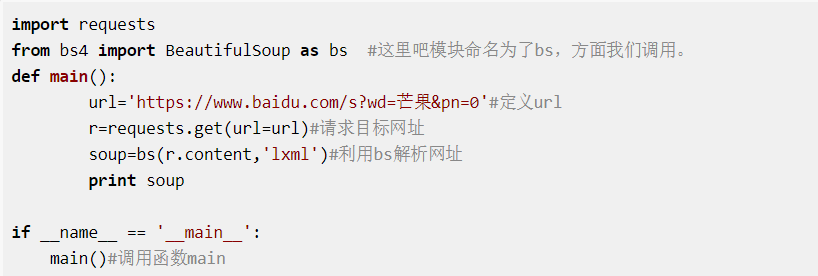 我们运行一下发现返回的页面是这样的,并没有我们想要的内容。
我们运行一下发现返回的页面是这样的,并没有我们想要的内容。
 这是为什么,原因就是因为百度是做了反爬的,但是不用担心,我们只要加入headers参数,一起请求就可以了。修改后代码如下:
这是为什么,原因就是因为百度是做了反爬的,但是不用担心,我们只要加入headers参数,一起请求就可以了。修改后代码如下:
def main():
url='https://www.baidu.com/s?wd=芒果&pn=0'#定义url
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}#这里百度是加了防爬机制的,需要加上user_agent验证一下否则就会返回错误
r=requests.get(url=url,headers=headers)#请求目标网址
soup=bs(r.content,'lxml')#利用bs解析网址
print soup
这样在运行,就可以看到成功的返回了网页内容。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









