







 Apache Flume是一个用于高效、可靠、分布式的海量日志聚合的系统。它可以从各种数据源如socket、文件、MySQL、Kafka等收集数据,将其汇聚并存储到大数据系统如HDFS、HBase、Hive等。本文介绍了Flume的基本概念、解决问题、安装步骤以及启动和使用方法,同时提到了Flume内置的监控功能,包括通过Ganglia进行监控。
Apache Flume是一个用于高效、可靠、分布式的海量日志聚合的系统。它可以从各种数据源如socket、文件、MySQL、Kafka等收集数据,将其汇聚并存储到大数据系统如HDFS、HBase、Hive等。本文介绍了Flume的基本概念、解决问题、安装步骤以及启动和使用方法,同时提到了Flume内置的监控功能,包括通过Ganglia进行监控。
Flume简介
1. flume是什么
- 官网
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hdfs-sink

- Flume 简单结构

2. flume解决什么问题
- 在海量数据处理中,日志数据是很重要一类数据
- 如何从集群中将日志文件采集出来,并且考虑各种失败重试等机制是比较复杂的问题,要代码实现也比较消耗精力。这时候各种第三方框架就应运而生。
- flume作为hadoop母公司cloudera出品的分布式日志采集框架,质量还是有保证的。
- flume可以从各种数据源上采集数据,日志数据形式可以多种多样,然后汇聚到各种大数据存储系统中,hdfs,hbase,hive,kafka等等
- flume可以从socket、文件、mysql、kafaka等数据源进行数据采集。
- 可以将flume理解为一个分布式抽水机,从各种水源抽水,抽到一个地方存起来。
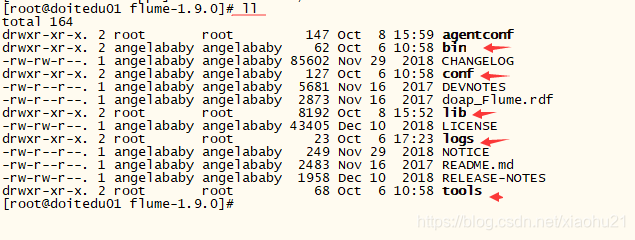
3. flume怎么安装
- 解压缩安装包
- 编写配置文件,然后使用flume-ng启动即可
4. flume怎么使用
- 启动指令
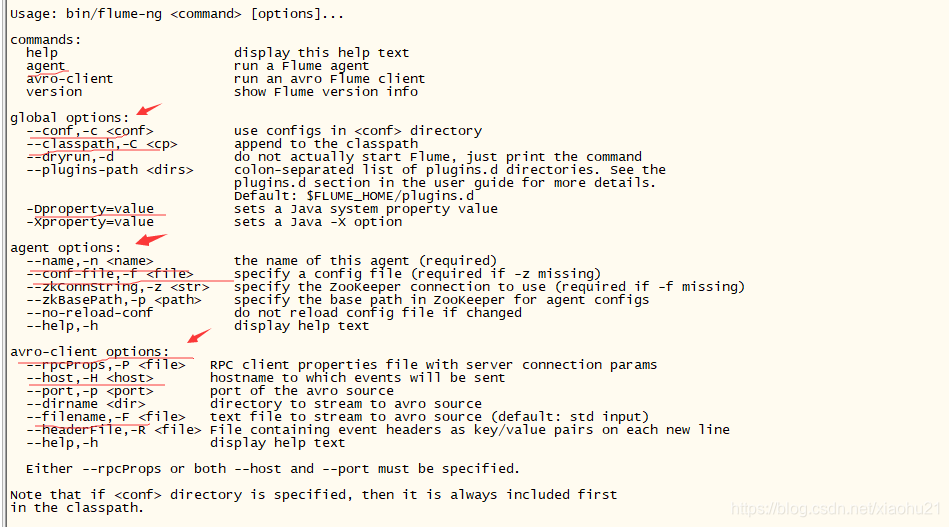
bin/flume-ng agent -c ./conf -f ./agentconf/test1.properties -n a1 -Dflume.root.logger=DEBUG,console
- -c ./conf 这个就是系统配置文件所在路径
- -f ./agentconf/test1.properties 这是自定义flume配置文件所在路径
- -n a1 这是agent在自定义配置文件中的名字
- -Dflume.root.logger=DEBUG,console这是配置log4j的参数,这里是将Debug等级的日志,打印输出到console中,方便做调试查看
bin/flume-ng agent -n a1 -c conf -f myconf/netcat-logger.conf 1>/dev/null 2>&1 &
- 上述指令,可以让flume进行后台执行,
1>/dev/null 这是flume执行的标准输出重定向,定向到lunux的黑洞文件夹中去,也就是丢弃掉
2>&1 这是将flume的标准错误输出,也定向到参数的输出中去
& 这是进行后台程序运行的linux参数设置
注意,flume也是可以做监控的
2. 内置监控(启动时,带上下面参数即可,就跟加log4j的参数一样)
-Dflume.monitoring.type=http -Dflume.monitoring.port=34545
- ganglia监控
-Dflume.monitoring.type=ganglia -Dflume.monitoring.port=34890
- ganglia
博客:https://www.oschina.net/p/ganglia?hmsr=aladdin1e1
官网:http://ganglia.info/


















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









