






 本文主要介绍了Spark中RDD的常用Transformation算子,包括map、flatMap、filter、mapPartitions、mapPartitionsWithIndex、sortBy、sortByKey、groupByKey、reduceByKey、distinct、union、keys、values、mapValues和flatMapValues。这些算子在分布式数据处理中起到关键作用,使得Spark具备高性能和易用性。
本文主要介绍了Spark中RDD的常用Transformation算子,包括map、flatMap、filter、mapPartitions、mapPartitionsWithIndex、sortBy、sortByKey、groupByKey、reduceByKey、distinct、union、keys、values、mapValues和flatMapValues。这些算子在分布式数据处理中起到关键作用,使得Spark具备高性能和易用性。
Spark 总结之RDD(二)
1. 背景
- Spark作为分布式数据处理引擎,在企业实践中大量应用.对比Mapreduce既有性能上的优势,也有开发编程上的便捷性优势.
- Spark针对数据处理,对编程接口做了更高层级的抽象和封装,API使用起来更加方便.其中RDD DataSet DataFrame DStream等都是抽象出来的数据处理对象.
- RDD使用时会屏蔽掉具体细节,操作起来就跟操作Scala的集合对象一样便捷.
2. RDD常见算子和方法
2.1 RDD创建 查看方法
- RDD创建
package com.doit.rddInfo
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class RDDInfo1{
}
object RDDInfo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("spark://linux101:7077")
val sc = new SparkContext(conf)
val array: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
// 创建rdd
val rdd1: RDD[Int] = sc.parallelize(array)
val rdd2: RDD[Int] = sc.makeRDD(array)
// 指定数据分区,分区数决定了并行task数
val rdd3: RDD[Int] = sc.parallelize(array, 4)
val rdd4: RDD[Int] = sc.makeRDD(array, 6)
println(rdd1.collect().toBuffer)
println("======")
println(rdd2.collect().toBuffer)
println("======")
println(rdd3.collect().toBuffer)
println("======")
println(rdd4.collect().toBuffer)
println("======")
sc.stop()
}
}
- 查看分区数量
rdd1.partitions.length
2.2 RDD常见Transformation算子
1. map算子
- 最核心最关键的算子之一,顾名思义,主要是做转换数据使用,由此可以延伸出多种用途.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("spark://linux101:7077")
val sc = new SparkContext(conf)
val array: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
// 创建rdd
val rdd1: RDD[Int] = sc.parallelize(array)
// 数据转换
val mapedValue: RDD[Int] = rdd1.map(ele => ele * 10)
- map方法的源码
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))
}
private[spark] def clean[F <: AnyRef](f: F, checkSerializable: Boolean = true): F = {
ClosureCleaner.clean(f, checkSerializable)
f
}
上面可以看出,
map方法参数就是一个函数, 泛型T=>U
map方法返回是一个RDD
map方法内部实现是,先调用sc.clean(f),这是因为RDD内部包含的是数据来源和数据处理逻辑,最终是要转换为Task对象序列化之后分发给各个executor执行的,所以需要检查是否包含不可序列化的内容
接下来就是创建了一个MapPartitionsRDD对象,这个对象接收2个参数,一个是this,就是当前的RDD,一个是函数
(_, _, iter) => iter.map(cleanF),从函数构成来看,大致最后一个参数是一个迭代器,通过迭代器,让每个迭代器中元素应用一次传进来的函数
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
isOrderSensitive: Boolean = false)
extends RDD[U](prev) {
override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
override def getPartitions: Array[Partition] = firstParent[T].partitions
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
override def clearDependencies(): Unit = {
super.clearDependencies()
prev = null
}
@transient protected lazy override val isBarrier_ : Boolean =
isFromBarrier || dependencies.exists(_.rdd.isBarrier())
override protected def getOutputDeterministicLevel = {
if (isOrderSensitive && prev.outputDeterministicLevel == DeterministicLevel.UNORDERED) {
DeterministicLevel.INDETERMINATE
} else {
super.getOutputDeterministicLevel
}
}
}
上述可以看出,这个类是私有的,只针对Spark包开放
参数
@param prev the parent RDD.
@param f The function used to map a tuple of (TaskContext, partition index, input iterator) to
an output iterator.
@param preservesPartitioning Whether the input function preserves the partitioner, which should
befalseunlessprevis a pair RDD and the input function
doesn’t modify the keys.
@param isFromBarrier Indicates whether this RDD is transformed from an RDDBarrier, a stage
containing at least one RDDBarrier shall be turned into a barrier stage.
@param isOrderSensitive whether or not the function is order-sensitive. If it’s order
sensitive, it may return totally different result when the input order
is changed. Mostly stateful functions are order-sensitive.
2. flatMap算子
- 这个算子可以把数据压平,可以看成是先先map,然后map的结果展平.所以要求原始算子中包含的数据map之后是能够展平的集合,数组等形式,字符串也可以(字符串本质是字符数组)
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val array: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
val list = List("List(1, 2, 3)", "List(4, 5, 6)", "List(7, 8, 9)")
val listRdd: RDD[String] = sc.makeRDD(list)
val flattedRdd: RDD[String] = listRdd.flatMap(_.split(","))
val strings: Array[String] = flattedRdd.collect()
strings.foreach(println)
- 源码
/**
* Return a new RDD by first applying a function to all elements of this
* RDD, and then flattening the results.
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.flatMap(cleanF))
}
从上述源码可以看出,最终还是创建了一个MapPartitionsRDD,并且是针对每个分区使用迭代器取出每个分区中数据,然后使用flatmap来展平数据.
3. filter算子
顾名思义,这是用来过滤数据用的
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val array: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
// 创建rdd
val rdd1: RDD[Int] = sc.parallelize(array)
// 过滤
val filteredRdd: RDD[Int] = rdd1.filter(ele => ele % 2 == 0)
4. mapPartitions算子
这是将数据以分区形式进行处理, 其中参数是这个分区对应的迭代器,处理时以迭代器形式取出数据并处理.
注意, 迭代器模式由于其固有优点,在进行大数据处理时,应用很普遍.迭代器取数据,不会受限于内存容量,因为数据可以一条一条取出而不用一次性取出.第二迭代器可以对外屏蔽数据具体获取方式,只对外暴露对应数据和字段.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val array: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
// 创建rdd
val rdd1: RDD[Int] = sc.parallelize(array)
val mapPartitionedRDD: RDD[Int] = rdd1.mapPartitions(iter => iter.map(x => x + 100))
注意,如果需要创建比较重的对象,使用mapPartitions要比map更合适,因为可以针对一个数据分区建立一个共享对象,map则是一条数据建立一个.
例如建立jdbc连接等等,比较适合使用mapPartitions.
5. mapPartitionsWithIndex算子
mapPartitionsWithIndex类似于mapPartitions,但会带上分区序列号.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val array: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
// 创建rdd 注意,这里设置分区是2
val rdd1: RDD[Int] = sc.parallelize(array, 2)
val mapPartedRDD: RDD[(Int, Int)] = rdd1.mapPartitionsWithIndex((index, iter) => {
iter.map(e => (index, e))
})
println(mapPartedRDD.collect().toBuffer)
# 运算结果
ArrayBuffer((0,1), (0,2), (0,3), (0,4), (1,5), (1,6), (1,7), (1,8))
如果需要以分区为单位进行数据map处理,并且知道对应分区的index,则使用这个算子.
6. sortBy算子
顾名思义,这个算子是用于排序的.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val array: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
val rdd1: RDD[Int] = sc.makeRDD(array)
val res1: RDD[Int] = rdd1.sortBy(x => x, true)
val res2: RDD[Int] = rdd1.sortBy(x => x + "", false)
val res3: RDD[Int] = rdd1.sortBy(x => x.toString, false)
* ArrayBuffer(1, 2, 3, 4, 5, 6, 7, 8)
* ArrayBuffer(8, 7, 6, 5, 4, 3, 2, 1)
* ArrayBuffer(8, 7, 6, 5, 4, 3, 2, 1)
使用这个算子,对比sortByKey会更灵活,因为可以有更多的排序选择,例如内部元素是case class,则可以针对其中的属性来排序.
7. sortByKey算子
顾名思义,这是按照key进行排序的算子.所以如果需要对数据进行排序,这个算子只能针对key做排序.但如果有需要,可以将要排序的数据进行转换.排序之后再转换回去皆可.
实际在大数据处理中,数据的转换是非常常见的.例如针对kv数据做倒置,针对key做标记字符串拼接等等.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val tuples: Array[(Int, String)] = Array((1, "xx"), (2, "ee"), (3, "rr"), (4, "tt"))
val rdd1: RDD[(Int, String)] = sc.parallelize(tuples, 2)
val res: RDD[(Int, String)] = rdd1.sortByKey(false)
println(res.collect().toBuffer)
8. groupBy算子
使用groupBy,进行分类的算子.使用这个可以更加灵活进行数据处理.
注意,在做大数据处理时,一般不会直接对原始数据做处理,而是会尽量根据需求,将原始数据中需要查询的字段先抽离出来,然后基于抽离出来的数据进行处理.这样可以大大降低需要处理的数据,对整体的数据处理效率和性能都有很大提升.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List(("haha", 9), ("haha", -9), ("mim", 19), ("uyt", 100), ("pio", -20))
val rdd1: RDD[(String, Int)] = sc.makeRDD(list)
val res: RDD[(String, Iterable[(String, Int)])] = rdd1.groupBy(_._1)
println(res.collect().toBuffer)
ArrayBuffer((uyt,CompactBuffer((uyt,100))), (mim,CompactBuffer((mim,19))), (haha,CompactBuffer((haha,9), (haha,-9))), (pio,CompactBuffer((pio,-20))))
9. groupByKey算子
顾名思义,这是根据key进行分组.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List(("haha", 9), ("haha", -9), ("mim", 19), ("uyt", 100), ("pio", -20))
val rdd1: RDD[(String, Int)] = sc.makeRDD(list)
val groupedRDD: RDD[(String, Iterable[Int])] = rdd1.groupByKey()
println(groupedRDD.collect().toBuffer)
结果
ArrayBuffer((uyt,CompactBuffer(100)), (mim,CompactBuffer(19)), (haha,CompactBuffer(9, -9)), (pio,CompactBuffer(-20)))
10. reduceByKey算子
- 顾名思义,这里和mapreduce的reduce非常相似.- 不过从spark角度,这里是先在各个分区中做聚合,然后再统一聚合.
- 其实对比mapreduce的shuffle过程,和spark这里的大致思路是一样的.
- reduceByKey也是在各个分区中按照key分类,然后shuffle中,落地到 磁盘.最后再各个分区结果进行聚合.
- reduce过程,可以看做是有一个初始值,然后各个分区和这个初始值聚合,最后每一个分区的结果聚合到一起.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List(("haha", 9), ("haha", -9), ("mim", 19), ("uyt", 100), ("pio", -20))
val rdd1: RDD[(String, Int)] = sc.makeRDD(list)
val res: RDD[(String, Int)] = rdd1.reduceByKey((a, b) => {
a + b
})
println(res.collect().toBuffer)
11. distinct算子
这个和sql中的distinct语句类似,用于去重
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(2,2,3,3,4,4,5,5,6,6,7))
val res: RDD[Int] = rdd1.distinct()
println(res.collect().toBuffer)
计算结果
ArrayBuffer(2, 3, 4, 5, 6, 7)
12. union算子
这是对2个RDD做并集,后续还会有交集,差集等操作.
注意,合并之后,partitions是2个RDD的partitions之和.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(List(1, 2, 3), 2)
val rdd2: RDD[Int] = sc.parallelize(List(4, 5, 6, 7), 3)
val res: RDD[Int] = rdd1.union(rdd2)
println("分区数:"+res.partitions.length)
println(res.collect().toBuffer)
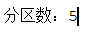
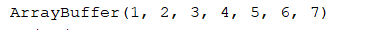
13. keys算子
注意,这个是针对map集合或者说对偶元组集合来说的. 类似于HashMap的keySet方法
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(List(("xx", 2), ("rr", 3), ("tt", 6), ("uu", 9)))
val res1: RDD[String] = rdd1.keys
println(res1.collect().toBuffer)
结果
ArrayBuffer(xx, rr, tt, uu)
源码实现

14. values算子
注意,这个是针对map集合或者说对偶元组集合来说的. 类似于HashMap的values方法
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(List(("xx", 2), ("rr", 3), ("tt", 6), ("uu", 9)))
val res1: RDD[Int] = rdd1.values
println(res1.collect().toBuffer)
运算结果
ArrayBuffer(2, 3, 6, 9)

15. mapValues算子
这个算子就是只针对value做处理,key不变.所以数据必须是对偶数组或者集合. 形成类似key value键值对的数据.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(List(("xx", 2), ("rr", 3), ("tt", 6), ("uu", 9)))
val res: RDD[(String, Int)] = rdd1.mapValues(e => e + 100)
println(res.collect().toBuffer)
运算结果
ArrayBuffer((xx,102), (rr,103), (tt,106), (uu,109))
16. flatmapValues算子
类似于mapValues,先map,然后就是flatten处理.
val conf = new SparkConf()
conf.setAppName(classOf[RDDInfo1].toString )
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.parallelize(List("a b c", "e r t", "t y u"))
val res: RDD[String] = rdd1.flatMap(e => e.split("\\s+"))
println(res.collect().toBuffer)
运算结果
ArrayBuffer(a, b, c, e, r, t, t, y, u)
总结
- 其实Spark的RDD函数设计,大量参考了scala的集合命名,并且有意识让2者相近.这样带来很大好处,使用时的门槛大大降低,并且顾名思义,降低了使用门槛.
- 所有的RDD最终都是分别作用于各个task以及对应的数据分区上.也就是说RDD是一个分布式的代码和数据处理抽象.

















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









