







 本文详细介绍了ClickHouse的安装流程,包括单机和集群安装步骤,重点关注在Centos7.x系统上集成Mysql5.7的配置。内容涵盖ClickHouse的基本概念、系统要求、安装方法以及官方文档的使用,适合初学者和进阶学习。
本文详细介绍了ClickHouse的安装流程,包括单机和集群安装步骤,重点关注在Centos7.x系统上集成Mysql5.7的配置。内容涵盖ClickHouse的基本概念、系统要求、安装方法以及官方文档的使用,适合初学者和进阶学习。
ClickHouse(三) 20.5安装流程(基于Centos7.x和Mysql5.7)
1.ClickHouse学习概览
带着问题学习
1.ClickHouse是什么?
2.ClickHouse解决了什么问题?
3.ClickHouse如何安装?
4.ClickHouse如何使用
5.ClickHouse注意事项
6.ClickHouse优缺点对比
2.ClickHouse简介
- 官网

- 按照官网介绍,ClickHouse就是一个开源,高性能的OLAP场景下的数据库管理系统。也就是说,这是一个数据库管理系统,适用于OLAP场景(快速,海量数据,准确,数据一次写多次读取)。是一个数据库管理系统,则说明可以进行数据库引擎的切换。其他就是它的技术指标,可以看到100—1000倍高于传统数据库。
- 对OLAP的了解,可以看我的另外一篇博客OLAP
3.ClickHouse安装流程
3.1. 单机安装流程
- 安装curl工具
yum install -y curl
- 添加clickhouse的yum镜像
curl -s https://packagecloud.io/install/repositories/altinity/clickhouse/script.rpm.sh | sudo bash
- 检查镜像情况
yum list | grep clickhouse

- 安装clickhouse的服务端和客户端
yum install -y clickhouse-server clickhouse-client
- 启动服务
service clickhouse-server start
- 启动交互式客户端
clickhouse-client
- clickhouse安装目录
- 在linux操作系统中,安装的第三方软件一般都在根目录下/的opt、usr、var子目录下
- 用户自定义安装一般在 /opt或者 /usr目录中
- 使用yum安装的软件,一般在 /var或者 /usr目录中
- linux根目录 / 截图

- var下的clickhouse安装目录路径

- 命令行启动参数
- clickhouse使用yum安装,自动注册了环境变量,所以可以在linux系统中任意路径执行clickhouse-client 启动命令行客户端
- 跟所有java生态下软件一样,如mysql、hdfs、zookeeper,都会提供多个访问方式。如命令行、java api
- clickhouse-client启动时,参数如下,官网文档https://clickhouse.tech/docs/en/interfaces/cli/

- 单机下使用,需要关注参数已经标注出来,特别关注-m参数,可以在使用时执行多行sql语句。一般都是在sql工具或者文本软件上写好sql语句,然后拷贝到clickhouse的命令行客户端执行,所以添加这个参数,可以很方便进行指令操作。
- 单机下使用,一般是学习或者研究,维护时使用较多。业务场景下,一般都是使用java api方式进行访问和操作处理数据。
3.2.集群安装流程
1.事前准备
- 准备好linux集群,自己学习可以使用vmware在自己的windows电脑上搭建linux集群,配置好基本的环境(jdk 1.8、mysql; 至于linux的软件工具看需要决定是否安装),可以参考我的另外一篇博客linux mysql安装 、 linux软件安装 、 vmware linux集群安装、vmware 软件介绍
- zookeeper集群安装,可以看我的另外一篇博客,zookeeper安装
- 先按照上述的单节点流程,在每台节点服务器上安装clickhouse
- 在linux各个节点服务器上配置好hosts,编辑/etc/hosts, 这样方便后续参数填写时,直接填写域名而不用填写ip地址,更方便参数查看和出错时查看。我的hosts文件如下

PS:可以把这个看成是linux操作系统下DNS的本地缓存文件,当进行域名和ip地址查找时,会先在本地查找域名对应的ip地址,找到了就可以将域名映射为ip地址。 - 在每台节点服务器的/etc目录下创建文件,使用vi命令创建文件。
PS:在企业中开发时,配置文件最好也加上注释,如果需要好看一些,中间可以像代码一样加上空格;代码可读性是非常重要的
vi /etc/metrika.xml
<yandex>
<clickhouse_remote_servers>
<!-- doit就是clickhouse集群的名字-->
<doit>
<!--shard可以看做是集群节点信息配置 -->
<shard>
<!-- internal_replication 内部数据备份功能,这里是开启的 -->
<internal_replication>true</internal_replication>
<!--replica 可以看做是每个节点的域名和端口配置-->
<replica>
<host>doit01</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>doit02</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>doit03</host>
<port>9000</port>
</replica>
</shard>
</doit>
</clickhouse_remote_servers>
<!--zookeeper-servers的信息配置,因为clickhouse集群是通过zookeeper进行集群的高可用和部分共同数据同步的,所以需要设置zookeeper集群信息-->
<zookeeper-servers>
<!-- zookeeper节点的index顺序,这里就填写zookeeper的myid编号即可;内部填写这个节点的域名以及对外开放的端口-->
<node index="1">
<host>doit01</host>
<port>2181</port>
</node>
<node index="2">
<host>doit02</host>
<port>2181</port>
</node>
<node index="3">
<host>doit03</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 当前clickhouse节点的名字,一般填写这个节点的域名即可-->
<macros>
<replica>doit01</replica>
</macros>
<!-- 当前clickhouse的对外网络开发权限,注意如果生产环境下,这里需要限制为指定的ip地址或者多个ip地址;类似于java EE开发中的堡垒机机制,这样可以确保数据访问权限。-->
<!-- 这里填写的是对所有ip地址开放,学习研究时可以这么填写-->
<networks>
<ip>::/0</ip>
</networks>
<!-- 这里是压缩参数,在数据存储领域,硬件条件允许时,数据存储和传输时,一般都会对数据进行压缩,包括mysql、hdfs、这里的clickhouse;还有数据传输如http中的gzip压缩等等。-->
<!--注意数据压缩一般都是可选,包括选择什么样的压缩方式和格式,有的压缩和解压缩速度快但是压缩比不高,有的压缩比高但压缩和解压缩速度满,有的不支持对压缩后数据切分,有的支持,不一而足-->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
- 修改每台机器 /etc/clikhouse-server/config.xml 中的内容
<!-- 这里是修改clikhouse-server的ip地址,这个是设置为任何ip地址都可以访问-->
<!-- 实际企业开发是不允许这么设置的,除非是内网中部署的节点,一般都需要严格限制可访问ip地址,类似Java EE中后台连接服务器需要通过堡垒机,这样安全性较高-->
<listen_host>::</listen_host>
- 重启集群每个节点服务器,让配置生效
- 启动zookeeper集群,可以每台机器单独启动,也可以使用批量启动脚本执行zookeeper集群的启动
# 去每台节点的zookeeper安装目录下,具体目录如下,cd /opt/apps/zookeeper-3.4.6/bin/,执行以下shell命令,启动zookeeper服务
./zkServer.sh start
# 启动后,输入jps,如果看到如下进程启动QuorumPeerMain,说明启动成功了
jps

- 重启结束后,连接每台节点服务器,输入以下shell命令,启动集群中的clickhouse客户端
# 这里是最简单的启动客户端,没有指定账户和密码,端口等信息,只是加了支持多行sql语句的参数
clickhouse-client -m
至此,集群安装完毕。
- 验证一下是否安装成功
- 在每台CH的客户端中创建一个普通的表
-- 这里使用最简单的Log引擎做功能验证,表是建立在default数据库下
create table tb_log(id UInt16, name String) ENGINE=TinyLog;
- 创建一个分布式表
-- 这里是在tb_log基础上加分布式引擎来做分布式数据存储,节点间高可用通过zookeeper完成,这一点和hdfs中namenode的checkpoint以及高可用机制是一样的。
create table tb_distribute(id UInt16, name String) ENGINE=Distributed(doit, default, tb_log, id);
- 在其中某一台节点上的clickhouse客户端上执行插入语句
insert into tb_distribute values (12, 'haha');
insert into tb_distribute values (13, 'xixi');
insert into tb_distribute values (14, 'yiyi');
insert into tb_distribute values (15, 'tt');
- 在不同节点上查看数据,可以看到数据被放到不同节点服务器上去。说明数据被分布式存放了。
select * from tb_log;
- 查看这些分布式数据库文件存储在哪里
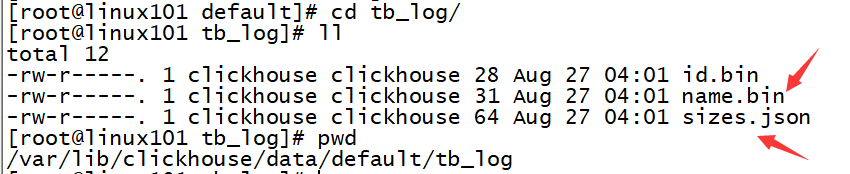
》因为这里验证时,数据库表是建立default数据库下,所以我们去这里查看/var/lib/clickhouse/data/default。/var/lib/clickhouse就是安装目录,其下的data文件夹就是存放数据库文件的目录,default文件夹就代表者detaul数据库
》可以看到default下目前有2个文件夹

》tb_log目录下就是存放数据库具体文件的目录,路径如下 /var/lib/clickhouse/data/default/tb_log,
3.3官方文档使用导览
- 官网地址https://clickhouse.tech/
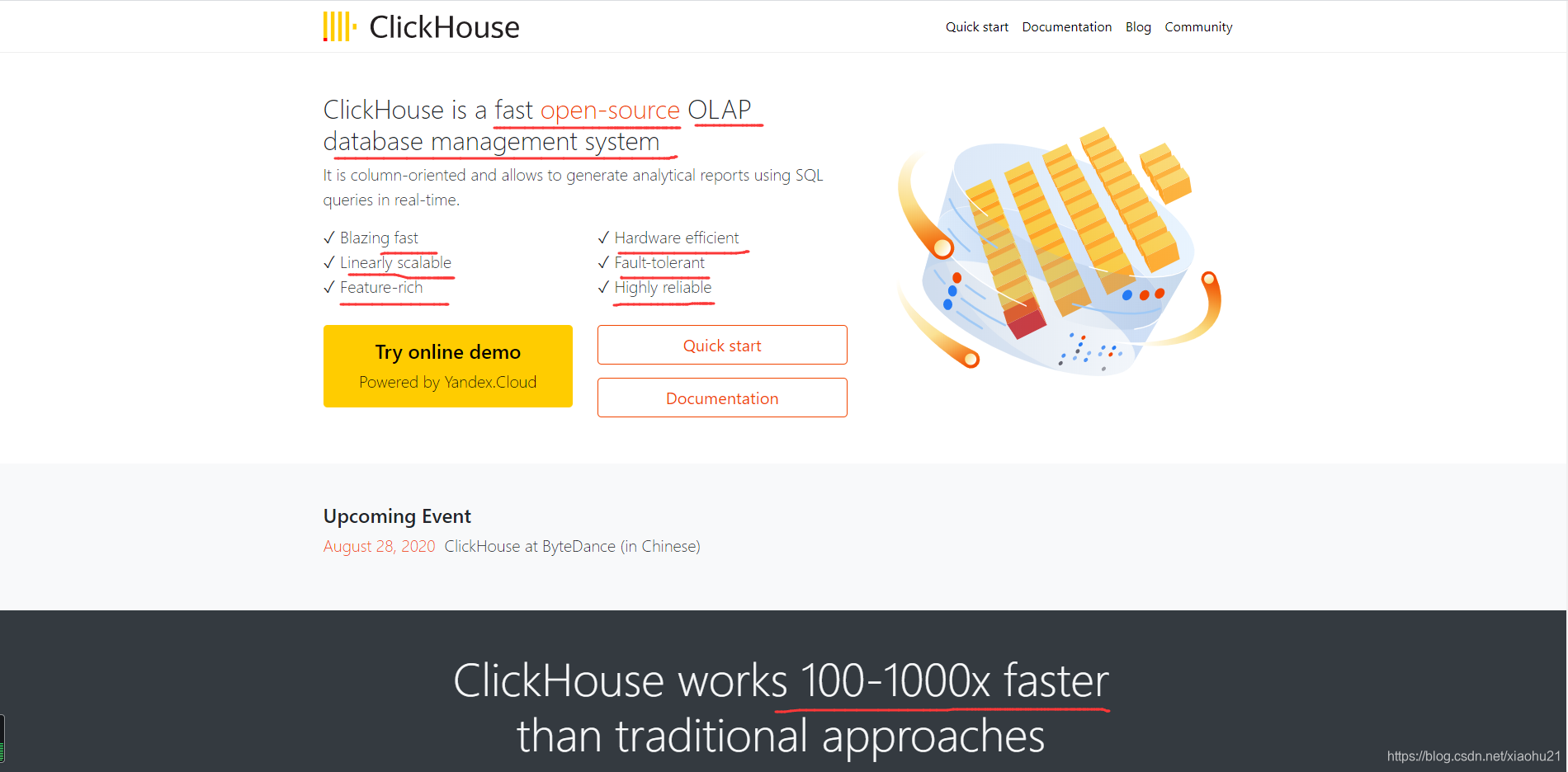
- 这里其实就是clickhouse的主页,把clickhouse是什么,优点都标注出来了。文档、社区等都在对应二级按钮下,点击进入即可。
- 看到OLAP、看到DBMS心里应该有一个预先的猜测。OLAP下应用,则需要满足快、准确、数据读取远多于写、海量数据、最好节点可扩展等等关键点。DBMS,数据和数据结构、数据库引擎(可指定和替换),SQL
- quick start,快速开始
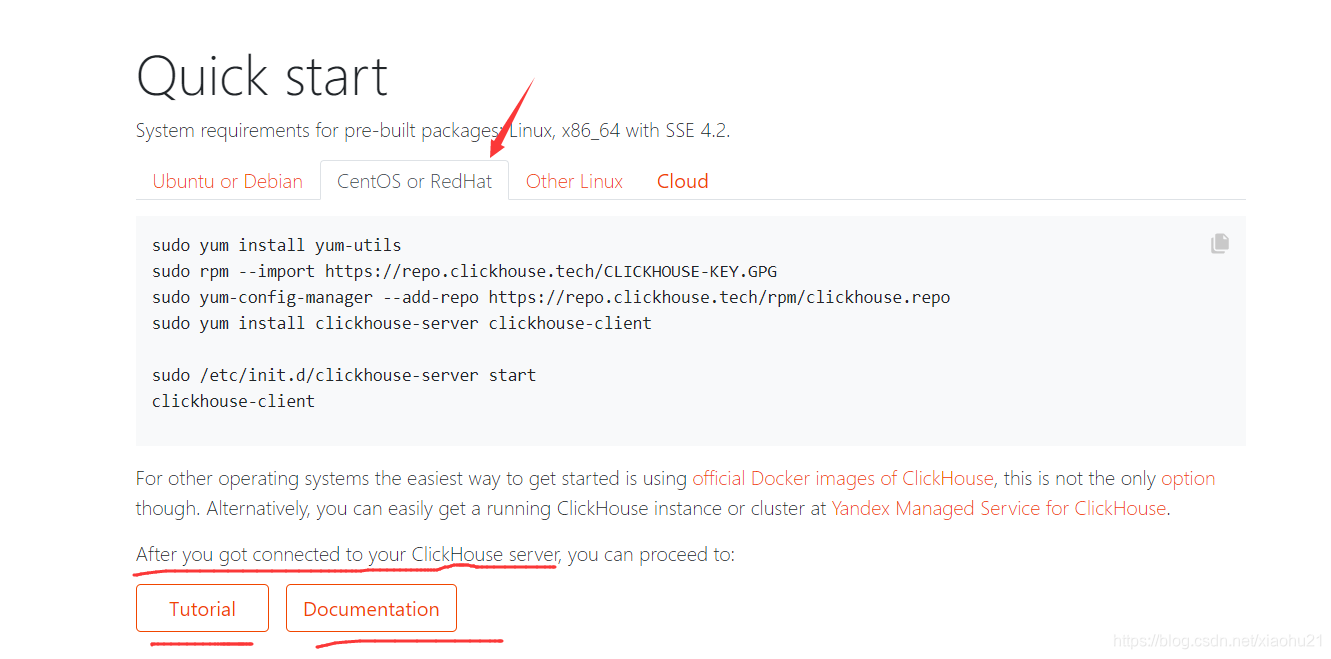
- 教程tutorial和文档documentation
- 都会进入文档页面
- 注意文档需要选择软件版本,后续使用其他软件的文档时,也一定一定注意软件版本。这一点其实在使用Java的文档时应该也有体会。JDK1.6、1.8等等还是有所差异的。
- 版本选择:
-文档页面和连接 https://clickhouse.tech/docs/en/
- SQL相关文档
- 这里有数据类型、sql函数、DDL、DML等等SQL相关的文档信息。资料很多,选择重要知识点学习,其他知道在哪里,用到时再去查找文档。
- 如果对源码感兴趣,这里也是有源码下载和阅读入口的
可以看到,官方这里只有C++接入入口,不过不需要担心,现代化的语言基本都可以调用C++接口,java的JNI、python、swift等等。Java还有更便捷方式,JDBC,这里可以看https://github.com/ClickHouse/clickhouse-jdbc,直接像java操作mysql一样,直接通过jdbc连接,然后继进行增删改查操作。
4. 其他安装场景
- https://clickhouse.tech/docs/en/getting-started/install/
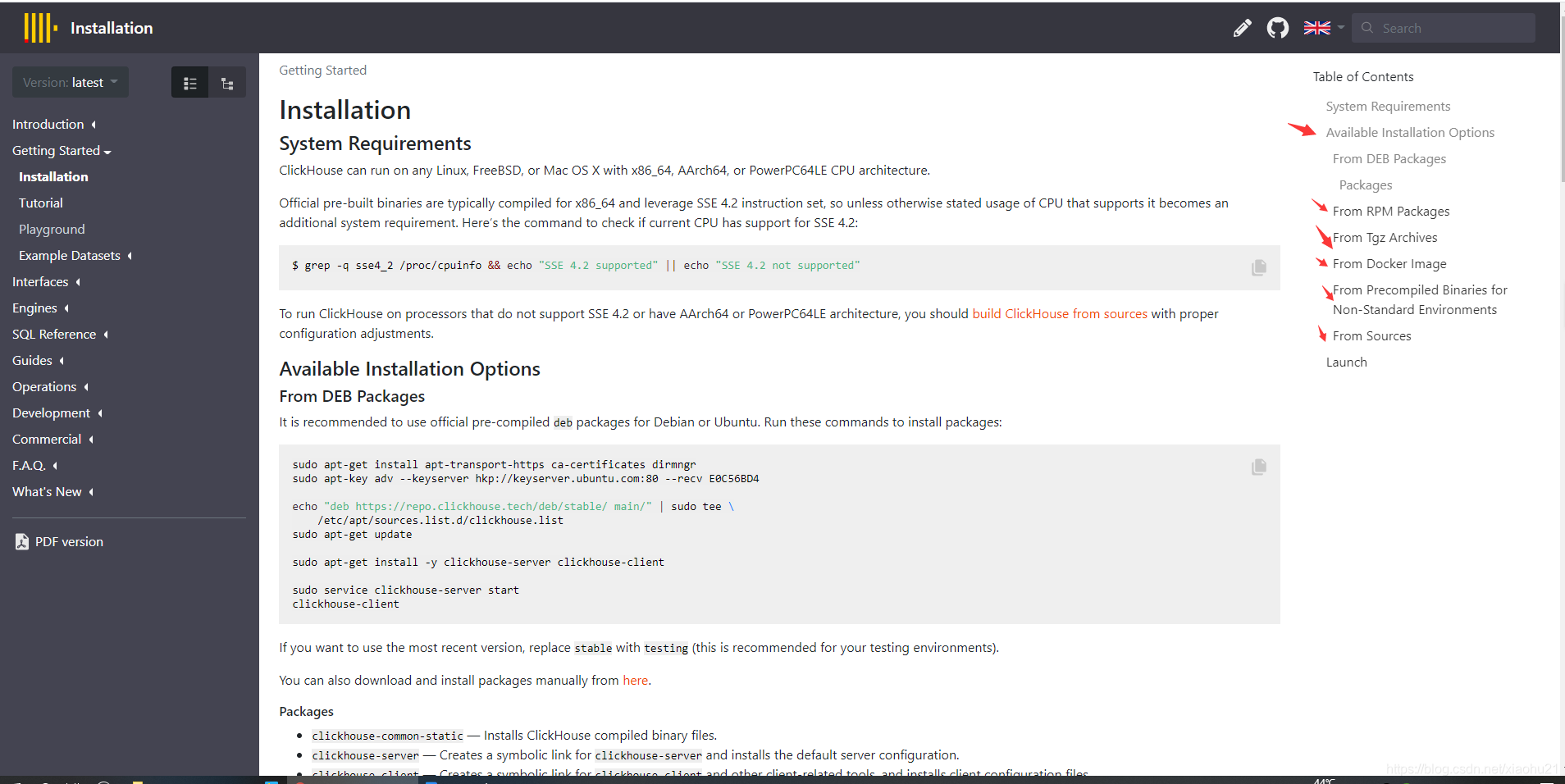
4.1 系统要求

4.2 可用安装方式
- Debian or Ubuntu
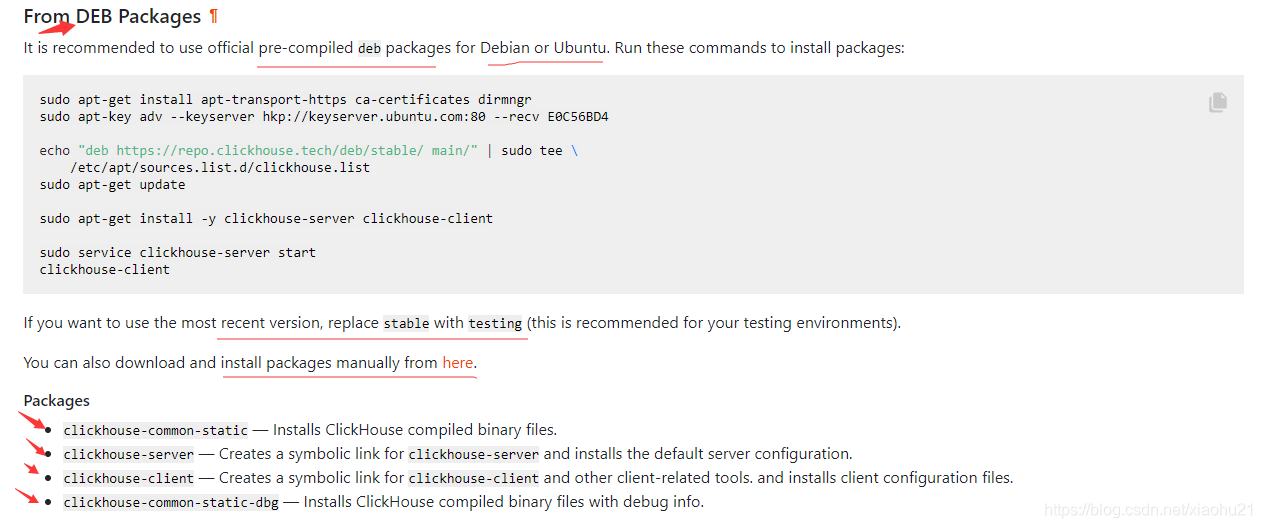
- CentOS, RedHat, and all other rpm-based Linux distributions

- all Linux distributions, where installation of deb or rpm packages is not possible.

- Docker Image

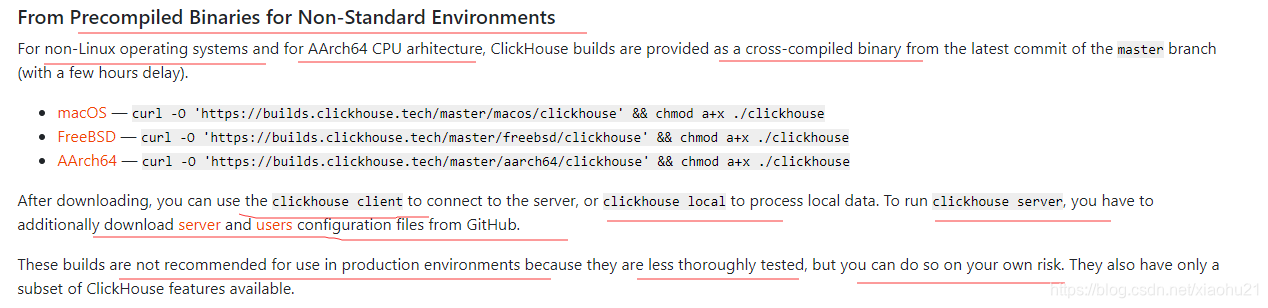
- 非标准系统
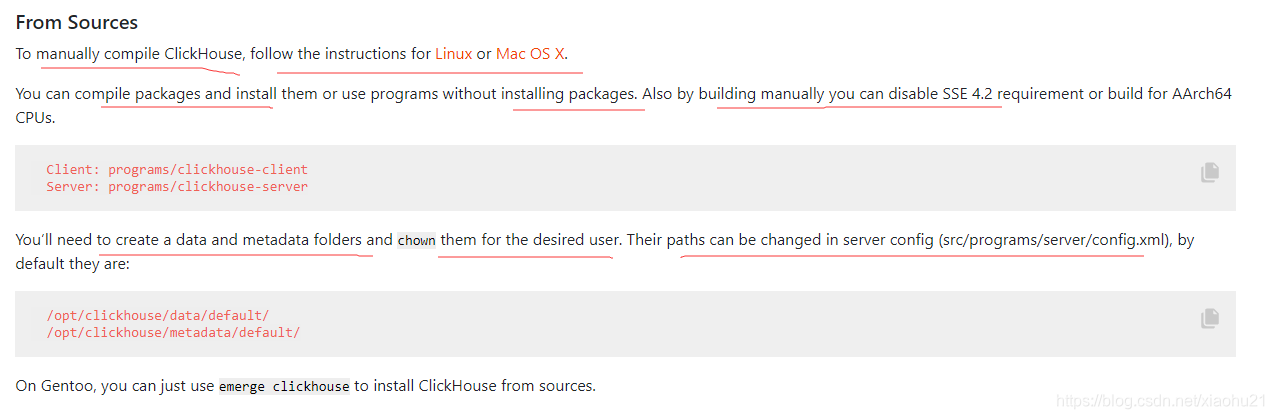
- 源码编译
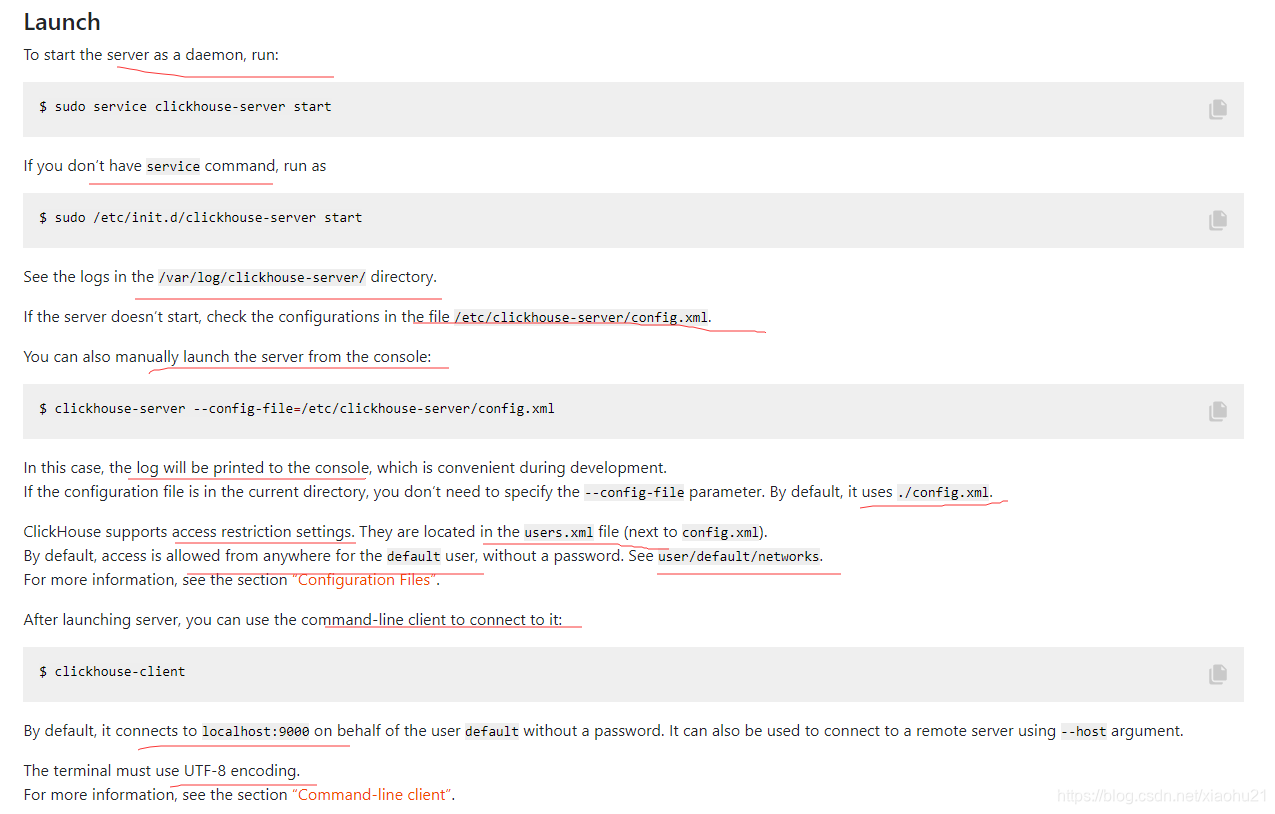
- 登录尝试


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









