前后端模型简图
最新推荐文章于 2025-03-27 14:42:21 发布





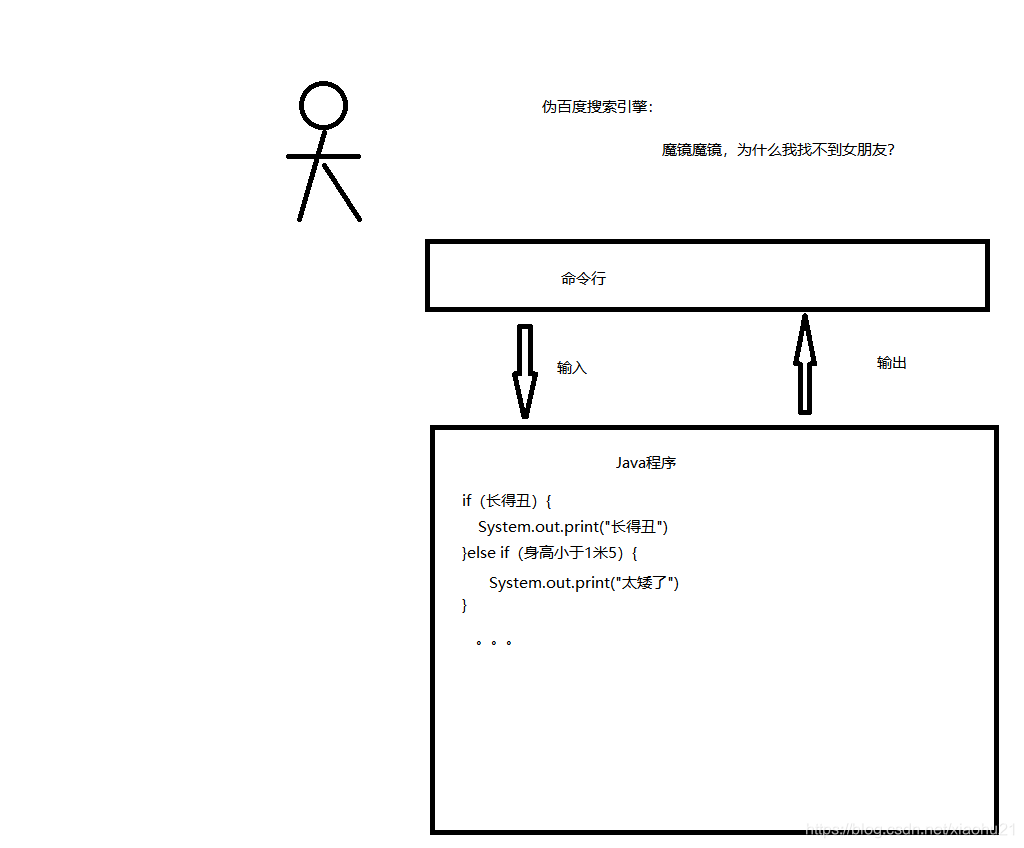
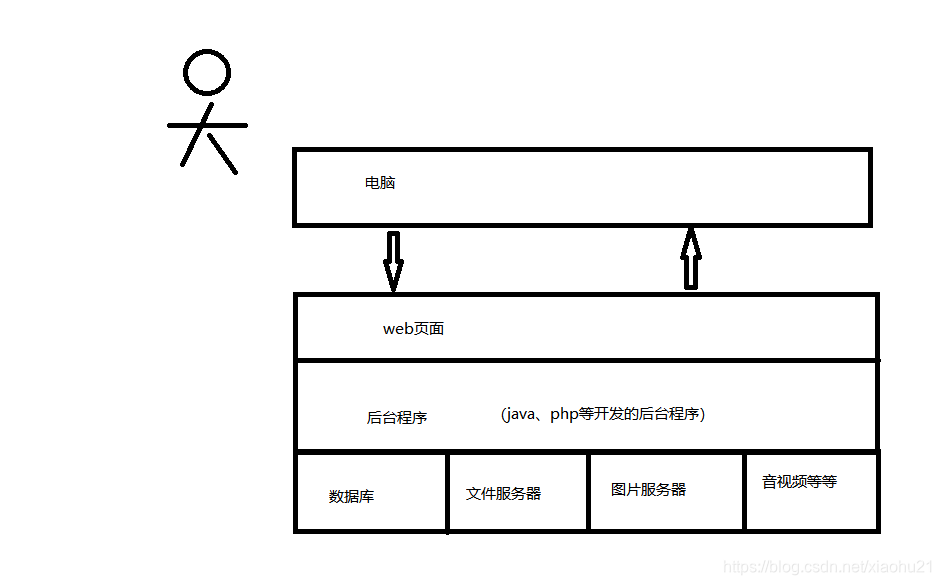
 本文从命令行时代到前后端分离,再到后台微服务化、大前端时代,分析了前后端模型的演变过程,强调技术如何随着业务需求发展而进步。文章指出,技术的演进主要是为了应对用户数量增长和业务复杂化带来的挑战,如Hadoop和Spark的出现,都是为了解决大数据处理问题。作者对能见证这些技术进步感到荣幸,并期待更多地参与到互联网发展中。
本文从命令行时代到前后端分离,再到后台微服务化、大前端时代,分析了前后端模型的演变过程,强调技术如何随着业务需求发展而进步。文章指出,技术的演进主要是为了应对用户数量增长和业务复杂化带来的挑战,如Hadoop和Spark的出现,都是为了解决大数据处理问题。作者对能见证这些技术进步感到荣幸,并期待更多地参与到互联网发展中。
本文从命令行时代到前后端分离,再到后台微服务化、大前端时代,分析了前后端模型的演变过程,强调技术如何随着业务需求发展而进步。文章指出,技术的演进主要是为了应对用户数量增长和业务复杂化带来的挑战,如Hadoop和Spark的出现,都是为了解决大数据处理问题。作者对能见证这些技术进步感到荣幸,并期待更多地参与到互联网发展中。
本文从命令行时代到前后端分离,再到后台微服务化、大前端时代,分析了前后端模型的演变过程,强调技术如何随着业务需求发展而进步。文章指出,技术的演进主要是为了应对用户数量增长和业务复杂化带来的挑战,如Hadoop和Spark的出现,都是为了解决大数据处理问题。作者对能见证这些技术进步感到荣幸,并期待更多地参与到互联网发展中。
 1239
688
1239
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























