




 本文介绍了YOLOv5,一个先进的目标检测模型,通过改进的CSPDarknet架构提高了准确性和速度。文章详细阐述了YOLOv5与前作的对比、架构、性能优化、代码实现以及在多个领域的应用,同时展望了模型的未来发展方向。
本文介绍了YOLOv5,一个先进的目标检测模型,通过改进的CSPDarknet架构提高了准确性和速度。文章详细阐述了YOLOv5与前作的对比、架构、性能优化、代码实现以及在多个领域的应用,同时展望了模型的未来发展方向。
YOLOv5简介
YOLOv5(You Only Look Once, Version 5)是一种先进的目标检测模型,是YOLO系列的最新版本,由Ultralytics公司开发。该模型利用深度学习技术,能够在图像或视频中实时准确地检测出多个对象的位置及其类别,是计算机视觉领域的重要里程碑之一。下面将详细介绍YOLOv5的架构、性能、应用和未来发展方向。
一、与之前版本的对比
相较于YOLOv4和其他先前版本,YOLOv5在多个方面进行了改进和优化。首先,YOLOv5提供了更高的检测准确性,这得益于其新的模型架构以及对数据集和训练过程的细致调优。其次,YOLOv5在处理速度上也有所提升,这意味着它可以更快地对图像或视频进行检测和识别,使其在实时应用中更具竞争力。此外,YOLOv5还引入了一些新的特性,如自动批处理大小调整和更高效的图像处理流程,进一步提升了模型的性能和灵活性。
二、YOLOv5的架构
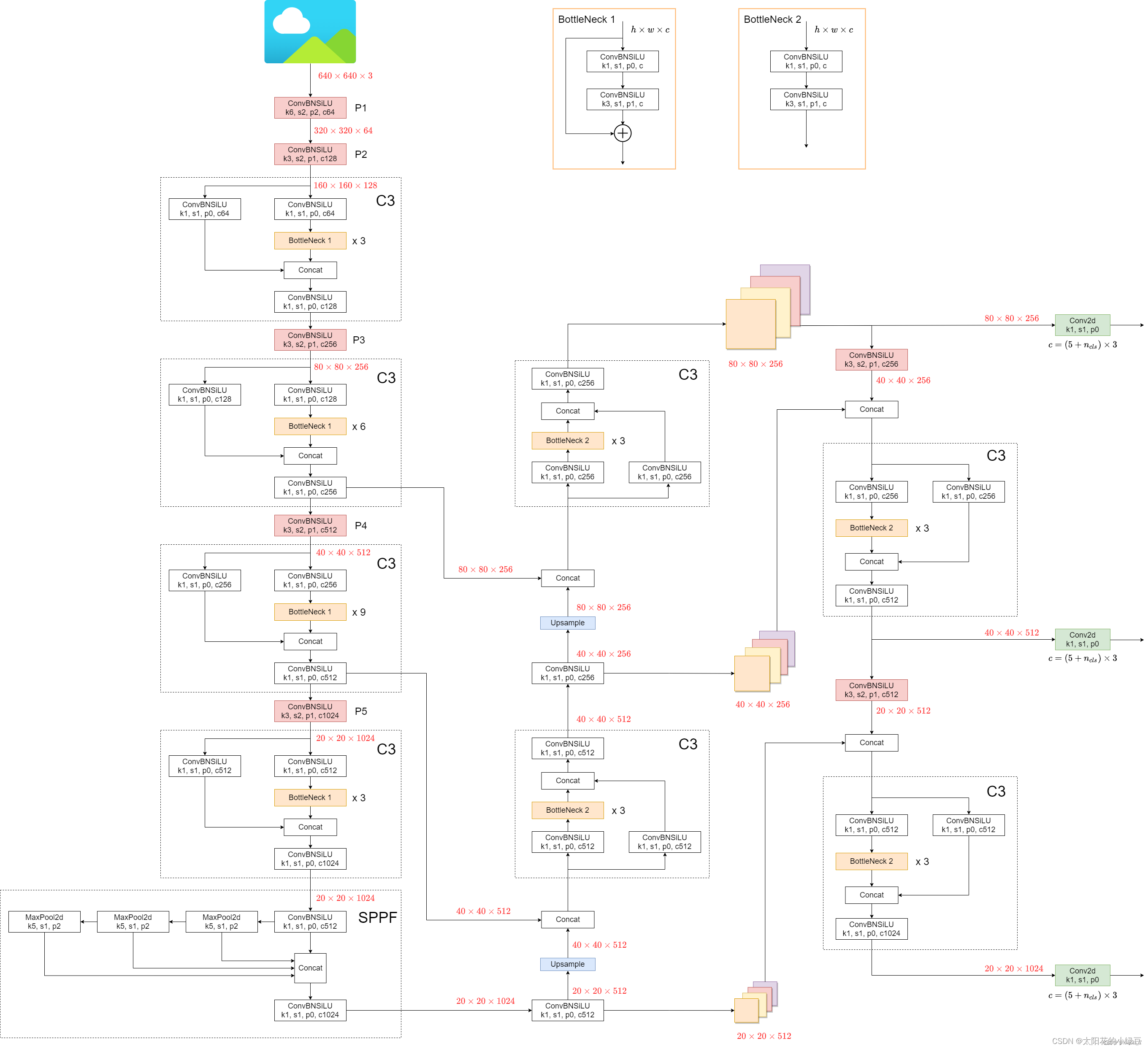
YOLOv5的架构基于深度卷积神经网络(CNN),采用了一种称为骨干网络(Backbone)的模块化设计。骨干网络通常由多个卷积层和池化层组成,用于从原始图像中提取特征。在YOLOv5中,采用了一种称为CSPDarknet的改进的骨干网络,它结合了Cross-Stage Partial连接(CSP)和Darknet53的优点,具有更好的特征提取能力和更快的训练速度。
除了骨干网络外,YOLOv5还包含了一系列用于检测和识别对象的头部(Head)模块。这些头部模块负责将从骨干网络中提取的特征映射转换为对象的边界框及其类别概率。YOLOv5采用了一种简单而有效的头部设计,包括多个卷积层和线性激活函数,以实现高效的对象检测。
YOLOv5网络整体框架图(来自大佬的:博客)
SPPF模块
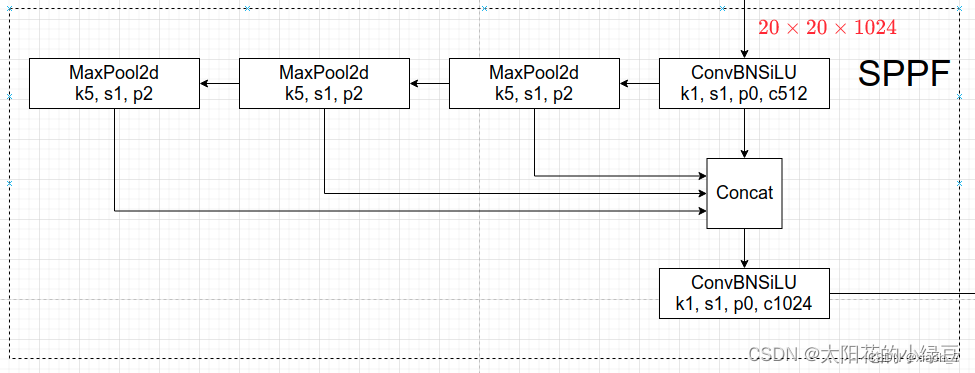
SPPF模块代码实现:
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









