




 本文揭示了Python中小整数对象池导致的地址一致性和大整数对象池的区别,特别对比了交互式模式与源文件环境下内存分配的不同。
本文揭示了Python中小整数对象池导致的地址一致性和大整数对象池的区别,特别对比了交互式模式与源文件环境下内存分配的不同。
在交互式(终端)模式下,比较俩个数的地址:
age = 20 与 age1 = 20 地址是一致的
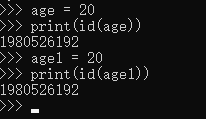
但是money = 20000 与 money1 = 20000的地址却不一致,这是什么情况呢?
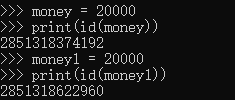
原来,由于整数在程序中频繁被使用,所以python开辟了一块内存,存储【-5,256】之间的小整数,这些内存不会被垃圾回收,所以在交互式模式下,比较在此区间的数据的地址是一样的,这个空间也叫做小整数对象池。
那些不在这个范围内的数据,就会被重建并在程序结束后销毁,也就是大整数对象池。
但是在源文件中(pycharm,sublime),由于代码是一起交由解释器处理的。所以内存地址是一起开辟和销毁的,就会产生和交互式下不一样的结果。
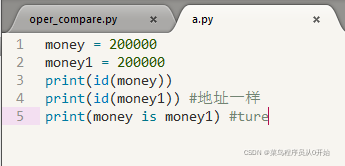
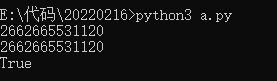

















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









