




What is CarbonData?
Apache CarbonData is an indexed columnar data format for fast analytics on big data platform, e.g. Apache Hadoop, Apache Spark, etc.
因为我的spark是2.3.1的版本,而最新版的carbondata1.5.1才支持,但是官网没有编译好的,需要我们自己编译,在编译的时候遇到一些问题,记录一下.
1.下载thrift-0.9.3,http://archive.apache.org/dist/thrift/0.9.3/
然后到thrift下编译安装
./configure
sudo make
sudo make install
2.下载maven:wget http://mirrors.hust.edu.cn/apache/maven/maven-3/3.5.2/binaries/apache-maven-3.5.2-bin.tar.gz
解压:tar -zxvf apache-maven-3.5.2-bin.tar.gz
配置maven环境变量
vi /etc/profile
添加环境变量
export MAVEN_HOME=/var/local/apache-maven-3.5.2
export MAVEN_HOME
export PATH=$PATH:$MAVEN_HOME/bin
编辑之后source /etc/profile命令使改动生效。
测试mvn -v 显示出maven的信息即为安装成功了
3.编译carbondata,因为1.5.1的源码有几个地方有bug我们需要先修改一下
(1).cp -f integration/spark2/src/main/commonTo2.1And2.2/org/apache/spark/sql/execution/strategy/CarbonDataSourceScan.scala integration/spark2/src/main/spark2.3/org/apache/spark/sql/execution/strategy/CarbonDataSourceScan.scala 用第一个文件强制覆盖第二个.
(2). vi integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/bigdecimal.TestBigDecimal.scala,修改这个类的48行,把salary decimal(30,10) 改成 salary decimal(27,10)
(3).vi integration/spark-common/src/main/scala/org/apache/spark/util/CarbonReflectionUtils.scala,修改这个类的297行,把classOf[Seq[String]]改成classOf[Seq[Attribute]],修改301行,用method.invoke(dataSourceObj,mode,query,query.output,physicalPlan)替换掉原来的那个.
(4).执行mvn -DskipTests -Pspark-2.3 -Dspark.version=2.3.1 clean package,可以用 mvn -DskipTests -Pspark-2.3 -Dspark.version=2.3.1 clean package -X进行打印报错的信息.
(5).耐心等待,整个过程需要10分钟左右,然后会出现下图所示即为编译成功:
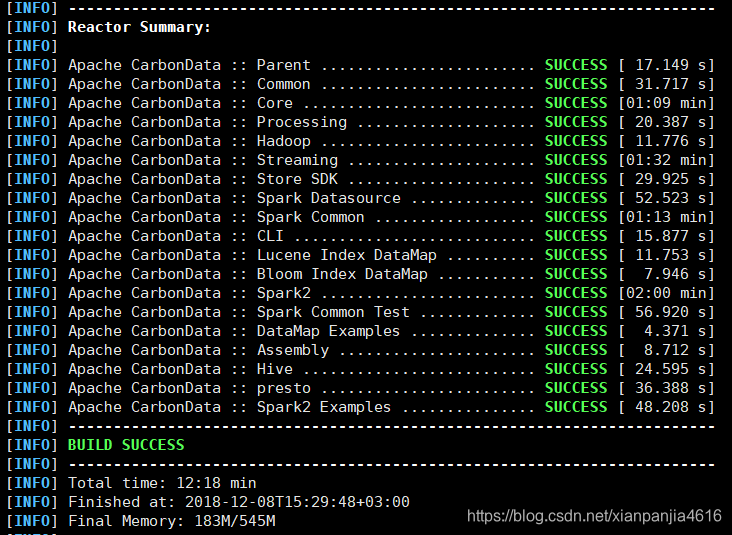
spark on yarn配置carbondata可以看这个
如果有写的不对的地方,欢迎大家指正,如果有什么疑问,可以加QQ群:340297350,谢谢



















 2470
2470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











