




 本文介绍如何使用 Java 驱动程序连接 Cassandra 数据库,包括 Maven 依赖配置、Session 获取、基本操作(增删改查)及高级功能(索引、排序和分页)。同时提供了使用 CQL 语句、Querybuilder 和预编译占位符等多种方式进行数据操作的示例。
本文介绍如何使用 Java 驱动程序连接 Cassandra 数据库,包括 Maven 依赖配置、Session 获取、基本操作(增删改查)及高级功能(索引、排序和分页)。同时提供了使用 CQL 语句、Querybuilder 和预编译占位符等多种方式进行数据操作的示例。
一、驱动下载
老规矩,创建maven工程,让maven来维护我们的jar,maven最重要的pom文件内容如下:

<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.huawei</groupId> <artifactId>cassandra</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>cassandra</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>com.datastax.cassandra</groupId> <artifactId>cassandra-driver-core</artifactId> <version>2.1.10.3</version> </dependency> </dependencies> </project>
二、session获取
我们先来看看官方给的Quick start案例
Cluster cluster = null; try { cluster = Cluster.builder() // (1) .addContactPoint("127.0.0.1") // cassandra服务器ip .withCredentials("admin", "admin") // 若没有启用账号认证,此处可以去掉 .build(); Session session = cluster.connect(); // (2) ResultSet rs = session.execute("select release_version from system.local"); // (3) Row row = rs.one(); System.out.println(row.getString("release_version")); // (4) } finally { if (cluster != null) cluster.close(); // (5) }
我们来看看代码中的(1) ~ (5)分别表示或者代表什么
(1):Cluster对象是驱动程序的主入口点,它保存着真实Cassandra集群的状态(尤其是元数据);Cluster是线程安全的,一个Cassandra集群创建一个Cluster的单例,整个应用用这一个单例即可
(2):Session用来执行查询的,而且它也是线程安全的,同样也应该重复利用
(3):利用execute来发送一个查询到Cassandra,execute返回一个Resultset(结果集),这个结果集就是必要的列的行集合(二维表,行是满足条件的记录,列是我们关注的某些字段)
(4):从row中提取数据
(5):当任务完成后,关闭cluster,关闭cluster的同时将会关闭它创建的全部session;这一步很重要,它会释放潜在的资源(TCP连接、线程池等),在真实的应用中,我们应该在应用关闭(或应用卸载)的时候关闭cluster
如若大家有jdbc开发的经验,就会发现,上述代码似曾相识,上述代码中的session就相当于jdbc中的connection,是整个数据库操作的基础,那么我们将session的获取单独抽出来
 View Code
View Code
拿到session了,那么请随意操作Cassandra吧!
三、cassandra基本操作
1、 创建表
在mycas下创建表student
use mycas; create table student( id int, address text, name text, age int, height int, primary key(id,address,name) ); insert into student(id,address,name,age,height) values(1,'guangdong','lixiao',32,172);
2、 session直接执行cql
和jdbc类似,关键是cql的拼接,下例是插入一条记录,删、改、查和这类似,不一一列举了
// 字符串注意单引号' String cql = "insert into mycas.student(id,address,name,age,height) values(" + student.getId() + ",'" + student.getAddress() + "','" + student.getName() + "'," + student.getAge() + "," + student.getHeight() + ");"; System.out.println(cql); session.execute(cql);
3、 Querybuilder
利用Querybuilder可以减轻cql的拼接,sql语句的拼接由驱动完成
查询一个student:
@Override public Student getStudentByKeys(int id, String address, String name) { Student student = null; ResultSet rs = session.execute( QueryBuilder.select("id", "address", "name", "age", "height") .from("mycas", "student") .where(QueryBuilder.eq("id", id)) .and(QueryBuilder.eq("address", address)) .and(QueryBuilder.eq("name", name))); Iterator<Row> rsIterator = rs.iterator(); if (rsIterator.hasNext()) { Row row = rsIterator.next(); student = new Student(); student.setAddress(row.getString("address")); student.setAge(row.getInt("age")); student.setHeight(row.getInt("height")); student.setId(row.getInt("id")); student.setName(row.getString("name")); } return student; }
保存一个student:
@Override public void saveStudent(Student student) { session.execute( QueryBuilder.insertInto("mycas", "student") .values(new String[]{"id", "address", "name", "age", "height"}, new Object[]{student.getId(), student.getAddress(), student.getName(), student.getAge(), student.getHeight()})); }
修改一个student:
@Override public void updateStudent(Student student) { session.execute( QueryBuilder.update("mycas", "student") .with(QueryBuilder.set("age", student.getAge())) .and(QueryBuilder.set("height", student.getHeight())) .where(QueryBuilder.eq("id", student.getId())) .and(QueryBuilder.eq("address", student.getAddress())) .and(QueryBuilder.eq("name", student.getName()))); }
删除一个student:
@Override public void removeStudent(int id, String address, String name) { session.execute(QueryBuilder.delete() .from("mycas", "student") .where(QueryBuilder.eq("id", id)) .and(QueryBuilder.eq("address", address)) .and(QueryBuilder.eq("name", name))); }
注意:驱动版本不同,Querybuilder的用法有些许不同,有些版本的某些方法变成非静态的了!
4、 类似jdbc那样使用预编译占位符
http://docs.datastax.com/en/developer/java-driver/3.0/manual/statements/prepared/
预编译的原理是怎样的了,上面的链接是驱动官方的解释,我来谈谈我的理解
当我们预编译statement的时候,Cassandra会解析query语句,缓存解析的结果并返回一个唯一的标志(PreparedStatement对象保持着这个标志的内部引用,就相当于通过标志可以获取到query语句预编译后的内容):
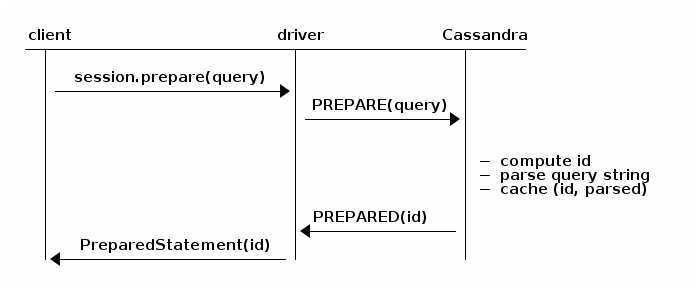
当你绑定并且执行预编译statement的时候,驱动只会发送这个标志,那么Cassandra就会跳过解析query语句的过程:
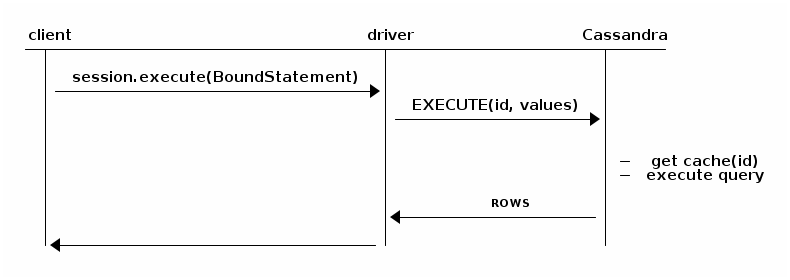
所以,我们应该保证query语句只应该被预编译一次,缓存PreparedStatement 到我们的应用中(PreparedStatement 是线程安全的);如果我们对同一个query语句预编译了多次,那么驱动会打印警告日志;如果一个query语句只执行一次,那么预编译不会提供性能上的提高,反而会降低性能,因为它是两个来回(结合上面两张图),那么此时可以考虑用 simple statement 来代替
和jdbc的预编译非常类似,我们来看看实际代码
静态cql
private static final String GET_STUDENT = "select id,address,name,age,height from mycas.student where id=? and address=? and name=?;"; private static final String SAVE_STUDENT = "insert into mycas.student(id,address,name,age,height) values(?,?,?,?,?);"; private static final String UPDATE_STUDENT = "update mycas.student set age=?, height=? where id=? and address=? and name=?;"; private static final String REMOVE_STUDENT = "delete from mycas.student where id=? and address=? and name=?;";
查询一个student
Student student = null; PreparedStatement prepareStatement = session.prepare(GET_STUDENT); BoundStatement bindStatement = new BoundStatement(prepareStatement).bind(id, address, name); ResultSet rs = session.execute(bindStatement); Iterator<Row> rsIterator = rs.iterator(); if (rsIterator.hasNext()) { Row row = rsIterator.next(); student = new Student(); student.setAddress(row.getString("address")); student.setAge(row.getInt("age")); student.setHeight(row.getInt("height")); student.setId(row.getInt("id")); student.setName(row.getString("name")); } return student;
保存一个student
PreparedStatement prepareStatement = session.prepare(SAVE_STUDENT); BoundStatement bindStatement = new BoundStatement(prepareStatement) .bind(student.getId(), student.getAddress(), student.getName(), student.getAge(), student.getHeight()); session.execute(bindStatement);
修改一个student
PreparedStatement prepareStatement = session.prepare(UPDATE_STUDENT); BoundStatement bindStatement = new BoundStatement(prepareStatement) .bind(student.getAge(), student.getHeight(), student.getId(), student.getAddress(), student.getName()); session.execute(bindStatement);
删除一个student
PreparedStatement prepareStatement = session.prepare(REMOVE_STUDENT); BoundStatement bindStatement = new BoundStatement(prepareStatement) .bind(id, address, name); session.execute(bindStatement);-----------------------------------------------------------------------------------------------------------------------------------------------------
cassandra的高级操作:索引、排序和分页;处于性能的考虑,cassandra对这些支持都比较简单,所以我们不能希望cassandra完全适用于我们的逻辑,而是应该将我们的逻辑设计的更适合于cassandra
一、索引和排序
Cassandra对查询的支持很弱,只支持主键列及索引列的查询,而且主键列还有各种限制,不过查询弱归弱,但它还是支持索引和排序的。
cassandra的查询具有以下约束:
第一主键 只能用=号查询
第二主键 支持= > < >= <=
索引列 只支持=号
1、索引查询
Cassandra支持创建二级索引,可以创建在除了第一主键(分区键:partition key)之外所有的列上;不同的cassandra版本对集合列的索引的支持也是不同的,有的支持有的不支持,大家可以去看下官方文档的Changes,2.1版本开始,可以建立集合索引
建一张teacher表:
create table teacher( id int, address text, name text, age int, height int, primary key(id,address,name) );向teacher表中插入数据:
insert into teacher(id,address,name,age,height) values(1,'guangdong','lixiao',32,172); insert into teacher(id,address,name,age,height) values(1,'guangxi','linzexu',68,178); insert into teacher(id,address,name,age,height) values(1,'guangxi','lihao',25,178); insert into teacher(id,address,name,age,height) values(2,'guangxi','lixiaolong',32,172); insert into teacher(id,address,name,age,height) values(2,'guangdong','lixiao',32,172); insert into teacher(id,address,name,age,height) values(2,'guangxi','linzexu',68,178); insert into teacher(id,address,name,age,height) values(2,'guangxi','lihao',25,178); insert into teacher(id,address,name,age,height) values(2,'guangxi','nnd',32,172);建索引:
CREATE INDEX idx_teacher_age on teacher(age);索引列只可以用=号查询,所以
select * from teacher where age=32; //可以 select * from teacher where age>32; //不行如果查询条件里,有一个是根据索引查询,那其它非索引非主键字段,可以通过加一个ALLOW FILTERING来过滤实现
select * from teacher where age=32 and height>30 ALLOW FILTERING;先根据age=32过滤出结果集,然后再对结果集进行height>30过滤
2、排序
建一张tt表:
create table tt( id int, address text, name text, age int, height int, primary key(id,address,name) )WITH CLUSTERING ORDER BY(address DESC, name ASC);向tt表中插入数据:
insert into tt(id,address,name,age,height) values(1,'guangdong','lixiao',32,172); insert into tt(id,address,name,age,height) values(1,'guangxi','linzexu',68,178); insert into tt(id,address,name,age,height) values(1,'guangxi','lihao',25,178); insert into tt(id,address,name,age,height) values(2,'guangxi','lixiaolong',32,172); insert into tt(id,address,name,age,height) values(2,'guangdong','lixiao',32,172); insert into tt(id,address,name,age,height) values(2,'guangxi','linzexu',68,178); insert into tt(id,address,name,age,height) values(2,'guangxi','lihao',25,178); insert into tt(id,address,name,age,height) values(2,'guangxi','nnd',32,172);Cassandra支持排序,但也是限制重重
a、 必须有第一主键的=号查询;cassandra的第一主键是决定记录分布在哪台机器上,也就是说cassandra只支持单台机器上的记录排序。
b、 只能根据第二、三、四…主键进行有序的,相同的排序。
有序:order by后面只能是先二、再三、再四…这样的顺序,有四,前面必须有三;有三,前面必须有二,以此类推。
相同的顺序:参与排序的主键要么与建表时指定的顺序一致,要么全部相反,具体会体现在下面的示例中
c、 不能有索引查询
正确示例:
SELECT * FROM teacher WHERE id=1 ORDER BY address ASC; SELECT * FROM teacher WHERE id=1 ORDER BY address ASC, name ASC; SELECT * FROM teacher WHERE id=1 AND address='guangxi' ORDER BY address ASC; SELECT * FROM teacher WHERE id=1 AND address='guangxi' ORDER BY address ASC, name ASC; SELECT * FROM teacher WHERE id=1 ORDER BY address DESC; SELECT * FROM teacher WHERE id=1 ORDER BY address DESC, name DESC; SELECT * FROM teacher WHERE id=1 AND address='guangxi' ORDER BY address DESC; SELECT * FROM teacher WHERE id=1 AND address='guangxi' ORDER BY address DESC, name DESC;SELECT * FROM tt WHERE id=1 ORDER BY address DESC; SELECT * FROM tt WHERE id=1 ORDER BY address DESC, name ASC; SELECT * FROM tt WHERE id=1 AND address='guangxi' ORDER BY address DESC; SELECT * FROM tt WHERE id=1 AND address='guangxi' ORDER BY address DESC, name ASC; SELECT * FROM tt WHERE id=1 ORDER BY address ASC; SELECT * FROM tt WHERE id=1 ORDER BY address ASC, name DESC; SELECT * FROM tt WHERE id=1 AND address='guangxi' ORDER BY address ASC; SELECT * FROM tt WHERE id=1 AND address='guangxi' ORDER BY address ASC, name DESC;错误示例:
SELECT * FROM teacher ORDER BY address DESC; //没有第一主键 不行 SELECT * FROM teacher WHERE id=1 ORDER BY name DESC; //必须以第二主键开始排序 SELECT * FROM teacher WHERE id=1 ORDER BY address DESC, name ASC; //不是与建表时指定的排序一致或者完全相反 (默认是address ASC, name ASC) SELECT * FROM teacher WHERE age=1 ORDER BY address DESC; //不能有索引 SELECT * FROM tt WHERE id=1 ORDER BY address DESC, name DESC; //不是与建表时指定的排序一致或者完全相反 (建表时指定了address DESC, name ASC)其实cassandra的任何查询,最后的结果都是有序的,默认与建表时指定的排序规则一致(例如teacher表是address ASC,name ASC,而tt表则是address DESC,name ASC),因为它内部就是这样存储的。所以你对teacher表使用address DESC, name ASC 或者address ASC,name DESC排序,对tt表使用address DESC, name DESC 或者address ASC,name ASC排序,cassandra都是比较为难的。
当然这个默认存储排序方式,是可以在建表的时候指定的,就想tt表那样。
二、分页查询
一说分页,我很容易就想到了mysql中的limit,恰巧cassandra也是用它来实现分页的,但是cassandra的limit没有mysql的那么强大,它只能限制查询结果的条数,而不能指定从哪里开始,那么问题就来了:cassandra到底要怎么实现分页了?
上面我们已经分析了,要实现分页还差一个条件:起始点;cassandra中通过token函数来确定起始点,具体这个token函数是干嘛的,大家自行去补脑。接下来我直接看例子,看完例子,相信大家会对token有一定的认知了。
先看下teacher表中的全部数据:
一共8条数据,那么我们就按一页2条记录(pageSize=2)来查出全部数据
第一次查询:
起始查询比较好理解:select * from teacher limit 2;结果如下:
此时,需要将上面查询得到的结果的最后一条记录的主键id,address,name的值记录1,guagnxi,lihao记录下来,下次查询需要用到
第二次查询:
select * from teacher where token(id)=token(1) and (address,name)>('guangxi','lihao') limit 2 ALLOW FILTERING; 结果如下:
只查询出了1条记录,不够2条,继续查询,这时语句应该这么写:select * from teacher where token(id)>token(1) limit 1;结果如下:
将2,guangdong,lixiao记录下来,供下次查询用
第三次查询:
和第二次查询一样,先查询token(id)相等(where token(id)=token(1)),直到出现查询的记录数小于pageSize,再查询token(id)大的(token(id)>token(1))
总结下:
1、第一次查询,得到的记录数若小于pageSize,那么就说明后面没数据,若等于pageSize,那就不知道是否还有数据,则需要进行第二次查询。
2、第二次查询,先从token(id)=开始查,若在token(id)=的查询中出现记录数(searchedCounts)小于pageSize,则转向token(id)>的开始查,若token(id)>的查询记录数小于(pageSize – searchedCounts),那么就说明没有数据了,若token(id)>的查询记录数等于(pageSize – searchedCounts),那么重复第二次查询。
综上所述,知道后面没有数据的点只有两个,1、第一次查询的时候;2、token(id)>的时候,其他时候都不能断定后面没有数据
cassandra 的分页查询,主要是通过查询结果的默认的排列顺序来实现的,本文的例子是没有查询条件的情况,有查询条件的情况,也是一样的。你只要知道了cassandra的默认查询结果的排序规则,就知道如何具体的分页查询了,默认排序在建表的时候是可以指定的,就想tt表那样,对tt的分页查询我就不演示了,希望大家自己去实现tt表的分页查询,里面有很多有趣的东西哦! tt表的默认排序规则与teacher表是不同的,那么tt表的分页与teacher表是有区别的!






















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









