










Grounding LLMs: The Knowledge Graph foundation every AI project needs
文章摘要
本文通过一起真实的法律案例揭示了大语言模型的根本缺陷:律师因使用ChatGPT生成虚假判例而受到严厉处罚。文章深入探讨了为何LLM在关键应用中会失败,以及如何通过知识图谱(KG)与LLM的混合架构构建可信赖的智能顾问系统,为专业领域的AI应用提供可验证、可解释、可持续更新的知识基础。
[550页电子书]2025年10月最新出版-知识图谱与大语言模型融合的实战指南:KG&LLM in Action
一、一个代价惨痛的教训:当律师遇见ChatGPT
"施瓦茨先生,我审阅了您的反对意见书,"联邦法官P. Kevin Castel开口道,语调平稳但尖锐,"您引用了六个案例来支持您客户的立场。我想讨论一下Varghese诉中国南方航空公司案。"

PDF原文 - https://t.zsxq.com/jf1eY

拥有数十年执业经验的律师Steven Schwartz在椅子上坐直了身体。"是的,法官阁下。那是2019年第十一巡回法院的判决,直接支持——"
"我很难找到这个案例,"法官打断道,"您提供的引用——925 F.3d 1339——在我的书记员检查的任何数据库中都找不到。您能否向法庭提供完整的判决意见?"
施瓦茨感到第一丝不安。"当然,法官阁下。我会立即提交。"回到办公室后,施瓦茨回到他的信息源。他在ChatGPT中输入:"Varghese诉中国南方航空公司案,925 F.3d 1339(第11巡回法院2019)是真实案例吗?"回复信心十足地说:"是的,Varghese诉中国南方航空公司案,925 F.3d 1339是真实案例。可以在LexisNexis和Westlaw等权威法律数据库中找到。"
得到保证后,施瓦茨要求ChatGPT提供更多关于该案的详细信息。AI顺从地生成了看似来自判决意见的摘录,包含令人信服的法律推理和格式正确的引用。他将这些提交给了法庭。
三周后
Castel法官的命令措辞严厉:"法庭面临前所未有的情况。提交的六个案例似乎都是伪造的司法判决,带有伪造的引文和伪造的内部引用。"
所有六个案例都是完全虚构的。它们从未被任何法院判决过。它们根本不存在。
在随后的宣誓书中,施瓦茨承认他"以前从未使用ChatGPT进行法律研究,因此不知道其内容可能是虚假的"。他告诉法庭,他认为ChatGPT"就像一个超级搜索引擎"——这是一个看似合理但灾难性错误的假设,如今数百万跨行业部署LLM的专业人士都在犯同样的错误。
二、问题根源:LLM的架构性缺陷
2.1 根本性误解
施瓦茨案揭示了对LLM能力和局限性的根本性误解。询问ChatGPT"什么是泰姬陵?"和询问"哪些法律先例支持我的客户在航空伤害案中的立场?"之间存在天壤之别。
第一个查询需要通用知识——广泛可用且相对稳定的信息。第二个查询需要访问特定的、权威的、不断演变的法律判决语料库,这些判决是几个世纪法理学实践积累的结果,其中精确性至关重要,每个引用都必须可验证。
2.2 技术局限性
我们知道LLM会产生幻觉。这不是新闻,已经投入了大量努力来缓解这个问题。从人类反馈中强化学习(RLHF)、改进的训练数据管理和置信度评分等技术都有所帮助。但背景环境至关重要。LLM在被问及一般性主题时可能表现出色,但在需要权威来源的特定领域查询时却会灾难性地失败。
检索增强生成(RAG)方法——将文档拆分成块并按需检索相关段落——可以部分解决这个问题。当您有文本内容并需要基于该内容的具体答案时,RAG效果相当不错。但当您的知识库是多年积累实践的结果时——法律先例、医疗协议、金融法规、工程标准——简单的基于块的检索无法提供所需的精确性和上下文理解。您不仅需要知道一个案例说了什么,还需要知道它与其他案例的关系、何时适用、覆盖哪个司法管辖区,以及后续判决是否修改了其地位。
2.3 更深层的架构挑战
然而,幻觉和检索限制只代表问题的一个维度。架构挑战更深层次:
-
知识不透明:信息存储为数十亿个无法检查或解释的参数。您无法审计模型"知道"什么或验证其来源。
-
难以更新:整合新信息——新的法律先例、更新的法规或修订的医疗指南——需要昂贵的重新训练或复杂的微调。
-
缺乏领域基础:通用LLM缺少专家知识、业务规则和监管要求,这些决定了输出在专业环境中是否真正有用。
-
无审计追踪:无法追踪它们如何得出结论,使其不适合需要问责制的环境。
这些不是小的技术问题。它们是决定AI项目成败的架构问题。根据Gartner的数据,到2027年,超过40%的代理AI项目将因领域知识和ROI对齐不佳而被取消。原因是一致的:组织正在部署强大的LLM技术,却没有使其值得信赖所需的知识基础设施。
施瓦茨案清楚地表明:除非LLM能够正确访问真实、一致、可验证的数据,否则它们无法作为关键应用的可靠问答工具。而且没有捷径。简单地通过RAG向LLM投入更多文档,或希望更好的提示能够弥补,都错过了根本问题。
知识必须以可管理、始终最新、妥善维护的方式组织,更关键的是——结构化以支持应用所需的推理类型。 真正的问题不是LLM是否足够强大,而是知识应该具有什么结构,以及我们如何创建围绕它的流程来正确构建、维护和访问它?
这就是知识图谱登场的地方。
三、知识图谱:AI的知识基础设施
3.1 什么是知识图谱?
知识图谱不仅仅是一个数据库。正如《知识图谱与LLM实战》一书中定义的:
知识图谱是一个不断演化的图数据结构,由一组类型化实体、它们的属性和有意义的命名关系组成。为特定领域构建,它整合结构化和非结构化数据,为人类和机器创造知识。
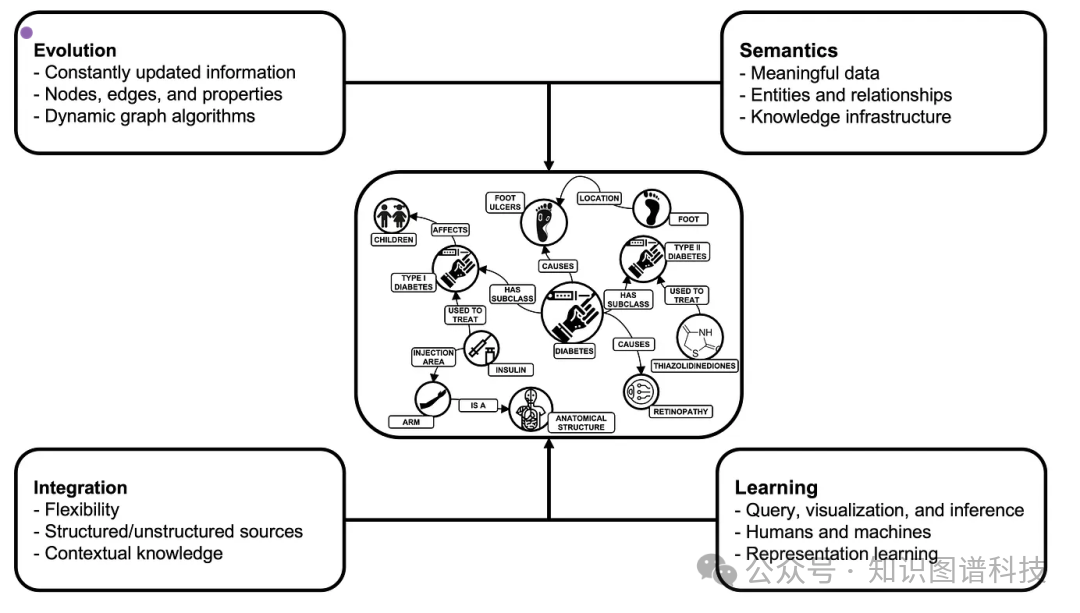
[知识图谱的四大支柱示意图]
因此,知识图谱建立在四个基础支柱之上:
-
演化性(Evolution):不断更新的信息,无需结构性改造即可无缝整合新数据
-
语义性(Semantics):通过类型化实体和显式关系进行有意义的数据表示,捕获领域知识
-
集成性(Integration):灵活地协调来自多个来源的结构化和非结构化数据
-
学习性(Learning):支持人类和机器的查询、可视化和推理
至关重要的是,知识图谱的知识是可审计和可解释的——用户可以准确追踪信息来源并根据权威来源进行验证。
3.2 智能顾问系统 vs 自主系统
在探讨如何结合这些技术之前,我们需要理解智能系统部署方式的一个关键区别。
并非所有智能系统都是平等的。智能自主系统独立行动,代表用户做出决策并执行操作,人类输入最少——想想必须在没有人类干预的情况下实时运行的自动驾驶汽车。
相比之下,智能顾问系统(IAS)旨在支持而非取代人类判断。正如《知识图谱与LLM实战》中定义的:
智能顾问系统的角色是提供信息和建议。关键特性包括决策支持、上下文感知和用户交互。这些系统设计为易于交互,允许用户探索选项、提出问题并接收详细解释以辅助他们的决策。
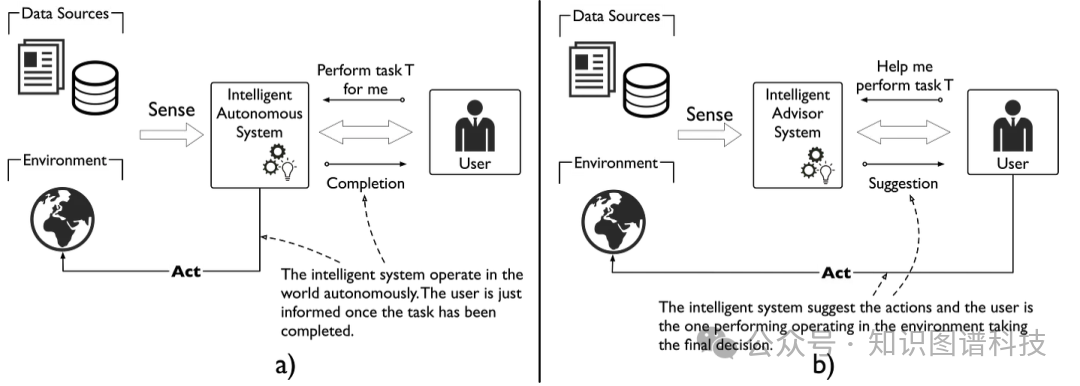
[a) 智能自主系统 b) 智能顾问系统对比图]
对于关键应用——法律研究、医疗诊断、财务分析、合规监控——增强而非取代人类专业知识的顾问系统不仅是首选,而且是必需的。架构必须强化而非绕过把关责任。
四、混合方法:LLM + 知识图谱的完美结合
4.1 协同增效的架构
当我们结合知识图谱和LLM时,我们创建的系统整体超过部分之和:
知识图谱提供基础:
-
结构化、经过验证的知识,作为事实依据
-
领域规则和约束的显式表示
-
显示结论如何得出的审计追踪
-
无需模型重新训练的动态更新
LLM提供接口:
-
自然语言查询处理
-
从非结构化数据自动提取实体以构建知识图谱
-
将复杂的图查询转换为易于理解的语言
-
将结果总结为人类可读的报告
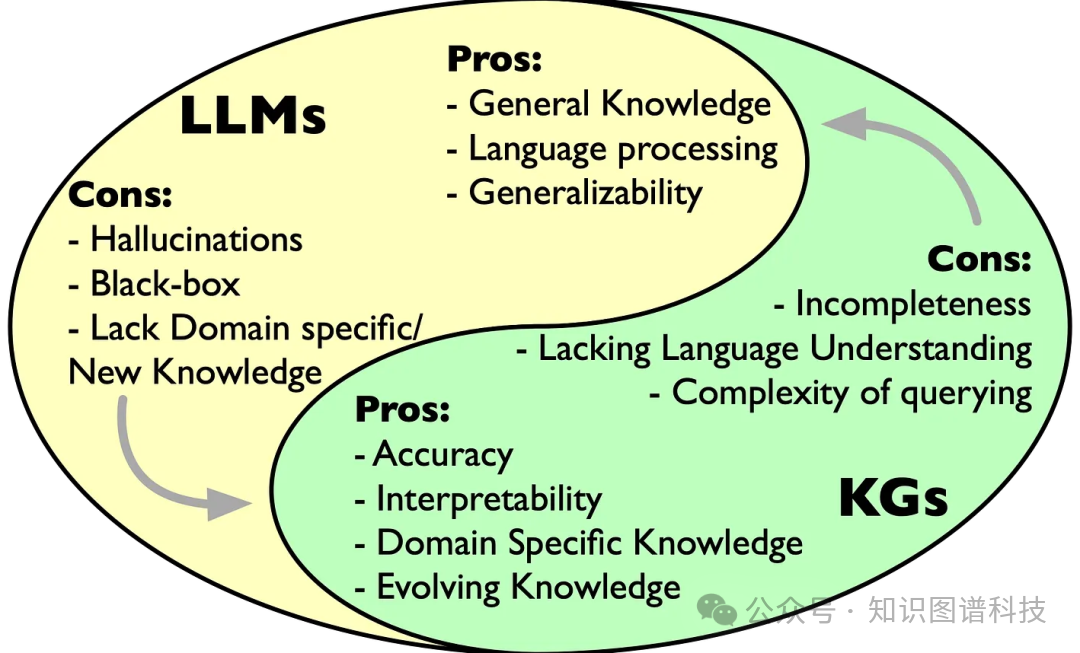
[LLM和知识图谱如何互补示意图]
4.2 如何避免施瓦茨式灾难
考虑这个混合系统如何能够防止施瓦茨的灾难。一个混合系统会:
-
使用LLM处理自然语言查询
-
查询知识图谱以获取带有真实引用和来源的经过验证的信息
-
呈现带有上下文的结果:"从权威数据库找到12个带引用的已验证案例"
-
提供实际来源的验证链接
-
标记不确定性:"未找到与此确切模式匹配的案例。请考虑这些替代方案。"
最关键的是:当被问及"这个案例是真实的吗?"时,系统会回答:"此案例引用无法在权威数据库中验证。状态:未经验证。"
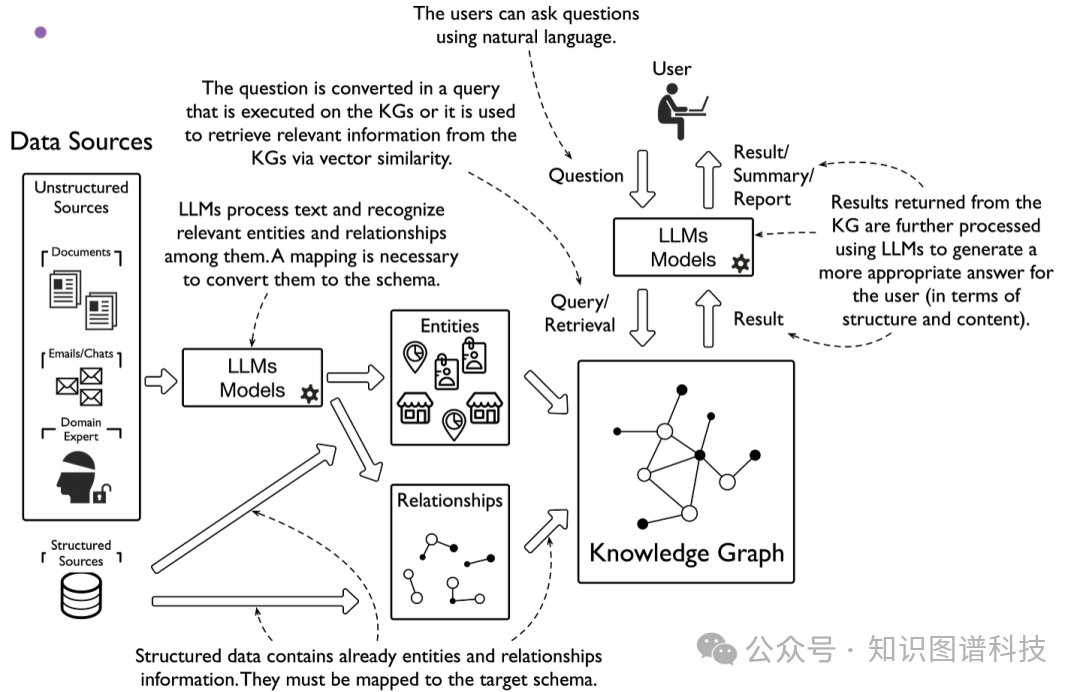
[使用和不使用LLM构建知识图谱,以及LLM支持查询和检索的流程图]
4.3 全面的价值主张
来自行业领导者的研究一致表明,混合系统解决了导致AI项目失败的核心挑战:
-
缓解幻觉:通过将LLM响应建立在可验证的知识图谱策划事实上来缓解幻觉。
-
保持知识最新:通过动态知识图谱更新保持知识最新。LLM通过不断演化的知识图谱访问最新信息,无需重新训练。
-
内置可解释性:通过透明的信息路径实现内置可解释性。
-
提高特定领域准确性:因为知识图谱编码了通用LLM缺乏的专家知识、法规和关系。
五、构建值得信赖的AI系统
5.1 专业责任的核心
施瓦茨案的法官指出,"技术进步是司空见惯的,使用可靠的人工智能工具进行辅助本身并没有什么不当",但强调"现有规则要求律师发挥把关作用,以确保其提交文件的准确性"。
这一原则具有普遍适用性:每个部署AI的专业人士都有把关责任。 问题在于您的AI系统架构是支持还是破坏这一责任。
5.2 关键应用的未来
关键应用中AI的未来——跨越每个行业——取决于构建智能顾问系统,将知识图谱的结构化知识和可解释性与LLM的自然语言理解和模式识别相结合。这不是在技术之间做选择,而是理解仅靠LLM缺乏值得信赖的AI所需的基础。知识图谱提供了这一基础。
当组织在没有这种基础的情况下部署LLM时,项目会失败——不是因为技术不够强大,而是因为没有基础的力量是不可靠的。当正确完成时——结合互补优势并补偿彼此弱点的技术——我们创建的系统能够真正增强人类智能。
5.3 实践指南
[550页电子书]2025年10月最新出版-知识图谱与大语言模型融合的实战指南:KG&LLM in Action

在《知识图谱与LLM实战》一书中,我们提供了构建这些混合系统的全面指导:从建模知识图谱模式和使用LLM进行实体提取,到创建能够准确和可解释地回答特定领域问题的对话式AI。该书通过具体实现,展示了如何架构组织能够真正信任、用户愿意采用的智能顾问系统。
架构选择在您手中:在不稳定的基础上部署LLM并冒着加入失败项目的风险,或者将它们建立在使AI值得信赖、可解释和真正有价值的知识图谱基础上。
Steven Schwartz以惨痛的方式学到了这一课。您不必重蹈覆辙。
六、对专业人士和决策者的启示
6.1 技术选型建议
对于企事业单位和科研院所的专家及投资人,在评估和部署AI项目时应考虑:
-
基础设施评估:确保AI系统具有可验证的知识基础,而不仅仅是依赖LLM的生成能力
-
风险管理:在关键应用中实施智能顾问系统架构,保留人类专家的最终决策权
-
可持续性:选择能够动态更新知识而无需昂贵重训的混合架构
-
合规性:确保系统提供完整的审计追踪和可解释性,满足监管要求
6.2 投资价值分析
从投资角度看,知识图谱+LLM的混合架构具有:
- 更高的成功率
:相比单纯LLM项目,能显著降低因知识对齐问题导致的项目失败率
- 更长的生命周期
:知识基础设施的可持续性和可维护性带来更长期的价值
- 更广的应用场景
:在医疗、法律、金融等高价值关键领域具有实际可部署性
- 更强的竞争壁垒
:领域知识图谱的构建需要专业知识积累,形成技术护城河
七、结语
施瓦茨律师的案例为整个行业敲响了警钟。它揭示的不仅是一个技术问题,更是一个架构选择问题。在AI快速发展的今天,我们必须认识到:没有知识基础的智能只是幻象。
知识图谱不是可有可无的补充,而是让LLM在关键应用中真正落地的必要基础设施。当我们将两者正确结合时,我们不仅避免了灾难性失败,更创造了能够真正增强人类智慧、值得信赖的智能系统。
这不是技术的终点,而是可信AI时代的起点。
展望未来,我们需要在三个层面持续努力:
技术层面,推动知识图谱与LLM的深度融合,建立更加精准的事实验证机制;应用层面,在法律、医疗等高风险领域建立强制性的知识基础要求;伦理层面,明确AI系统开发者和使用者的责任边界。
施瓦茨的教训告诉我们:技术创新必须建立在可靠的知识根基之上。只有这样,我们才能构建真正服务于人类、经得起考验的智能系统。
在这个转折点上,每一位技术从业者、决策者和用户都肩负着共同的使命:不是盲目追逐技术的炫目,而是审慎构建可信的智能未来。
当我们回望施瓦茨案件时,或许会发现它最大的价值不在于警示,而在于启示——它让我们看清了前行的方向。在知识图谱的坚实地基上,LLM的创造力才能真正绽放;在严谨验证的护栏中,AI的潜能才能安全释放。
这条路或许更长,但它通向的是一个值得信赖的智能时代。
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。

















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









