



文章目录
- ARM 相关
- 内存相关
- 调度相关
- 文件系统相关
- 磁盘I/O相关
- 内核驱动相关
- 要实现一个驱动,应该思考要做些什么(随时补充)
- 关于device_create()和cdev_register()的一些思考
- 设备树节点都表示什么信息?一些特殊属性的作用?(待处理)
- 如何编写Pinctrl的设备树信息以及驱动程序
- 如何编写Gpio的设备树信息以及驱动程序
- 如何编写中断的设备树信息以及驱动
- 如何编写i2c adpater的驱动
- 如何编写spi adapter的驱动
- 中断下半部的三种方法
- 设备树根结点会不会被解析成一个节点?
- 设备树编译过程,在内核中的加载与解析过
- 关于GPIO编号问题?(待处理)
- 关于uboot的设备树?(待处理)
- 为什么copy_from_user()/copy_to_user()更加安全
- 驱动文件静态编译和动态编译的区别是什么?insmod之后发生了什么?
- USB驱动热插拔相关
- 关于linux 驱动模型中的uevent机制
- 关于mdev/udev,它们的工作原理是什么,有什么区别?
- 关于netlink机制
- 设备模型(待处理)
- /sys观测目录(待处理)
- /proc观测目录以及原理待处理)
- 常用的/proc观测节点(待处理)
- 关于debugfs调试文件系统(待整理)
- cat和echo,是怎么实现的?(待处理)
- dmesg的底层原理
- 添加一个ftrace和perf的使用示例(待处理)
- perf底层原理分析
- 为什么delay()会占用CPU,为什么不用定时器
- kernel中如何访问I/O空间
- user与kernel之间使用mmap,用过吗?
- 关于LCD驱动的一些信息
- 对dtb的转换工作,最后的结果如何?
- gpio子系统和pinctl子系统的设备树编写和其他设备不太一样,应该怎么编写?
- 软终端,tasklet,工作队列的区别
- 内核其他模块零散知识
- 硬件设备相关
- 通用知识
进程切换时,只需要设置页表基址寄存器即可完成页表的切换,也就完成了进程地址空间的切换,ARM-v7体系架构提供的寄存器是协处理器CP15寄存器TTBR(Tranlation Table Base Register);ARM-v8体系架构提供的寄存器是系统寄存器TTBR_ELn(Tranlation Table Base Register)。
ARM 相关
armv7/armv8/x86寄存器的差异,在不同工作模式下armv7不同寄存器的差异
- v7其实是有34个通用寄存器,因为有一些在不同模式会使用不同的寄存器,可分为:
未备份寄存器(R0~R7),因为这8个任何模式下都一样;
备份寄存器(R8 ~ R12),这5个在FIQ下不一样!是独立的,这样就可以不用保存其他模式下的现场,从而加速快速中断的执行。
未备份寄存器R13(SP寄存器),除了User和sys,其他模式都是各有一个,R14(LR寄存器)差不多
PC寄存器,对三级流水线来说就是取指->译码->执行。所以PC指向的指令,比现在正在执行的指令靠前两个指令(8字节)

- armv8 寄存器,可以分为四类:
通用寄存器(General-purpose Registers),31个通用寄存器
状态寄存器(Status Registers)
专用寄存器(Special-purpose Registers)
系统寄存器(System Registers)

- 关于ARMv8的一些特殊寄存器(状态寄存器PSTATE,类似于armv7 CPSR寄存器,用来保存一些系统状态 + 专用寄存器SP_ELx、ELR_ELx、SPSR_ELx),ELx存放异常返回地址,应该是触发异常的时候会调用。SPSR用来保存PSTATE寄存器的副本。其中有一些寄存器其实是PASTE寄存器中的某一段,如DAIF,SPSel,PAN。UAO,NZCV等等
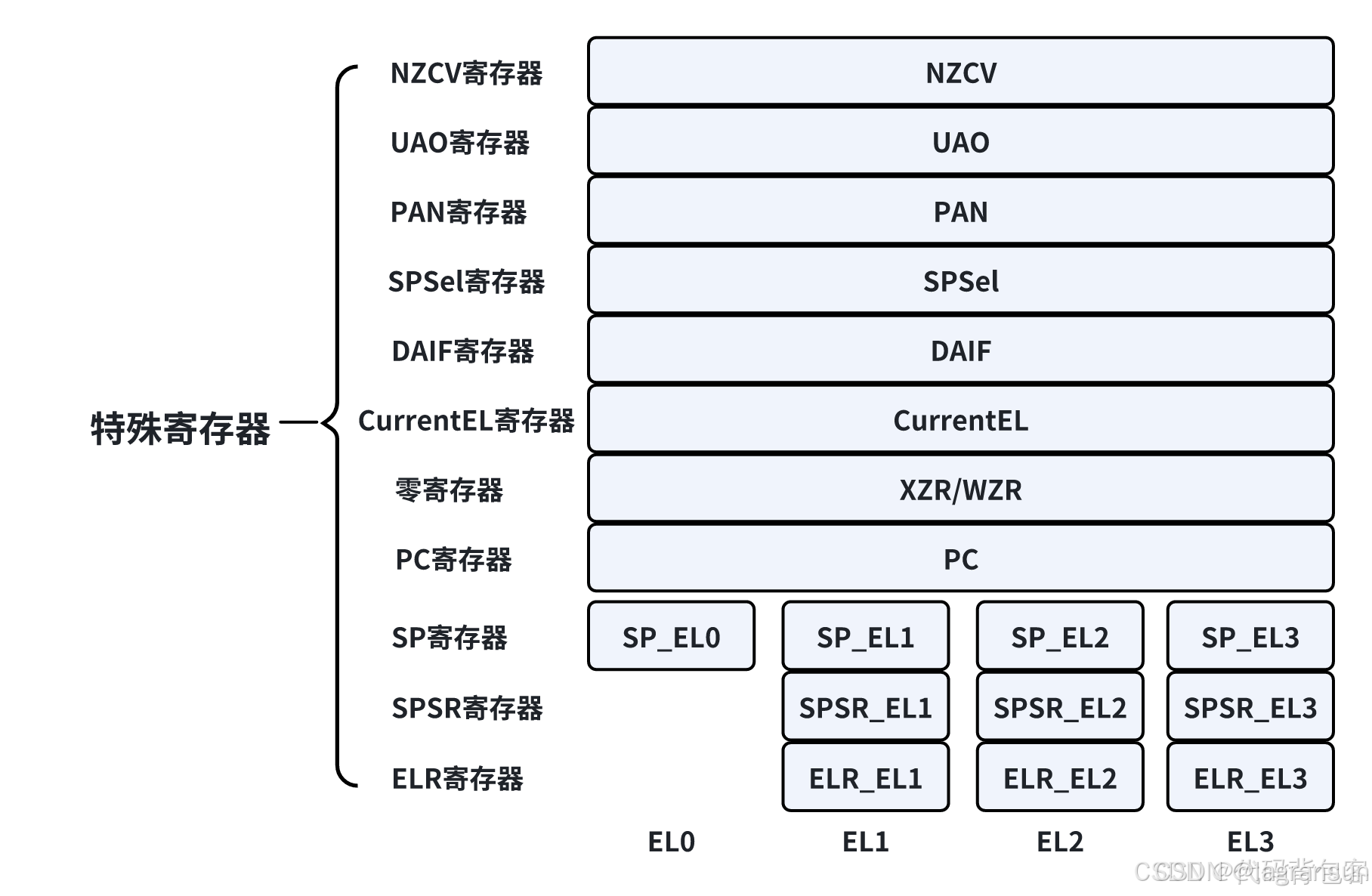
- 系统寄存器,相当于把armv7 CP15协处理器拆开来。遇到过的有:
1.ESR_ELx (exception Syndrome register )异常综合寄存器/异常状态寄存器 : 反应异常(只反映异常!!不反映中断)的原因等信息。没有ESR_EL0
2.FAR_ELx (Fault Address Register) 错误的地址寄存器当取指令或取数据时,PC对齐错误或者watchpoint异常(PC alignment fault and Watchpoint exceptions),会将错误的地址填入到该寄存器中;
3.SCTLR_EL1, (System Control Register) 系统控制寄存器
4.TTBR0_ELx/TTBR1_ELx(Translation Table Base Register):转换表基地址寄存器,用于定义页表的基地址,支持内存地址转换和虚拟内存管理。TTBR0是用户页表基址,TTBR1是内核页表基址
5.VBAR_ELx:中断向量表基址寄存器。
异常和中断的区别,异常和中断发生时的处理过程
限制下架构,就以ARMv8-A架构为例:
- 同步异常:由于执行某些指令而从处理器内部产生的。同步异常触发后,系统必须立刻处理而不能依然执行原有的程序指令步骤。如被零除的算术运算。
- 异步异常:来源是外部硬件装置。异步异常可以延缓处理甚至忽略。如按键中断事件。
- 有哪些异常,哪些中断,这篇文章做了个总结:ARMv8-AArch64 的异常处理模型详解之异常类型 Exception types
- 处理器提高特权的唯一方法:通过异常等级切换,从低的异常等级切换到高的异常等级。同理,处理器若是想降低特权,惟一的方法就是通过异常返回
- 当异常发生时,ARMv8-A的处理过程:
1.将PSTATE寄存器的值保存到对应目标异常等级的SPSR_ELx寄存器中;
2.将异常返回地址保存在对应目标异常等级的ELR_ELx寄存器中;
3.把PSTATE寄存器里的D、A、I、F标志位都设置为1,相当于把调试异常、SError、IRQ以及FIQ都关闭,关中断!!所以不会出现中断嵌套,但是可以看到没有屏蔽同步异常!!仍然可以触发同步异常;
4.对于同步异常或系统错误异常,CPU会将异常的原因写入ESR_ELx寄存器中;
5.对于同步异常,把错误地址保存在FAR_ELx寄存器中;
6.切换SP寄存器为目标异常等级的SP_Elx或者SP_EL0寄存器;
7.从异常发生现场的异常等级切换到目标异常等级,然后跳转到异常向量表里。 - 异常退出时,ARMv8-A通过ERET指令即可从异常返回。ERET指令会自动完成如下工作:
1.从SPSR_ELx寄存器中恢复PSTATE寄存器的状态;
2.从ELR_ELx寄存器中恢复PC指针。 - 发生异常的时候需要保存异常进入地址到ELR_ELx:
1.异步异常(irq/fiq等)是返回地址指向第一条还没执行或由于中断没有成功执行的指令;
2.如果是除系统调用的同步异常,比如数据异常、访问了没有映射的地址等,返回的是触发同步异常的那条指令;
3.如果是系统调用,返回的是系统调用指令(例如SVC指令)的下一条指令。
异常和中断的深入理解
-
ARM架构无法屏蔽同步异常,同时在2021年的扩展中,Armv8.8-A和Armv9.3-A增加了不可屏蔽的中断(Non-maskable interrupt,NMI)支持。当NMI被支持和启用时,可以通过该功能将具有超优先级(Superpriority)的中断发送给给处理器。
-
整理一下这一篇:Linux中断管理 (1)Linux中断管理机制
-
为什么linux不支持中断嵌套:为什么Linux不支持中断嵌套,总结:
历史上,linux中断处理有快慢中断和IRQF_DISABLED这个标记的概念,如果中断处理函数没有带IRQF_DISABLED这个标记,linux内核代码在处理中断时会打开本CPU响应中断的能力,而GIC又有能力上报优先级更高的中断到CPU,所以这时ARM+GIC组合的系统就能支持中断抢占嵌套。在后来的一个commit中,中断处理中不再支持打开CPU中断的操作,从而不再支持中断嵌套,该提交关闭中断嵌套的原因是,中断嵌套可能导致栈溢出。 -
中断中又触发了同步异常怎么办:Armv8架构,在中断中,又触发了同步异常,那么ELR_ELX寄存器会被覆盖掉吗?,总结:
1.会被覆盖掉,除非你在你的中断处理函数入口处手动进行保存ELR_ELx寄存器,然后在中断处理函数结束前恢复。如果没这样做,出现异常可能导致系统崩溃
2.但是同步异常可以抢占同步异常,所以同步异常的入口函数/出口前是有做保存和恢复工作的。 -
关于armv8的调试异常,后面再探索一下
-
关于NMI中断,可以看一下:ARM三种NMI中断,但是没找到讲的好的文章,认知还是比较模糊。
-
一定要学习一下GICV3,现在的设备都是GICV3,参考两篇文章:①一文看懂GICV3,这篇文章把很多相关的都概括了,但是好像有点不对劲。②ARMv8 GICv3 学习笔记(一)。这个好一点。对这些文章做一些总结:

-
这就是V3的架构,大致可以看出来,V3可以为每个CPU提供四种中断:IRQ、FIQ、vIRQ,vFIQ,其中v开头的是给EL2特权级用的,也就是虚拟化。外设或软件触发中断后,GICv3根据中断配置信息,将其路由到特定cpu的IRQ或FIQ中断线上,并且可以通过配置 HCR 寄存器可以将一些异常路由到 EL2 的 hypervisor,执行 EL2 的异常处理程序来处理异常,或者配置 SCR 寄存器可以将异常路由到EL3 secure monitor。CPU接收到中断后执行必要的上下文保存后,跳转到中断异常入口,并执行相应的中断处理流程。
-
上面这四种中断是CPU的中断表现,实际上根据GICV3的架构,对于GIC来说可以分为四种中断类型,最终GIC将自己的终端类型根据配置信息路由到CPU的中断线上:
①SPI中断,不与特定CPU绑定,可以根据路由表路由到某个CPU上。一般的外设中断都是通过SPI连接。这种路由设计思想,很像TDA4的异构核间中断外设NAVSS,只不过这里是路由到SMP核,NAVSS是路由到异构核。 GIC有控制SPI类型中断的路由控制寄存器为GICD_IROUTER,设置该寄存器配置了中断的路由方式。内核中可以通过一些api设置该寄存器从而改变路由方式。
②PPI中断,每个处理器私有中断。比如说SMP的timer的中断,每个CPU都有一个定时器。
③SGI中断,该类型中断并没有实际的物理连线,而是由软件通过写SGI寄存器方式触发,它只支持边沿触发。通常用于处理器之间的通信,如linux内核电源管理模块中调用的ipi中断就是通过SGI实现的。实际上,SMP的核间通信也是靠这个中断触发
④LPI中断,该类型中断是一种基于消息的中断,外设不需要通过硬件中断线连接到GIC上, 而可以向特定地址写入消息来触发中断。典型的应用为PCIe的MSI和MSI-X中断。这个完全没听说过,是GICv3第一次引入的中断
⑤GIC架构可由下图表示:

-
针对上图架构进行进一步说明:
①PE,Process Element:处理器单元,中断的最终接受者和处理者,其实就是CPU,理解为CPU就行了。
②所有SPI(一般外设)连接在Distributor,GICV3使用该组件管理SPI中断,我个人把它理解为GICV3的第一道门槛,只有一个。可以:配置每个SPI的优先级、使能/失能每个SPI、控制SPI状态机、设置每个SPI触发模式(边沿、水平)等
③Distributor、SGI、PPI、LPI中断,最终都会发给Redistributor组件来管理。**每个PE(可以认为是每个CPU)都会配备一个Redistributor(其实是每个CPU interface会配备一个)。**该组件可以:使能/失能SGI/PPI、配置SGI/PPI的优先级、配置PPI的触发模式(边沿、水平)、对每个SGI/SPI进行中断分组、控制SPI/PPI状态机,控制LPI所需的配置信息表。
④CPU interface:传输中断给 PE, 每个 Redistributor 连接了一个CPU interface,负责打开和关闭PE的中断处理能力,为PE维护一个中断优先级掩码(只响应更高优先级中断),定义中断抢占策略,执行中断降级等。可以:打开/关闭中断处理、中断应答、为CPU设置中断优先级掩码(哪些中断不给上报)、设置CPU中断抢占策略、多个中断事件到来时,选择一个最高优先级中断通知CPU。 -
中断控制器为每个 SPI、PPI 和 SGI 中断源维护一个状态机,我们只考虑边沿触发中断,此时状态机由 4 种状态组成,其中的Active and pending状态是当一个中断A的实例在处理的时候,又发生了中断A:

①A1,A2:外设/CPU产生中断会触发该转换
②B1,B2:移除pending状态,不知道什么时候触发该转换
③C:CPU(也就是PE)确认了该中断。当CPU从GICv3的CPU interface组件中读取一个INTID值(中断号)时触发该转换
④D:与电平触发模式的中断有关,先不考虑
⑤E1,E2:当 CPU写入GICv3的CPU interface组件的一个EOIR寄存器时,会消除Active状态。 -
给每个中断源分配一个优先级值来配置 GIC 中的中断优先级 – 裸机开发中常用的
①GICD_IPRIORITYR 寄存器保存每个支持的 SPI 的优先级值,该寄存器的个数为 255 个
②在多处理器实现中,GICR_IPRIORITYR 和 GICR_IPRIORITYRE 寄存器为每个目标 PE 独立定义了每个 SGI 和 PPI INTID 的中断优先级,针对 LPI 类型的中断,主要通过在内存中的 LPI 配置表存储关于 LPI 的优先级信息,而不是寄存器。
③为了简单起见,一般将所有的中断优先级位都配置为抢占优先级(可以通过寄存器配置抢占优先级和子优先级占用的bit数) -
linux对中断优先级是怎么设置的呢?会在启动时配置GIC的寄存器吗?
kernel-5.10内核,除虚拟化相关逻辑外,仅对NMI中断的处理优先级进行了配置,其他如SPI类型的中断都没有设置对应的中断优先级,即这些中断的优先级为GIC寄存器中的默认值0,这些SPI的中断具有相同的优先级,所以这些中断不存在中断竞态问题。
参考 - - Linux中断 – 中断路由、优先级、数据和标识
C语言传递参数是用哪些寄存器,v7/v8/x86_32/x86_64不同架构对比
- 对于armv7,传递参数使用R0-R3寄存器(对应参数从左到右),多余的用栈传递。返回值保存在r0,如果是64位的返回值保存在r0和r1中。
- 对于armv8,传递参数用x0 - x7,剩余的用栈。返回值用x0保存。
- x86_32,32位x86不使用寄存器传参,直接参数入栈(参数顺序从右向左入栈,与arm反着)。这样肯定没有使用寄存器传参高效。
- x86_64,使用rdi、rsi、rdx、rcx、r8、r9保存1~6个参数,多余的仍然是入栈。
SPM架构多核启动流程
内存相关
内存初识
页表的映射。以一级页表和页大小(物理页)为4KB(2^12)为例:
页表就把他认为是个数组吧,里面装着一个个的页表项。
如果是32位虚拟地址,前20位表示页表的偏移,后12位表示物理页内偏移
先通过前20位,从页表这个数组中找到对应的页表项,这个页表项中记录着真实的物理页表的前20位
为什么需要记录物理页表的前20位呢?因为我们用了4KB物理页页大小!!!!,所以前20位,每+1或者-1,都代表着移动了4KB!!也就是移动了一个页!!!!!就像是0,4,8,12,16,然后再通过后12位,就可以从4KB中找到精准的位置!!!
文件映射区域:如动态库,共享内存等映射物理空间的内存,一般是mmap函数所分配的虚拟地址空间,新建了一个vm_area_struct
所有内核线程共用一套页表
所有进程的内核空间,关联的都是相同的物理内存!!对于这个进程来说,无法访问3-4G内存,进入了系统模式后才可以访问。应该是这一部分内核空间,会为每一个进程都分配1~2页栈。
内存管理相关
这个真得好好整理整理
- ARM64的内存管理的硬件支持是MMU,包括TLB和TWB(页表遍历单元)两个部件。TLB用于缓存页表转换的结果,TLB未命中时需要使用TWB遍历页表,找到虚拟地址对应的物理地址
- 找到物理地址后,首先查询物理地址的内容有没有在高速缓存(cache)中,如果没有命中,则需要通过地址总线去DDR中查询。ARMV8-A支持的最大物理地址宽度为48位
- 对于操作系统来说,每个进程都有一个虚拟地址空间,其中0x0~0x0000 FFFF FFFF FFFF为用户地址空间,共256TB;0xFFFF 0000 0000 0000 ~ 0xFFFF FFFF FFFF FFFF
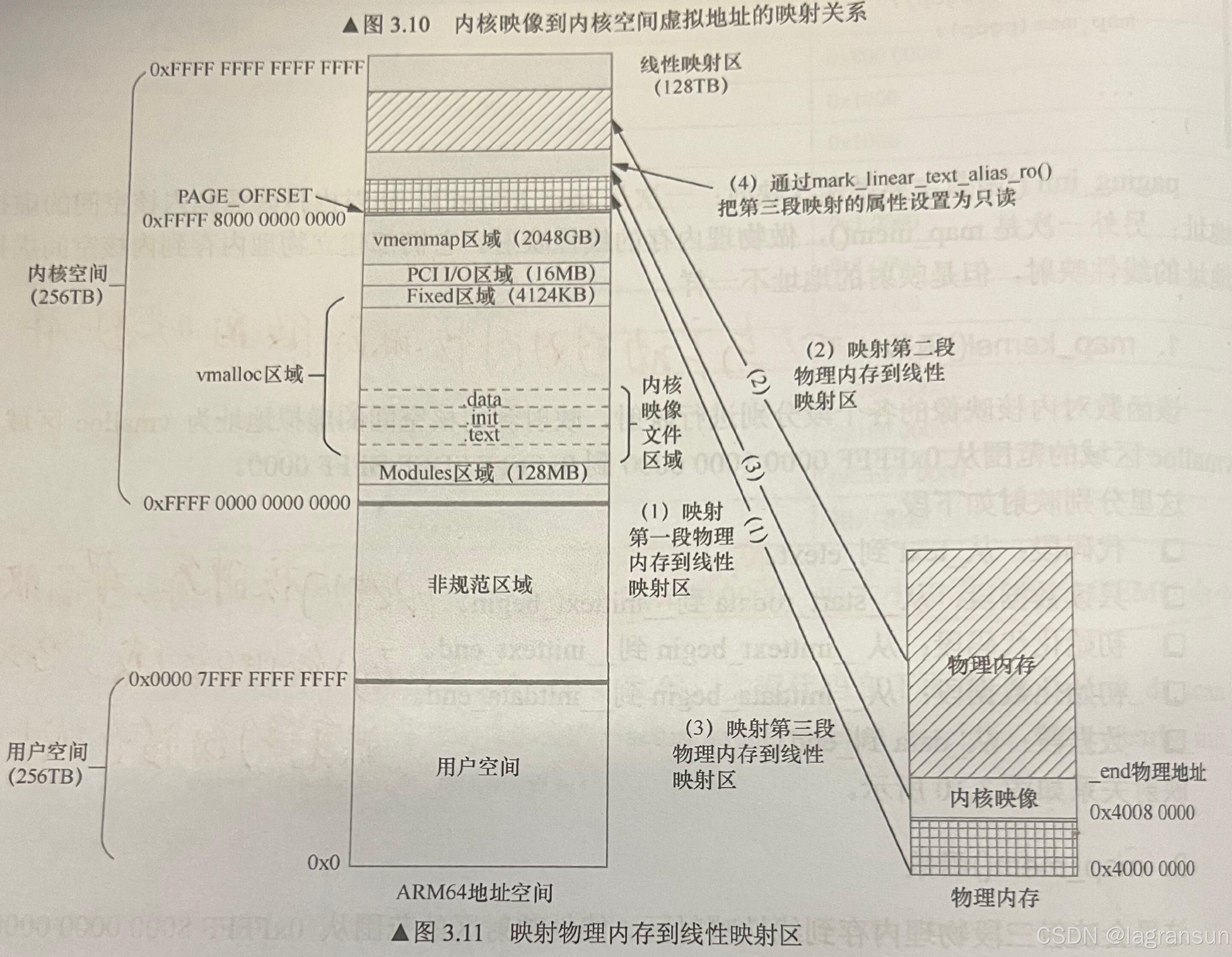
- 在内核空间中,从下到上分别是Modules区(应该是加载module的);vmalloc区(内核映像就放在这个区,这个区我认为就是内核堆区);fixmap区(固定区),I/O区,Vmmmap区(这个区得再研究下,不知道干嘛的),线性映射区(减一个固定offset得到物理地址)。这些划分地址由几个宏来决定,而内核代码段的起始地址则由arch/arm64/Makefile中的TEXT_OFFSET决定,最终内核会从KIMAG_ADDR+TEXT_OFFSET处开始执行。
arch/arm64/include/asm/memory.h:
#define VA_BITS (CONFIG_ARM64_VA_BITS)
#define _PAGE_OFFSET(va) (-(UL(1) << (va)))
#define PAGE_OFFSET (_PAGE_OFFSET(VA_BITS))
#define KIMAGE_VADDR (MODULES_END) // 内核映像起始地址
#define MODULES_END (MODULES_VADDR + MODULES_VSIZE)
#define MODULES_VADDR (_PAGE_END(VA_BITS_MIN))
#define MODULES_VSIZE (SZ_128M)
#define VMEMMAP_START (-(UL(1) << (VA_BITS - VMEMMAP_SHIFT)))
#define VMEMMAP_END (VMEMMAP_START + VMEMMAP_SIZE)
#define PCI_IO_END (VMEMMAP_START - SZ_8M)
#define PCI_IO_START (PCI_IO_END - PCI_IO_SIZE)
#define FIXADDR_TOP (VMEMMAP_START - SZ_32M)
#if VA_BITS > 48
#define VA_BITS_MIN (48)
#else
#define VA_BITS_MIN (VA_BITS)
#endif
#define _PAGE_END(va) (-(UL(1) << ((va) - 1)))
#define KERNEL_START _text
#define KERNEL_END _end

- 启动的时候在stext的汇编阶段会建立内核映像的页表,因为启动的时候只需要知道内核映像就可以了,算是个临时页表把。最后映射结果就是:

- 然后在kernel的启动函数start_kernel()中完成整个内核空间页表的创建:
start_kernel()
->setup_machine_fdt() // 解析设备树中的ddr信息,找到ddr基址(可以用的ddr基址,有可能有一些ddr会作为核间通信区,或者说多核共用一块ddr)和size
->paging_init() // 建立整个内核页表
- 最后的映射结果为,第二段映射是线性映射区,虚拟地址的起点是内核映像映射的end(虚拟end),直到物理内存的end,所以不一定能映射满所有的虚拟地址,映射的size就是(物理内存end - 内核映像的物理end)
- 初始化完成后,就需要进行内存管理了。内存管理的第一个概念:ZONE。
1.arm32一般会将ZONE分为ZONE_DMA/ZONE_NORMAL/ZONE_HIGH,其中HIGH是为了管理那些无法线性线性映射虚拟内存中的物理内存(因为32位内核虚拟内存一般就配置成1G,物理内存基本上早就超过1G了)。
2.现在64位没这个烦恼,随便映射,所以现在64位已经没有ZONG_HIGH了,一般只有ZONE_DMA+ZONE_NORMAL
3.每一个内存节点,都有个zonelist,把所有该内存节点的ZONE链接起来。对于UMA来说只有一个内存结点,而NUMA则有多个内存结点,也就有很多个ZONE - 在到buddy之前,还要经历一个阶段,这时候是另外一套简单的管理系统:bootmem或者是memblock:memblock分配器。从set_up()->…->early_init_dt_scan_nodes()把内存信息解析出来,到mm_init()->…->__free_pages_memory()建立buddy之前,都是使用临时内存管理系统bootmem或memblock
start_kernel()
->setup_arch()
->...
->early_init_dt_scan_nodes() // 茨贝格dtb数据中先解析一些关键节点(重要物理设备信息),引导内核启动
->early_init_dt_scan_memory()
->early_init_dt_add_memory_arch()
->memblock_add() // 把解析设备树得到的内存信息通过memblock内存系统来管理
->..
// 这期间,都使用临时内存管理系统
->..
->mm_init()
->..
->->free_low_memory_core_early() // 初始化buddy,把memblock管理的内存块添加到buddy的链表中
- ZONE中涉及到内核内存管理的第一个强力管理系统:Buddy,ZONE通过struct zone->free_area[MAX_ORDER]进行管理,有MAX_ORDER(一般为11)个free_area,一个struct free_area包括MIGRATE_TYPES(迁移类型)个free_list。所以,一个ZONE中总共有11×MIGRATE_TYPES个free_list
- 有哪些类型的ZONE以及每个ZONE中有哪些迁移类型?可以通过cat /proc/pagetypeinfo来看
- 什么时候向buddy管理系统中添加页面?在初始化的时候,遍历所有内存块,把合适的内存块添加到对应的链表,因为是按照页帧号来对齐(从页帧号0一直遍历到最后一个页帧,页帧号代表第几页)添加,导致大部分页面都添加到2^10这个order的链表中了。这里指的对齐是什么呢?就是页帧号的第一个不为0的bit的位置,就是order
1.举个例子:

所以当以0x400对齐(bit 10 = 1)之后,其余都会被添加到order10这个链表中,0x88400(bit10 = 1),0x88800(bit11 = 1,但是order不能超过10,取MAX_ORDER与bit的最小值),0x88c00(bit11 = 1)。添加过程如下:
start_kernel()
->mm_init()
->mem_init()
->memblock_free_all()
->free_low_memory_core_early() // 初始化buddy,把内存块到buddy的链表中,初始化状态下全为MIGRATE_MOVABLE
->__free_memory_core()
->__free_pages_memory()
- 如何向buddy申请页面?基本上就是alloc_pages()及其各种变种。传入的参数最重要的就是分配掩码,由各种修饰符混合而成,可以控制本次分配可选地条件:
1.内存管理区修饰符标志:从哪个ZONE中进行分配?
2.移动修饰符标志:分配的页面具有何种迁移属性?
3.水位修饰符标志:是否可以从系统预留内存中分配(最低警戒水位以下的内存会作为系统预留内存)?4.页面回收修饰符标志:第一次分配失败后是否会一直尝试?分配过程中是否允许开启页面回收/磁盘IO?
5.行为修饰符标志:分配的内存是否会被立刻使用?是否分配一个全填充0的页?是否关闭一些错误报告? - 除buddy外,还可以通过slab(暂不考虑slob/slub)来分配内存,可以弥补buddy无法分配小于一页的内存的情况。关于slab,需要专门作为一个问题来总结。
buddy分配方法中,伙伴的含义
- 两个块的大小相同,假设为b
- 两个块的物理地址连续
- 伙伴中第一个块的起始物理地址是2×b×PAGE_SIZE的整数倍。即第0块和第1块是伙伴,第2块和第3块是伙伴,但是第1块和第2块不是伙伴。这样规定的目的是确保一对伙伴中的两个块可以合并成更高一级的大块。没太看明白
buddy分配和回收的具体过程
-
声明:在这之前已经介绍过内存管理中有个ZONE的概念,每一个ZONE中的内存都是由buddy这种系统来管理。还有个内存节点的概念(UMA架构只有一个内存节点),一个内存节点中的所有ZONE通过一个struct zonelist结构来管理,保存在zonelist->_zonerefs[]数组中,该数组的每一个变量对应一个ZONE。接下来只考虑UMA架构。
-
_zonerefs[]数组并不是随便添加ZONE的,而是有意将优先考虑的ZONE放在数组靠前的位置。优先考虑指的就是,当使用buddy的接口分配页面时,优先考虑从靠前的ZONE中分配页面。至于每个zone对应的zone_idx,我没看明白它是怎么计算得出的。

-
以上图为例,当调用alloc_pages()系列使用buddy的接口函数的时候,会优先从zoneref[0]中分配,也就是优先从ZONE_NORMAL中分配页面。换言之,优先考虑操作ZONE_NORMAL中的free_area[]数组。
-
分配页面的过程过于复杂,需要注意几点:
1.先检查是否满足分配要求,包括检查该ZONE的水位(是否到了预留内存),检查如果不满足是否能通过页面迁移来满足需求等。
2.满足分配需求后就开始切蛋糕。切蛋糕的意思就是,如果所需的order为5,但是order5的链表已经每法满足需求了,就去order6切个order5出来,切完后把另外的一半order5重新添加到order5链表中
3.针对第2点,会从低阶order一直找到MAX阶order,直到找到有空闲页面的链表。如果找到MAX阶order还没有,就开始从其他迁移类型的高阶order中偷内存。比如我需要分配order=5大小的MOVABLE类型的内存,结果一直找到order=10的MOVABLE类型的链表都没找到合适的,只能去RECLAM类型中偷点内存。
4.期间穿插着一些水位检查和碎片回收工作,暂时没太看懂处理过程

-
回收时,调用free_page()进行释放 ,基本上就是分配的逆过程
1.关闭CPU本地中断
2.进行释放内存的合并,不断检测相邻内存是否可以合并,直到无法合并为止。内存块A和B能合并的要求:①内存块B在伙伴系统中;②内存块B和内存块A的order相同;③内存块B和内存块A要在同一个zone中;
slab框架简析
- 先来说一下slab的特性:
1.把要分配的内存当作对象看待,可以自定义构造函数和析构函数来初始化对象的内容或者释放对象的内容
2.slab对象被释放之后不会马上被丢弃而是继续保留在内存中。
3.slab机制可以根据特定大小的内存块来创建slab描述符
4.slab创建了多层缓冲池,充分利用了空间换时间的思想,体现在:①PerCPU缓冲池,避免多核竞争;②每个内存节点都有共享对象缓冲池(暂时不考虑,除了服务器没人用NUMA)
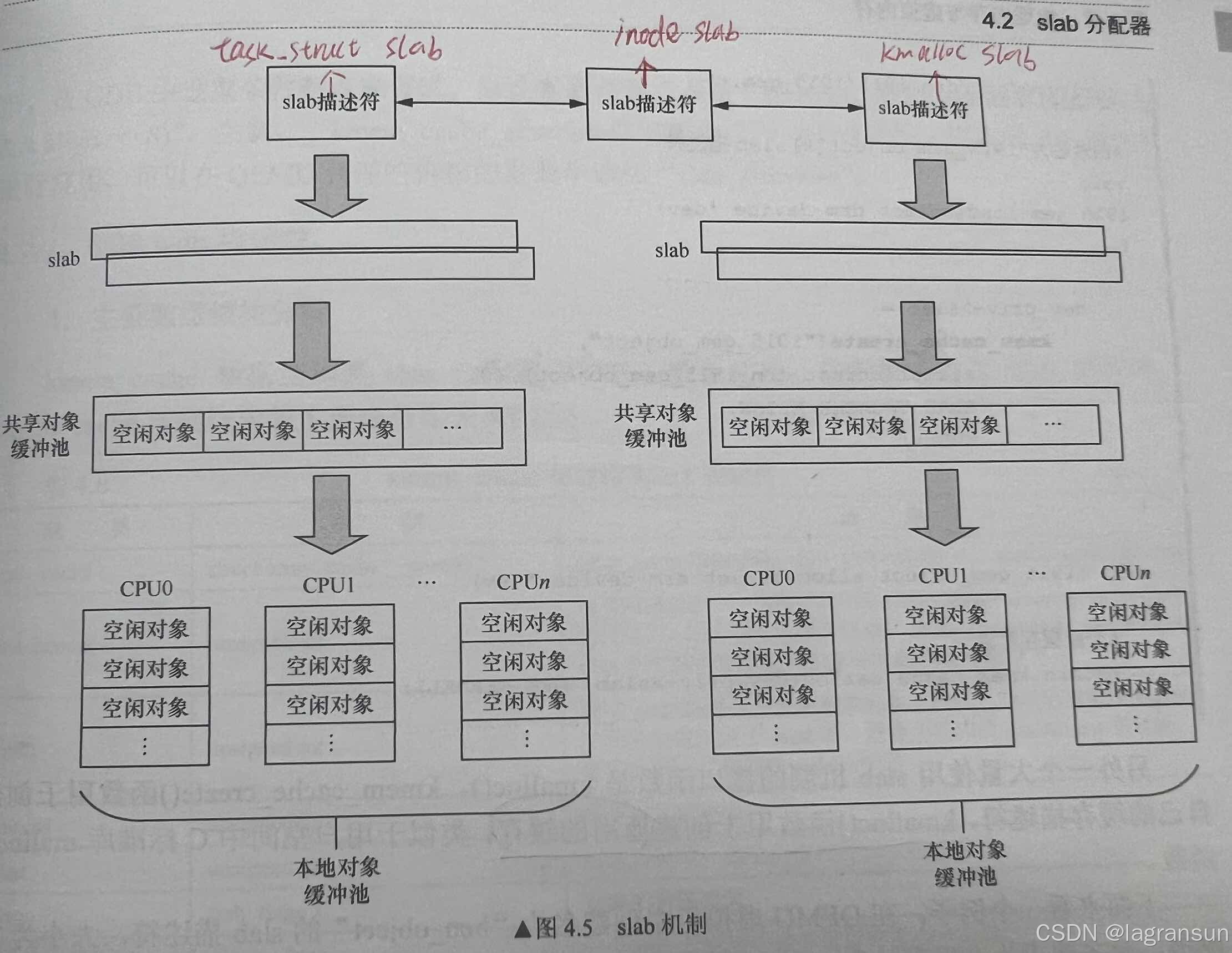
- 使用slab系统的api是:

- 首先得创建slab描述符,创建slab描述符的过程非常复杂,总结一下关键点:
1.计算一个slab分配器需要多少个连续的页面?(以order为单位,如果至少order0一个页面能放下一个slab对象,就是order0。如果至少order1两个页面才能放下一个slab对象,就是order1)
2.一个slab分配器能保存多少个slab对象?因为至少order0,对于一下小slab,一个页面能保存很多个slab对象的
3.一个slab分配器包含多少个着色区?
4.管理区大小是多少?与采用的管理区架构有关
5.注意,创建slab描述符只是初始化其中的成员变量,并没涉及到与buddy系统的交互 - 创建完slab描述符后,就可以调用kmem_cache_alloc()从中分配slab对象了,此时需要真正的分配物理页面了:
1.从buddy中分配的页面作为slab分配器时,page结构体中会有俩成员变量标志着此页面被分配为slab分配器:①page->s_mem:表示第一个slab对象的起始地址(等于slab分配器的首页地址+着色区大小);②page->active:记录活跃slab对象的计数

- 释放slab对象需要调用kmem_cache_free():

- 整个slab系统的架构就是这样的:

- 重点总结:
1.每个slab分配器由多少个页面组成?至少1个,以order为单位,取决于order为多少时,页面容量>slab对象siz,取最小order
2.什么时候分配slab分配器(调用buddy分配页面)?①首先从本地(PerCPU)对象缓冲池(其实就是一个指针数组,指向obj)中分配对象;②本地对象缓冲池没有空闲对象,从共享缓冲池中迁移batchcount个到本地;③如果共享缓冲池也没有空闲对象,从slabs_partial链表和slabs_free链表中找空闲对象,迁移batchcount个到本地对象缓冲池,同时更新slab分配器的管理区(freelists);④如果三大链表也不够了,就需要重新分配一个slab分配器,插入slabs_free链表;
3.关于slab对象回收:①调用kmem_cache_free()释放,当系统中空闲对象太多时,可能会销毁slab分配器(前提是这个slab分配器中的所有对象都没分配出去);②slab注册了一个定时器,定时扫描所有slab描述符,回收空闲对象;③低水位时内存回收线程开始回收
4.关于slab的着色区,是为了让不同slab分配器的相同位置的slab对象不会处于同一个缓存行。
vmalloc()和kmalloc()区别分析
-
老生常谈的区别:①vmalloc()分配不连续的物理内存,kmalloc()分配连续的物理内存;②vmalloc()可分配大块内存,kmalloc()无法分配大块内存(这一点目前来看已经不成立了,128Kb的限制已经是很早之前了。);
-
究其原因,对于kmalloc是因为kmalloc底层基于buddy + slab,小块内存用slab,大块内存用buddy,宏KMALLOC_MAX_CACHE_SIZE(该宏依赖于KMALLOC_SHIFT_HIGH,启用slab此宏不超过32MB,启用slub此宏为两个页面大小,启用slob此宏为一个页面大小)表示使用slab分配的最大内存(嵌入式平台基本上时slub),超过后改用buddy:
1.系统初始化时会创建kmalloc-16,kmalloc-32,kmalloc-64等slab描述符,可用来分配16字节、32字节、64、128等字节(一般最大就是128kb)的内存,其实就是一个个的slab对象,所有物理地址一定连续。
2.太大时使用buddy来分配,最大可分配大小为KMALLOC_MAX_SIZE,通常为2^MAX_ORDER个页面,与buddy的最大order一样。为什么使用buddy物理地址也能连续?因为这里kmalloc调用的buddy函数为alloc_pages(order, flag),分配order大小的内存块,一定连续。
3.同时kmalloc允许传入size=0,会返回一个特殊指针ZERO_SIZE_PTR,同时使用size=0分配的内存,也可以kfree,没啥影响。同时kmalloc对分配的最小内存也有限制,0<size<MIN_SIZE时,分配MIN_SIZE大小的内存。
4.综上所述,使用kmalloc分配内存时,不会你想要多少就给分配多少的,要么是一个slab对象的大小(使用slab时),要么至少页面对齐大小(使用buddy时) -
对于vmalloc()来说,底层是纯纯基于buddy
1.首先在内核内存的vmalloc区域建立一个VMA(内核地址空间因为没有mm_struct,所以有个全局红黑树vmap_area_root来处理所有VMA)
2.计算这个新建的VMA包含多少个页面
3.为每个页面调用alloc_page(),单独申请一页
4.建立页面映射,完成物理页和虚拟页的映射(遍历页表和填充页表)
5.所以可以看到,vmalloc分配的物理内存是不一定连续的,
mm_struct结构体中与内存管理相关的几个变量
这个慢慢整理,遇到哪个成员变量就记录一下成员变量的内容
- 现在先放一下一部分成员变量,碰到什么就添加什么
struct mm_struct {
struct {
struct vm_area_struct *mmap; /* VMA的单链表*/
struct rb_root mm_rb; // VMA的红黑树
...
unsigned long mmap_base; /* 指向mmap空间的起始地址 */
...
pgd_t * pgd; // 指向进程的PGD
...
atomic_t mm_users; // 记录正在使用该进程地址空间的进程数目,如果两个线程共享,那么mm_users = 2
atomic_t mm_count; // mm_struct结构体的主引用计数
int map_count; // 记录分配的VMA的数量
...
struct rw_semaphore mmap_lock;
...
struct list_head mmlist; // 所有的mm_struct都链接在一个双向链表中,链表头是init进程的静态定义的mm结构体init_mm
...
unsigned long total_vm; // 已经使用的进程地址空间总和,单位是页面
...
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK,指向data段对应的VMA */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK,指向可执行代码段的VMA */
unsigned long stack_vm; /* VM_STACK,指向栈段的VMA */
...
unsigned long start_code, end_code, start_data, end_data; // code/data段的起始/结束地址
unsigned long start_brk // 指向堆区的起始地址
unsigned long brk // 指向当前堆区的VMA的结束地址
unsigned long start_stack; // 栈段起始地址
unsigned long arg_start, arg_end, env_start, env_end; // 参数的起始地址?就是创建进程时传入的args这些?
...
};
虚拟内存到物理内存的映射过程整理
- 当TLB未命中时,对于二级页表:在我的手写OS中,首先是页目录表,一个页目录表有1024个页表(需要2^10个索引,占10位),每一个页表有1024个页表项(又需要2 ^10个索引,占10位),页表大小4k,需要2 ^12,所以22 ~ 31是页表索引,12 ~ 21是页表项索引, 0 ~ 11是地址偏移。页目录表由CR3寄存器保存。
- 当TLB未命中时,对于四级页表,也是就arm v8中常用的页表结构:
1.首先根据虚拟地址最高位,判断是内核地址(bit 63 = 0)还是用户地址(bit 63 = 1),内核地址的PGD保存在TTBR1_ELx,用户地址的PGD保存在TTBR0_ELx
2.PGD包含512(2 ^ 9,占9位,索引bit 47:39)个PUD,一个PUD包含512个PMD(2 ^ 9,占9位,bit 38:30),一个PMD包含512个PT(2 ^ 9,占9位,bit 29:21),一个PT包含512个PTE(2 ^ 9,占9位,bit 20:12),然后bit 11 :0就是物理地址偏移了。
3.扩展:这是armv8-A对4KB页的bit分配,armv8-A支持4/16/32KB页。armv8-A支持48位地址线,所以从bit0~bit47
巨页与普通页的区别,应用场景和优劣(待处理)
启用多级页表意义何在
- 多级页表主要是为了节省内存,时间换空间。首先要明确的一点是,进程运行在虚拟地址,要访问物理地址,必须有个全局页表,能完成虚拟地址到物理地址的全部映射
- 有了上面这个概念,就需要知道什么样的页表能完成全局映射。
1.如果启用一级页表,那么一个页表项只映射4KB,一个进程的页表要映射慢4MB的页的话,需要1000个页表项,1000个页表项占内存很多
2.如果启用二级页表,那个全局页表的一个页表项指向一个二级页表,假设一个二级页表的所有页表项能映射1MB空间,那么这个全局页表,只需要4个页表项,就搞定了全部虚拟地址的映射,4个页表项占内存很小。
- 使用多级页表可以使得页表在内存中离散存储,页目录项使用一页保存,页表项使用另外一页保存
- 剩下的就是时间换空间了,二级页表的整个进程地址由页目录表来索引,需要时缺页中断建立某个页目录项对应的的页表就行了。如果使用一级页表,需要直接建立一个4M的页表项来索引整个进程地址空间。
缺页异常机制相关
- 首先要明确,缺页中断是一个异常,是由MMU产生的,然后交给OS来处理(OS来判断这是一个不可修复的错误从而杀死进程;还是这是一个可以处理的错误)。那什么时候MMU会产生该异常?
一是:MMU查找页表,发现物理内存中没有找到该虚拟地址对应的页表项(可能是找不到二级页表、三级页表等等,都有可能),会触发缺页中断;
二是:物理内存中有这个虚拟地址对应的页表项,但是根据页表项的权限位(AP[2]:bit[6]表示EL0可访问/EL0不可访问,bit[7]表示只读/读写权限;XN/PXN:bit[54:53],表示页面可执行;present位,是否在swap中),发现没有权限去执行对应的操作, - 然后,进入缺页中断,走el1_sync()。会有两个关键寄存器:ESR的EC(bit[31:26] 保存异常类型)和ISS(bit[24:0],具体的异常对应的编码,非常集体)保存出现异常的详细信息,FAR保存出现缺页异常的虚拟地址。
- 正式进入操作系统的处理过程,首先就是根据ESR->ISS字段->DFSC字段(bit [5:0])查表,决定执行do_bad还是do_page_fault什么的大部分都会直接kill进程:
static const struct fault_info fault_info[] = {
{ do_bad, SIGKILL, SI_KERNEL, "ttbr address size fault" },
{ do_bad, SIGKILL, SI_KERNEL, "level 1 address size fault" },
{ do_bad, SIGKILL, SI_KERNEL, "level 2 address size fault" },
{ do_bad, SIGKILL, SI_KERNEL, "level 3 address size fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 0 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 1 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 2 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 3 translation fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 8" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 access flag fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 12" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 permission fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 permission fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 permission fault" },
{ do_sea, SIGBUS, BUS_OBJERR, "synchronous external abort" },
{ do_tag_check_fault, SIGSEGV, SEGV_MTESERR, "synchronous tag check fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 18" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 19" },
{ do_sea, SIGKILL, SI_KERNEL, "level 0 (translation table walk)" },
{ do_sea, SIGKILL, SI_KERNEL, "level 1 (translation table walk)" },
{ do_sea, SIGKILL, SI_KERNEL, "level 2 (translation table walk)" },
{ do_sea, SIGKILL, SI_KERNEL, "level 3 (translation table walk)" },
{ do_sea, SIGBUS, BUS_OBJERR, "synchronous parity or ECC error" }, // Reserved when RAS is implemented
{ do_bad, SIGKILL, SI_KERNEL, "unknown 25" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 26" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 27" },
{ do_sea, SIGKILL, SI_KERNEL, "level 0 synchronous parity error (translation table walk)" }, // Reserved when RAS is implemented
{ do_sea, SIGKILL, SI_KERNEL, "level 1 synchronous parity error (translation table walk)" }, // Reserved when RAS is implemented
{ do_sea, SIGKILL, SI_KERNEL, "level 2 synchronous parity error (translation table walk)" }, // Reserved when RAS is implemented
{ do_sea, SIGKILL, SI_KERNEL, "level 3 synchronous parity error (translation table walk)" }, // Reserved when RAS is implemented
{ do_bad, SIGKILL, SI_KERNEL, "unknown 32" },
{ do_alignment_fault, SIGBUS, BUS_ADRALN, "alignment fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 34" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 35" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 36" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 37" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 38" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 39" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 40" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 41" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 42" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 43" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 44" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 45" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 46" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 47" },
{ do_bad, SIGKILL, SI_KERNEL, "TLB conflict abort" },
{ do_bad, SIGKILL, SI_KERNEL, "Unsupported atomic hardware update fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 50" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 51" },
{ do_bad, SIGKILL, SI_KERNEL, "implementation fault (lockdown abort)" },
{ do_bad, SIGBUS, BUS_OBJERR, "implementation fault (unsupported exclusive)" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 54" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 55" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 56" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 57" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 58" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 59" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 60" },
{ do_bad, SIGKILL, SI_KERNEL, "section domain fault" },
{ do_bad, SIGKILL, SI_KERNEL, "page domain fault" },
{ do_bad, SIGKILL, SI_KERNEL, "unknown 63" },
};
- 首先是对VMA进行检查,因为FAR保存着虚拟地址,所以先通过检查VMA,检查内容包括:
- 1.该虚拟地址是不是在一个VMA中(有没有分配VMA)?
- 2.如果在VMA中,权限对不对?
- 过程不是重点,先不整理,将在下一个问题中整理
- 直接跳转到结果:可以处理的异常:匿名页面缺页异常,文件映射缺页异常, SWAP缺页异常(就是页被换到SWAP区了,没有在内存中),写时复制缺页异常。
缺页异常的详细处理过程(待处理)
- 书接上回,我们根据寄存器的信息可以查表得到对应的处理函数,缺页异常的处理函数为do_page_fault(),该函数要处理三种情况:①缺页异常发生在中断上下文/内核线程,说明是内核态缺页异常,跳转到__do_kernel_fault();②出现异常的地址是在用户空间,但是权限问题发生在内核态(本质还是个内核态缺页异常),也就是说,出现了copy_from_user(),或者在内核中用memcopy()这种东西;③用户态缺页异常,调用__do_page_fault();
- 第②点很有意思,单开一个问题。第①点不做过多解释(因为没仔细研究),第③点才是重点,直接放出③的流程图:重点不在于流程,而在于不同缺页异常的具体处理函数。

关于页面回收LRU算法
- 现在内核中有五个LRU链表:
1.不活跃匿名页面链表
2.活跃匿名页面链表
3.不活跃文件映射页面链表
4.活跃文件映射页面链表
5.不可回收页面链表 - 不考虑最后一种,简单讲讲:
1.对于匿名页面,第一次分配匿名页面时会加入到活跃匿名LRU中,知道移动到链表尾部,再转入不活跃匿名LRU中,如果最终移动到了不活跃LRU尾部,则会换入swap区,前提是有swap区,否则kswapd永远不会扫描这两个匿名LRU链表。
2.对于文件页,内核使用经典LRU的加强版:第二次机会法。第一次读取时会加入到不活跃文件页LRU中,因为LRU的宗旨是优先换出(或者叫释放)文件页,因为对于没有脏的文件页,是不需要触发磁盘I/O操作写入磁盘的,直接释放就好了。第二次访问该页面时(依赖于一个标志位PG_refernced),才会换到活跃LRU中。相当于一个文件页的访问次数过滤器。
3.同时对于不活跃匿名页LRU和不活跃文件页LRU,在换出时,都会检查该页面对应页表项PTE的访问bit,只有该位不存在才允许换出去。
4.还是很迷惑,真的是匿名页一套LRU,文件页一套LRU吗?后续有空再看看内核代码 - 从中也可以看到,不管是哪一个LRU链表,链表中的页面一定是已经从buddy中分配出去的页面。而且从buddy中分配页面时一定会同时添加到某一个LRU中。

页面迁移相关
- buddy的链表中是给每种迁移类型的页面都分配了一个order的,比如在ZONE_NORAML的buddy链表中,2^10这个order其实有多个链表,每一种迁移类型都对应一个链表,分配时按需分配,如果需要分配可迁移内存就从可迁移类型对应的链表中分配页面
- 页面迁移的本质就是将页面的内容迁移到新的页面,就是分配一个新页面,将旧页面的内容复制到新页面,然后释放旧页面。能用到的地方一般就是:
1.内存规整,这个为了解决内存碎片化问题
2.内存热插拔,比如我拔了一条内存条,在内存条的设备驱动的热插拔处理函数中会调用驱动实现的迁移方法进行页面迁移
3.NUMA架构,服务器架构,这个就不考虑了,一般用不到。
内存规整(待处理)
匿名页分析
匿名页就是里面存储的数据都是临时数据,在硬盘上没有文件相对应(硬说的话swap也算吧),像什么malloc()这些分配临时内存的都是匿名页。

TLB
- 俗称快表。MMU优先差快表
- TLB不止存放着虚拟地址与物理地址的对应关系,还存放着一些属性:内存类型、cache缓存策略、访问权限,ASID(现在可以通过ASID确定该TLB缓存对应哪个进程,ASID与进程对应,这样再进程切换而切换地址空间时,就不用使内核地址空间TLB也失效,只需要使ASID对应的TLB缓存失效即可)
调度相关
fork/vfork/clone之间的区别分析
- 首先,这三个系统调用,底层都是调用了_do_fork(),区别在于传入的flag不一样。
- 使用**fork()**创建子进程,父子进程有各自独立的进程地址空间(struct mm_struct),但是共享一些资源,包括:
1.进程上下文
2.进程堆栈
3.内存信息
4.打开的文件描述符
5.进程优先级
6.根目录
7.资源限制,也就是rlimts,这个在open系统调用中遇见过
8.也有不一样的:父子进程PID不一样;子进程不会继承内存相关的锁;子进程不会继承信号量;子进程不会继承一些定时器
虽然父子进程有个字独立的进程地址空间,但是页表是一样的。而且页表一样并不是说有一套页表,是有两套页表,页表里面的内容一样(最终指向的物理地址一样)。 - 使用**vfork()**创建子进程与使用fork()差不多,但是有以下几点不一样:
1.调用vfork()的父进程会一直阻塞(基于一个flag:CLONE_VFORK),直到子进程执行exit()退出或者execve()执行新程序。不会像fork那样子进程和父进程返回两次
2.vfork创建的子进程会与父进程执行在同一个地址空间(struct mm_struct)中,这样就不用复制页表了,这应该也是为什么父要阻塞直到子返回(父子不能同时执行,否则会对同一个struct mm_struct进行操作)
3.该函数的使用初衷就是希望子进程立刻执行execve()加载新程序,但是由于加入了写时复制机制,vfork比fork唯一的优势就是不复制mm_struct了 - clone()系统调用用来创建线程,可以传入一个函数执行,fork()传入的参数没有函数地址。
- 不管怎么说,最终都是调用_do_fork(),并且在其中通过copy_process()创建子进程/线程的task_struct
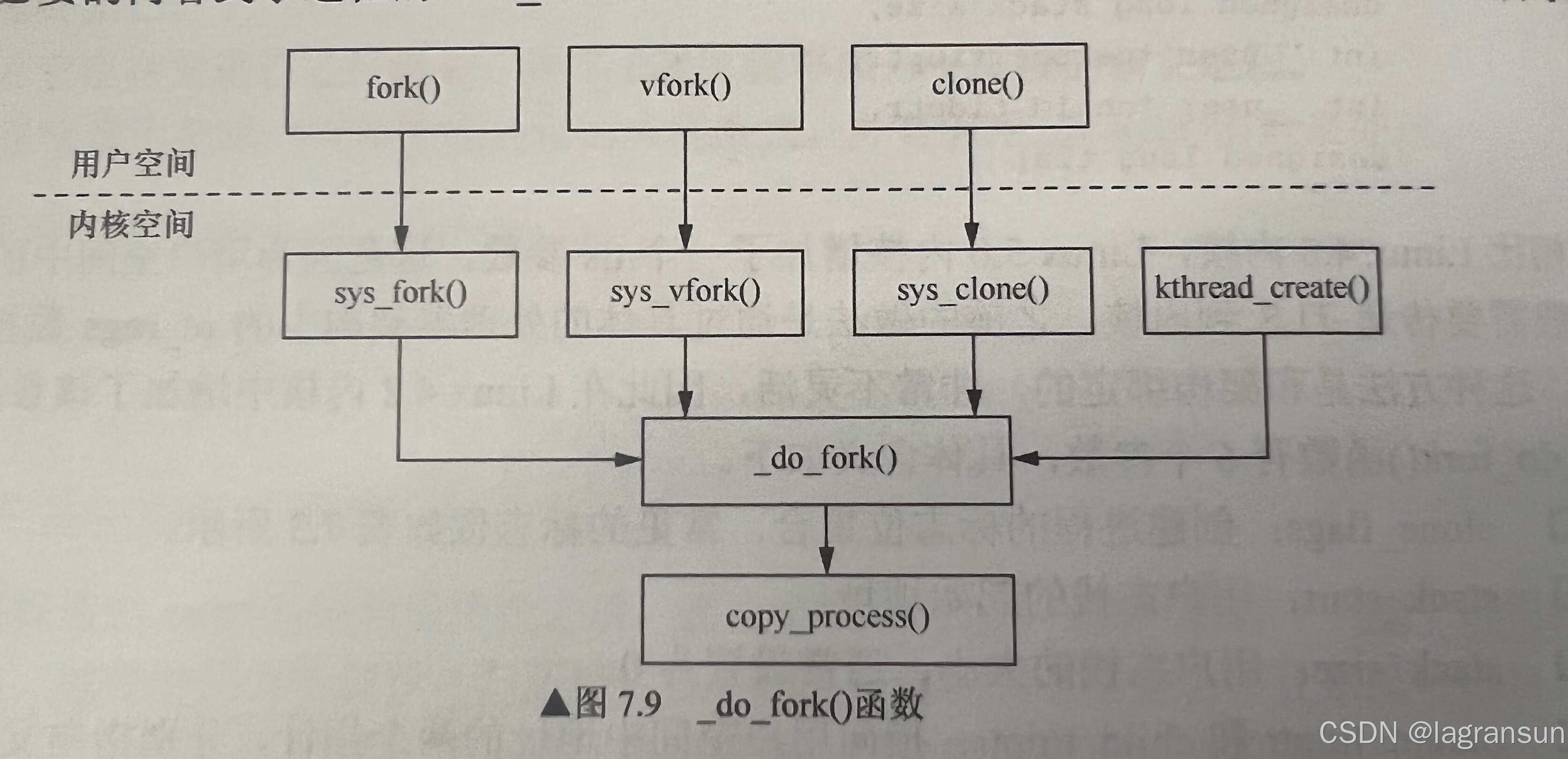
- 但是,在看5.15内核源码的时候,已经不是调用_do_fork()了,而是调用kernel_clone()
fork系统调用的过程
- 先看kernel_clone()整体做了什么工作:

- wake_up_new_task()涉及到调度,暂时先不整理,后续再整理。目前把关注点放在copy_process()上,流程中的关键步骤如下:

1.dup_task_struct():为新进程分配一个进程描述符 + 内核栈(对于ARM64来说,分配16KB大小的连续页面作为内核栈)
①根据系统配置宏CONFIG_VMAP_STACK决定是使用vmalloc(不连续页面)分配还是通过alloc_pages_node(连续页面)分配;
②把父进程的进程描述符的全部内容直接复制到新的子进程的进程描述符中;
③修改子进程task_struct->stack,指向刚分配的内核栈。
2.sched_fork():设置子进程优先级(继承父进程),设置子进程调度类,为子进程选择CPU,调用调度类实现的task_fork()方法。
3.copy_mm():内存相关的关键函数。最开始的三步操作:
①通过current()->mm(父进程)判断是否为NULL,是的话直接退出(此时代表内核进程);
②判断是否有CLONE_VM标志(vfork/clone),有的话直接把子进程task_struct->mm指向current()->mm
③以上都没有,那么就调用dup_mm()
3-1.dup_mm():copy_mm()的关键函数:
①为子进程分配一个mm_struct
②将父进程的mm_strcut直接memcpy到子进程mm_struct
③初始化子进程的mm_struct(修改一些变量,比如清空子进程的VMA链表和红黑树),分配全局页表(子进程mm->pgd)所占用的内存(但是里面啥都没有)
④执行dup_mmap()
3-1-1.dup_mmap():复制页表的关键函数:最重要的工作就是就是遍历父进程所有VMA,下面的工作都是每次循环中所做
①为子进程创建一个对应的新的VMA。
②把新VMA添加到子进程mm->mmap和mm->mm_rb中
③进行父VMA页表/页表项的复制工作,从父VMA拷贝到子VMA,并修改对应的页表项权限。
最后一步的复制工作如下:

进程创建后的返回工作细节(待处理)
上下文切换
- 就是进程切换,需要保存哪些内容?先说一下在我的手搓OS中:会在cur的栈中保存ebp、ebx、edi、esi、和 esp(指向cur的栈)这五个寄存器
对于armv8,过程就是:
context_switch()
->prepare_task_switch()
->membarrier_switch_mm() 对于用户进程,需要切换mm。
->switch_to()
->finish_task_switch(prev) 收尾工作
上下文切换由哪个结构体保存寄存器数据?
- 一般有task_struct中的某个变量来保存,在手搓OS中叫做thread_struct,在内核中也叫thread_struct,task_struct->thread_struct->cpu_contrext(也是个结构体)保存进程上下文寄存器信息。
- struct cpu_context中保存的寄存器包括:X19~X28,FP(栈顶寄存器,指向栈帧的起始),SP,PC(其实就是LR的值,也就是调用switch_to()的位置)
- 这些都是保存在内核栈中的,A进程切换到B进程,那么A进程的现场就要保存在A进程的内核栈中的task_struct中,下次再调度到A时从自己的内核栈中恢复。
- 在armv8中,进程切换的核心函数是context_switch()函数,如果是用户进程,则需要先调用switch_mm()切换地址空间,否则直接调用汇编实现函数switch_to()
linux调度策略整理
- 五种调度类:stop(可抢占任何进程)、deadline(SCHED_DEADLINE)、realtime(SCHED_FIFO;SCHED_RR)、cfs(SCHED_NORMAL,也就是之前的SCHED_OTHER;SHCED_BATCH,;SHCED_IDLE)、idle
- deadline优先级:-1,realtime优先级:0~99,cfs优先级:100-139,对应nice为-20 ~ 99
CFS与负载均衡分析(待处理)
有空再整理,这个内容太多了,对于SMP用的是PELT,目前就整理这个吧
为什么说CFS公平(待处理)
这里应该考虑一下理想域,也就是CFS就绪队列的一个调度周期的长度,慢慢整理
文件系统相关
什么是文件系统
- 文件系统,是一种存储和组织计算机数据的方法。文件系统的实质,就是“存储和组织数据的方法”,文件系统的表现形式,就是“从某个设备中读取数据和向某个设备写入数据
- 我个人认为,文件系统是比较抽象,它不像调度或者内存管理一样。调度或者内存管理完全是内核的功能,由内核来实现,只是需要一些硬件信息即可。但是文件系统可以分为两部分:
1.硬盘上的数据组织方式,我把它算作文件系统的一部分;
2.内核中的文件系统代码,提供可以按照硬盘的数据组织方式操作文件的方法,可以认为是一个硬盘的操作程序,我也把它算法文件系统的一部分,可以叫做逻辑文件系统,通过代码实现文件系统的操作逻辑。 - 对于文件系统的入门,看看小林的博客好一点:一口气搞懂「文件系统」,就靠这 25 张图了
- 总结一下看过的文件系统文章,有些不容易理解的整理一下:
1.Linux下的文件系统,会为每个文件分配两个数据结构:索引节点inode + 目录(与目录项进行区分,目录项是VFS为目录在内存中创建的缓存,这样就不需要频发查询目录,缓存过的目录可以直接查询)。
2.inode + 目录也是要持久化存储的,所以块设备(磁盘、EMMC、SD等)中保存的数据有:超级块的信息 + 所有inode的信息 + 所有目录的信息 + 文件数据
3.实际上硬盘中会持久化存储这些:其实目录就是一个inode,只不过inode里面会有flag来标志这个inode是表示目录,还是表示文件,不同类型的inode里面的属性不一样。所以说有的文章说磁盘中只有inode,有的文章说磁盘中即有inode也有目录,后者的说法应该是认为inode只是文件索引。

4.已知:文件inode需要通过目录inode进行索引,而且目录inode它也是个inode,那怎么索引目录inode?这不死循环了吗?解决办法就是把根目录的目录inode限制死,限制在磁盘的某个位置限制死就OK了,每次从根目录开始检索(所以每次索引都很慢,就体现出了VFS的目录项dentry缓存的重要性)。
5.那怎么知道根目录呢?需要找到超级块,以ext2文件系统为例:至于为什么超级块中有这些信息(inode位图,inode数组等),分区表1中还保存了一份这些信息,是为了出问题的时候能恢复,相当于有个备份


6.inode和superblock在磁盘中,总不能一直读磁盘吧?所以内核中有对应的结构体来存储inode和superblock的信息,文件系统挂载时,在内存中缓存superblock。访问文件时,在内存中缓存inode。这也说明了,操作系统社区和文件系统厂商要互相配合,linux社区规定了要有superblock和inode,文件系统实现时就必须有这个。
7…不同的文件系统会提供不同的文件组织方式(就是对于一个文件,它占用的很多块以什么方式组织起来,是需要连续的块来存储,还是可以使用不连续的块来存储等等?对于不连续块这样的存储方式,inode中该如何对其进行索引?) - 一点扩展:在open()等文件相关的系统调用内核源码中,经常能看见哈希表。其实Linux系统的ext文件系统就是采用了哈希表,来保存目录的内容。因为如果一个目录下有很多个文件或文件夹,从头遍历到尾来比较文件/文件夹名,太慢了。以文件名作为索引创建哈希值,后面再根据文件名查起来就会快一点(只限于第一次查找,第一次查找之后就有VFS缓存dentry了):

不同文件系统的区别分析
随时补充
- 早期来说,就是FAT文件系统,FAT 表通过一种类似链表的结构描述了文件对应的块(或者说串起了所有的块),这时候还没有inode,后来inode使用数组的方式来描述,时间复杂度就小很多了,只不过要在磁盘中拿出一部分空间存储inode
- inode 解决了 FAT 容量限制问题,但是随着 CPU、内存、传输线路的速度越来越快,对磁盘读写性能的要求也越来越高。所以不应该每次读写都直接写入,而应该先缓存,缓存到一定级别再写入。但是这样引入了一个问题啊,就是通过对写入数据进行缓存,如果缓存了一些数据,但是在将缓存的数据写入硬盘时出错了,可能会造成一些灾难性问题。
- 于是引入了日志文件系统,什么是日志文件系统?从ext3开始支持日志文件系统,现在很多linux发行版或者服务器linux默认ext4
什么是日志文件系统
参考一篇文章:日志型文件系统 - 原理和优化
总结一下这篇文章:
- 传统的文件系统,当出现系统crash或突然断电时,可能会出现元数据(inode等索引文件的数据)与文件数据不一致的情况。
1.更新一个文件时(比如要在某个文件后面再写一些数据),要更新的内容有:inode对应的block,inode bitmap对应的block,data对应的block(文件数据对应的block),data bitmap对应的block。

2.因为是对磁盘的三个位置进行修改(inode、inode bitmap、文件位于硬盘的不同位置),而磁盘读写是按块来读写的,而且地址是连续的。所以大概率是发起三次修改。
3.如果只修改了其中一个或者两个之后断电了,或者操作系统寄了没法,总之就是没法再发起一次磁盘写入,那么元数据与数据就不一致了。 - 那怎么保证元数据与数据的一致性呢?就有了日志文件系统,日志文件系统先将要修改的内容,记录在磁盘中。对于extX系列的文件系统,会划出一部分磁盘空间作为日志区(journal),当要修改磁盘时,先把要修改的东西记录在journal中。这里我把写入journal中内容理解为修改规则。通过分析这个修改规则,可以知道要修改磁盘的哪些内容,起到了指示作用。

- 其中一条规则就是下面这样:
1.要更新的就是:磁盘上的inode(I[v2]), bitmap(B[v2])和data block (Db),先把规则写入到journal区,这么一条规则称为一个transcation。
2.TxB,TxE则作为flag用来表示一个transcation的开始和结束。
3.同时为了防止先写TxE才写入Db,还插入了barrier,保证TxE是最后写入的。这样当TxE存在时,一定能保证这个transcation是完整的。

- 那这样怎么就能保证元数据和文件数据的一致性了呢?这一点这篇知乎文章一笔带过,没详细说明。看了下其他文章,其实很简单,就是在日志文件系统中,写操作变成了:
1.写入日志
2.按日志的规则真正的写入磁盘
3.删除日志
这样的话,如果日志没删除,就说明我可能断电了或者怎么着,反正没有成功进行一次完整的文件更新(更新inode数据、bitmap数据、文件数据),我仍然可以从日志中恢复,再来一次。 - 但是发现没,磁盘I/O本来就慢,现在还要写两遍,更慢。所以会有一些优化工作可以做,看下全志的开发手册是怎么说的:

这个优化工作这篇知乎文章是有说的,回头再看看吧。
磁盘I/O相关
页高速缓存机制
放出一张图,该图在本文的radix tree下放出来过:

总结一下:
- 首先确认页高速缓存的缓存内容:正常文件、块设备文件、内存映射文件。在执行一个I/O操作(read/write)之前,内核首先检查要操作的数据是否已经已经被缓存到页高速缓存中了,如果数据已经被缓存,则直接从高速缓存中读数据,不必开启一次磁盘I/O。如果没有被缓存到内存中,则首先需要将其缓存到内存中(根据时间/空间局部性原理,刚刚使用的数据以及附近数据在接下来有更大概率会被使用)。
- 页缓存的维护,基于一个结构体struct address_space。从上图中也可以看出,每一个inode都对应一个struct address_space,所以每个文件(每个inode)都有页缓存。但是并不是每个struct address_space都会与一个文件关联,也可能与一些特殊机制关联,比如swapper区。
- 每个address_space,都有一套自己的操作集,用来为页缓存进行I/O操作。以真实的文件inode为例,对应的如ext4等文件系统
页回写机制
页回写就是通过flusher内核线程进行回写
- 空闲内存低于某个阈值
内核驱动相关
要实现一个驱动,应该思考要做些什么(随时补充)
从流程来看:
- 对于.ko模块化的驱动来说,应该做到:
1.实现module_init()和module_exit()函数
2.在module_init()函数中实现对驱动的初始化。
2.1 如果是非总线设备,则需要:
①创建字符设备操作集
②创建设备号,注册字符设备(此处绑定操作集),添加字符设备
③注册设备类
④注册设备(device_create)
2.2 如果是总线设备,则需要:
①创建struct of_device_id匹配表。
②编写probe和remove函数,在probe()函数中实现驱动/设备初始化操作。可能会用到总线设备的注册api,这些api往往会完成2.1 提到的几点。
①创建driver结构体(根据总线类型创建struct platform_driver、struct i2c_driver等等),绑定匹配表、probe、remove等
③在module_init()函数中使用platform_driver_register()/i2c_add_driver()等api注册驱动。
3.
3.1 对于register_chrdev我们注册了file_operations结构体之后,device_create(fb_class, fb_info->device, MKDEV(FB_MAJOR, i), NULL, "fb%d", i)的时候这些设备的主设备号相同,次设备号不同,它们在同一类下面。
3.2 尽管可以执行open("/dev/fb0", O_RDWR),open("/dev/fb1", O_RDWR)但它们其实执行的是同一个open函数,即register_chrdev注册的fops
3.3 所以可以实现一类设备的驱动,写好通用的file_operations,当执行open时,根据次设备号得到一个和/dev/fb0相关的结构体,执行里面的open函数。
3.4 在这个通用的程序里面register_chrdev然后使用class_create()创建类,在实例化设备下创建设备device_create就可以了,这些实例化设备都在相同的类下面创建。所以有/dev/fb0, /dev/fb1, 同样有/sys/class/fb/fb0和/sys/class/fb/fb1。
3.5 register_chrdev这个类下面255个设备的fops都一样,如果将register_chrdev分三步来注册,在alloc_chrdev_region/register_chrdev_region里面可以指定fops被哪些次设备号共享。
4.使用obj-m编译模块
- 对于加载进内核的驱动来看
1.使用module_platform_driver(xx_driver)等函数,最终展开仍然是这种形式:
static int __init xxx_driver_init(void)
{
return platform_driver_register(&(xxx_driver));
}
module_init(xxx_driver_init);
2.在module_init()函数中实现对驱动的初始化,与ko一样
3.编译不同,需要修改Makefile文件,添加obj-$(CONFIG_XX) += test.o,也可能会修改到driver的makefile文件。如果要使能图形界面的话还需要修改Kconfig文件
- 都需要是针对GPL协议使用一些宏,包括:
1.EXPORT_SYMBOL_GPL(symbol):此宏相当于export该symbol,其他模块或者文件可以引用
2.MODULE一族:
2.1 MODULE_DESCRIPTION("xxx"):添加描述信息,可以添加可以不添加
2.2 MODULE_AUTHOR("xxx"):添加作者信息,可以添加可以不添加
2.3 MODULE_LICENSE("GPL"):添加模块 LICENSE 信息,必须添加,否则编译会报错
2.4 MODULE_PARM(varname,type, perm):insmod时可以传递参数
2.5 MODULE_DEVICE_TABLE(type,name):和热插拔相关的,往往需要对type_device_id的表使用这个宏
3.
关于MODULE_PARAM: linux驱动开发中常用函数–module_param()的用法
从驱动内容来看:
- 对于大部分驱动:
1.需要在probe中完成整体初始化。
2.往往需要在probe中进行设备树的解析工作,所以设备树是设备驱动的映射,需要通过of函数解析设备树。一般是通过of函数对设备树生成的struct deivce_node进行解析。
3.然后就看驱动者的设计模式了,可以使用从设备树中解析出的信息在这里对这个设备进行初始化,包括使能/失能设备寄存器,修改GPIO输出,分配IO内存等等。
关于device_create()和cdev_register()的一些思考
class_create()/device_create()主要做的作用在我看来就是:①通知mdev/udev去/dev/下注册设备;②调用sysfs的api向sysfs下添加调试节点。如果添加的调试节点够多,没准也不需要file_ops(也就是说不需要ioctl,open,read这些),这也是为什么内核建议可以使用这两个函数代替cdev相关
关于cdev:主要作用就是能够绑定file_ops,提供open、read等函数,并且每个主设备号相同的设备使用同一套file_ops。device_create()要传入cdev注册时使用的主/次设备号。
设备树节点都表示什么信息?一些特殊属性的作用?(待处理)
- 一般一个节点需要包含以下标准属性,使用双引号的一般是字符串类型属性,使用尖括号的一般是u32类型属性:
i2c1: i2c@021a0000 { // label:node-name@unit-address, 前面是label,后面是节点名,然后是寄存器首地址。
model="xxx" // 标准属性,描述设备模块信息,比如名字,但是这个节点没使用
#address-cells = <1>; // 标准属性:无符号32位整形,可以用在任何有子节点的设备中,决定了子节点reg属性中地址信息所占的字长。
#size-cells = <0>; // 标准属性:同上,决定子节点reg属性中length信息所占的字长
compatible = "fsl,imx6ul-i2c", "fsl,imx21-i2c"; // 标准属性
reg = <0x021a0000 0x4000>; // 标准属性:i2c1的父节点的address-cells一定为1,size-cell一定为1,表示寄存器起始地址信息(addr),寄存器地址长度(length)
ranges; // 标准属性:在这个i2c节点下没有,有的有,可以为空
interrupts = <GIC_SPI 36 IRQ_TYPE_LEVEL_HIGH>; // 可能是厂商自定义属性
clocks = <&clks IMX6UL_CLK_I2C1>; // 时钟信息,不知道是否为标准属性
clock-names = "xxx" // 时钟属性
status = "disabled"; // 标准属性:后面的值也是固定的,只有几个可填
};
还有一些其他标准属性,像:
#gpio-cells = <2>
- 特殊属性就不说了,很多厂商自定义属性,然后厂商在驱动中自定义解析方法。
- 设备树中常用的一些节点有:
①aliases节点
②chosen节点
③memory节点
④cpus节点
⑤clocks节点
⑥GIC节点
⑦soc节点,这个节点里面使用很多子节点表示片上资源,包括sdram,i2c适配器,spi适配器,pmu,uart,can等等。
/ {
// 特殊节点
aliases {
can0 = &flexcan1;
gpio0 = &gpio1;
...
};
// 特殊节点chosen,uboot会在启动最后阶段把bootargs添加到这个节点中
chosen {
stdout-path = &uart1;
};
// 内存节点,与上面那个chosen节点一样,是kernel启动时早期解析设备数时会解析这俩节点。
// 0x20000000 = 2 * 2^28 = 2 ^ 29 = 2^9 * 1MB = 512M,所以内存512M
memory {
reg = <0x80000000 0x20000000>;
};
// cpu节点
cpus {
#address-cells = <1>;
#size-cells = <0>;
cpu0: cpu@0 {
compatible = "arm,cortex-a7";
device_type = "cpu";
reg = <0>;
...
};
};
// 中断控制器GIC
intc: interrupt-controller@00a01000 {
compatible = "arm,cortex-a7-gic";
...
};
// 时钟节点
clocks {
#address-cells = <1>;
#size-cells = <0>;
ckil: clock@0 {
compatible = "fixed-clock";
reg = <0>;
#clock-cells = <0>;
clock-frequency = <32768>;
clock-output-names = "ckil";
};
...
};
// soc节点
soc {
...
...
pmu {
compatible = "arm,cortex-a7-pmu";
interrupts = <GIC_SPI 94 IRQ_TYPE_LEVEL_HIGH>;
status = "disabled";
};
ocrams: sram@00900000 {
compatible = "fsl,lpm-sram";
reg = <0x00900000 0x4000>;
};
ocrams_ddr: sram@00904000 {
compatible = "fsl,ddr-lpm-sram";
reg = <0x00904000 0x1000>;
};
ocram: sram@00905000 {
compatible = "mmio-sram";
reg = <0x00905000 0x1B000>;
};
dma_apbh: dma-apbh@01804000 {
};
aips1: aips-bus@02000000 {
spba-bus@02000000 {
ecspi1: ecspi@02008000 {
...
};
...
...
uart7: serial@02018000 {
...
};
...
};
flexcan1: can@02090000 {
...
};
gpio1: gpio@0209c000 {
compatible = "fsl,imx6ul-gpio", "fsl,imx35-gpio";
...
};
usbphy1: usbphy@020c9000 {
...
};
gpc: gpc@020dc000 {
...
};
iomuxc: iomuxc@020e0000 {
compatible = "fsl,imx6ul-iomuxc";
reg = <0x020e0000 0x4000>;
};
};
aips2: aips-bus@02100000 {
i2c1: i2c@021a0000 {
};
lcdif: lcdif@021c8000 {
};
};
aips3: aips-bus@02200000 {
};
};
};
如何编写Pinctrl的设备树信息以及驱动程序
首先要知道原厂(imx6ull)写的pinctrl子系统做了什么,也就是iomuxc这个设备树节点的probe函数:
①获取设备树中的pin信息
②根据获取到的pin信息来设置pin的复用功能
③根据获取到的pin信息来设置pin的电器特性,如上/下拉、速度、驱动能力等
④调用pinctrl_register()函数向Linux内核注册该pinctrl
⑤重复①~④,知道初始化完iomuxc下的所有pinctrl
所以我们要做的是什么呢?我们要做的就是:
①在iomuxc这个设备树节点下,添加上我们要修改的pin节点,并填入对应的信息,一定要使用"fsl,pins",原厂驱动需要这个属性名
②在设备节点中引用刚添加好的pinctrl节点
③正常的设备驱动中我们不需要用到pinctrl子系统的api,没见过有用的
/ {
beep {
...
pinctrl-0 = <&pinctrl_beep>
// gpio属性值一共有三个,“&gpio1”表示引脚所使用的IO属于GPIO1组,“19”第19号IO,所以使用了GPIO5_1
// “GPIO_ACTIVE_LOW”表示低电平有效,如果改为“GPIO_ACTIVE_HIGH”就表示高电平有效。
gpio = <&gpio5 1 GPIO_ACTIVE_LOW>;
...
}
...
...
iomuxc {
...
....
// 添加新的pin节点,然后iomuxc的probe函数会帮我们解析这些信息并配置的。
pinctrl_beep: beepgrp {
fsl,pins = <
MX6ULL_PAD_SNVS_TAMPER1__GPIO5_IO01
0x10B0 /* beep */
>;
};
...
...
}
}
如何编写Gpio的设备树信息以及驱动程序
这个跟probe差不多,思路差不多,也是由原厂的probe函数来解析设备树信息,初始化GPIO配置,但是不同的是:
①pinctrl只有一个节点,就是iomuxc节点,但是gpio有很多个,gpio1~5控制器每一个都是一个节点。
②pinctrl不会提供api函数,但是gpio子系统会提供api函数,让我们方便的控制gpio,同时gpiolib库还为gpio提供了一些gpio专用的函数,这个函数最终也是根据gpio号找到gpio_desc,然后调用该desc指向的struct gpio_chip中实现的函数。所以在GPIO驱动中,我们要为每一组gpio初始化一个struct gpio_chip
③初始化过程中会闭 GPIO1 所有 IO 中断,并且清除状态寄存器。
④会初始化一个struct gpio_chip数据结构,里面有很多方法要原厂自己去实现,那些of函数也会用到
所以我们要做的是什么呢?:
①设备树中的修改与pinctrl子系统一样
②正常的设备驱动程序中,我们是需要用到gpio子系统提供的api函数的:
gpio = of_get_named_gpio(struct device_node *np, const char* propname, int index) // 通过of获取到对应的gpio信息
gpio_request(gpio, "name") // 后面的name就是给gpio设置个名字
gpio_get_value(gpio, 0/1) // 设置gpio输出电平
gpio_free(gpio) // 释放gpio
如何编写中断的设备树信息以及驱动
关于中断,我有个更详细的博客以regmap为例介绍了中断的过程:Linux字符设备驱动 – regmap子系统
设备树信息就编写如下:
interrupt-parent = <&gpio1>;
interrupts = <18 IRQ_TYPE_EDGE_BOTH>;
status = "okay";
驱动中使用:
gpio_to_irq() // 通过gpio号获取到virq
request_irq() // 为这个virq申请中断
如何编写i2c adpater的驱动
简要写一下:
①获取设备树信息
②初始化i2c控制器相关的物理寄存器,基本上在这一步完成裸机i2c的流程
③初始化adapter成员变量,最重要的是初始化i2c_adapter->algo,信号传输都靠他了
④使用i2c_add_numbered_adapter()函数向内核注册i2c_adapter,同时该函数会解析设备树,将i2c设备节点转化为struct i2c_device。
裸机i2c大致就是:
① 使能i2c时钟
②初始化总线参数,如通信频率、I2C模式、ACK自动、地址bit数等等
③如果使用中断模式,开中断,非中断模式下是通过检测ACK信号来判断从设备响应了,在中断模式下是通过中断信号来判断从设备响应了,一般是读主CPU侧的iic控制器的中断标志来判断的,master发送slave地址后接收到ACK信号然后产生中断,slave 接收到的数据是自己的地址时会产生中断。
④如果使用DMA,做DMA相关设置
⑤使能I2C
如何编写spi adapter的驱动
基本与i2c套路类似。
中断下半部的三种方法
什么时候使用下半部,有三个建议:
①要处理的内容不希望被其他中断打断,可以放到上半部
②要处理的任务对时间敏感,可以放到上半部
③要处理的任务与硬件相关,可以放到上半部
④其他情况下优先考虑放到下半部
如何使用下半部?
- 软中断:
1.首先需要静态定义一个软中断号,需要保存在softirq_vec[NR_SOFTIRQS]数组中,默认最多32个软中断
2.在某个位置动态调用open_softirq(软中断号,软中断函数),注册软中断
3.在中断处理函数(上半部)中调用raise_softirq(软中断号);并且可以在软中断处理函数中再次触发这个软中断!!
4.等待合适的时机执行:①从硬件中断代码返回时(此时已经回到了进程上下文);②在ksoftirqd内核线程运行时;③显式的检查和处理软中断的代码中;执行软中断时会关闭本地中断,因为在清空软中断bitmap时不希望有新的软中断被唤醒,可能误清除。 - tasklet
1.使用宏一次性静态声明:DECLARE_TASKLET(name, func, data),会生成一个struct tasklet_struct name;
2.也可以动态声明tasklet_init(t, tasklet_handler,dev)
2.在上半部中调用tasklet_schedule(&name)
2.调度时机与软中断一样,因为本身就是软中断的一种 - 关于ksoftirqd内核线程
1.percpu线程,每一个线程一个,主要作用就是为了防止某一时间段内软中断大量重复触发(指在某个软中断处理函数中再次触发本软中断),使用户线程饥饿。
2.被再次触发的软中断,会交给ksoftirqd来处理。该内核线程设置的优先级nice值是19,该线程做的工作也就是调用do_softirq() - linux的中断下半部softirq和tasklet有什么区别
同类型的softirq可以多cpu同时执行多个,这样可能会带来一些竞争。但是两个相同类型的tasklet不能同时执行,即使属于不同的CPU也不可以同时执行。因为在执行tasklet时会检查一个标志位TASKLET_STATE_RUN,判断这个类型的tasklet是否正在执行。
常用的中断相关的函数:
// 下面这个四个函数既可以在中断中使用,也可以在进程上下文中使用,跟硬件CPU有关
local_irq_disable()/local_irq_enable(),关闭/打开本地CPU中断
local_irq_save(flags)/local_irq_store(flags),保存并关闭/恢复本地CPU中断
// 下面这四个函数针对软件中断处理函数,可以认为从软件上屏蔽了某个中断
disable_irq(uint irq)/enable_irq(uint irq),关闭/打开某个中断线(其实就是某个中断号对应的中断处理函数),当前正在执行的所有中断处理程序完成,disable_irq才会返回
disable_irq_nosync(uint irq),不会等待这个中断处理函数结束。
synchronize_irq(uint irq),等待一个特定的中断处理函数执行完成。
// 判断一些flag
in_interrupt(),如果在中断上下文中,返回非0,在进程上下文中返回0
in_irq(),如果当前正在执行中断处理程序,返回非0,否则返回0
// 关于下半部
local_bh_disable(),禁止本地CPU的软中断和tasklet的处理
local_bh_enable(),激活本地处理器的软中断和tasklet的处理
// 关于下半部能使用的一些锁:
spin_lock()/spin_unlock(),获取锁
spin_lock_irq()/spin_unlock_irq(),禁止本地中断并获取锁
spin_lock_irqsave()/spin_unlock_irqstore(),保存本地中断的当前主管那台,然后禁止,然后获取锁
设备树根结点会不会被解析成一个节点?
会,会解析成一个节点。也就是第一个节点。
设备树编译过程,在内核中的加载与解析过
- 关于编译设备树,内核中有个dtc工具可以编译设备树,可以将设备树编译到内核中,也可以将设备树编译成一个单独的文件dts(二进制文件)。如果编译到内核中,则每次修改内容都要重新烧录和编译内核,非常麻烦。
- 关于加载设备树,如果使用的bootloader是uboot,对于armv7来说,会使用r2寄存器把uboot在内存中的地址(要么从emmc中读到内存,要么通过tftp从网络下载到内存)传给kernel。对于armv8来说,会使用x0寄存器把地址传给kernel。
- 解析过程如下:
stext()
->...
->start_kernel()
->setup_arch()
->setup_machine_fdt() // 解析dtb数据,得到匹配的struct machine_desc结构体(machine_desc有个dt_compat属性,设备树的根节点有个compatible属性,二者根据这个进行匹配),这个struct machine_desc是用来描述板级资源配置的。
->early_init_dt_scan_nodes // 茨贝格dtb数据中先解析一些关键节点(重要物理设备信息如memory内存节点,choosen参数节点),引导内核启动
->unflatten_device_tree() // 将dtb的节点解析成struct device_node结构体,根节点保存到of_root变量
->...
->arch_call_rest_init() // 是statr_kernel的最后一个函数了
->rest_init()
->kernel_init()
->kernel_init_freeable()
->do_basic_setup()
->do_initcalls() // 执行各种被连接到.init段的函数
->of_platform_default_populate_init() // 将struct device_node结构体转换为总线上的device,各种platform_device,生成设备的时候肯定会执行driver匹配过程的(如果driver是被编入了内核,而不是通过ko加载)。
对于device_node转换为platform_device,不是所有的都可以转换,根据这篇博客 – device_node转换为platform_device提到的,只有满足下面三个条件之一,才会转换:
- 该节点必须含有compatible属性
- 根节点的子节点(节点必须含有compatible属性)
- 含有特殊compatible属性的节点的子节点(子节点必须含有compatible属性):“simple-bus”,“simple-mfd”,“isa”,“arm,amba-bus”
所以此时不会出现i2c_device和spi_device,生成i2c_device和spi_device的工作是在i2c_adapter的probe函数中,调用i2c_new_device()进行注册的,参考这篇博客 – 3.5内核对设备树的处理——device_node转换为platform_device:
/i2c节点一般表示i2c控制器, 它会被转换为platform_device, 在内核中有对应的platform_driver;
platform_driver的probe函数中会调用i2c_add_numbered_adapter:
i2c_add_numbered_adapter // drivers/i2c/i2c-core-base.c
__i2c_add_numbered_adapter
i2c_register_adapter
of_i2c_register_devices(adap); // drivers/i2c/i2c-core-of.c
for_each_available_child_of_node(bus, node) {
client = of_i2c_register_device(adap, node);
client = i2c_new_device(adap, &info); // 设备树中的i2c子节点被转换为i2c_client
}
这一点从i2c_adapter的probe函数中也可以看出来,probe函数传入的是platform_device,但是i2c外设的probe传入的是i2c_device:
static int i2c_imx_probe(struct platform_device *pdev)
- struct machine_desc具体有啥,后续再研究研究,内核移植跟这个关系也挺大的
关于GPIO编号问题?(待处理)
这里可能后续需要研究一下GPIO子系统。
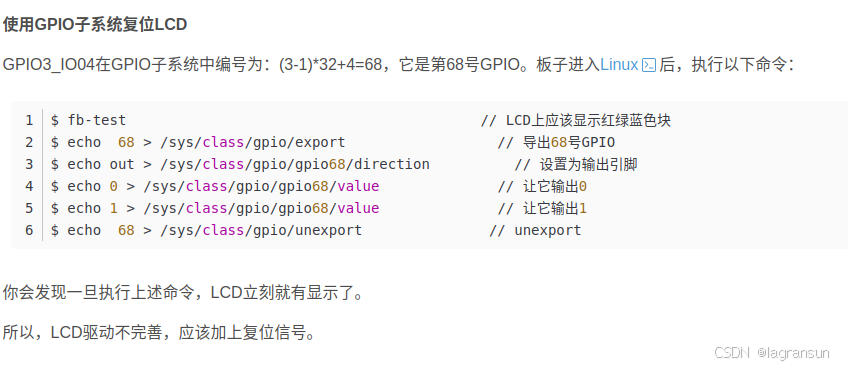
而且在内核中找到一个函数:gpio_direction_input(unsigned gpio),里面会调用一个函数gpio_to_desc(gpio),看来跟virq一样,额每个gpio也对应一个struct gpio_desc啊。
关于uboot的设备树?(待处理)
为什么copy_from_user()/copy_to_user()更加安全
-
如果从用户空间copy数据到内核空间,用户空间地址to及to加上copy的字节长度n必须位于用户空间地址空间
-
如果我们想研究地更深,硬件和软件协同做了一个更加安全的机制,这个机制叫做PAN (Privileged Access Never) 。它可以把内核对用户空间的buffer访问限制在特定的代码区间里面。PAN可以阻止kernel直接访问用户,它要求访问之前,必须在硬件上开启访问权限。根据ARM的spec文档,内核每次访问用户之前,需要修改PSATE寄存器开启访问权限,完事后应该再次修改PSTATE,关闭内核对用户的访问权限(基于配置项CONFIG_ARM64_PAN)。
-
当进程切换到内核态(中断,异常,系统调用等)后,如何才能避免内核态访问用户态地址空间呢?其实不难想出,改变ttbr0_el1的值即可,指向一段非法的映射即可。因此,我们为此准备了一份特殊的页表,该页表大小4k内存,其值全是0。当进程切换到内核态后,修改ttbr0_el1的值为该页表的地址即可保证访问用户空间地址是非法访问。特殊页表的内存通过链接脚本分配,和内核页表在内存中紧挨着。
-
进入内核态后会通过__uaccess_ttbr0_disable切换ttbr0_el1以关闭用户空间地址访问,在需要访问的时候通过__uaccess_ttbr0_enable打开用户空间地址访问。这俩函数的作用就是修改ttbr0_el1,前者使其指向特殊页表,后者恢复。
-
在全志平台上,CONFIG_ARM64_PAN是开启的。
-
看一下这篇文章的后半段:Linux为什么一定要copy_from_user ?,后半段说明了,为什么memcpy()出错后内核会oops或者panic,但是copy_from_user()出错后不会内核panic,原因就是对于copy_from_user()而言,有个单独维护的地址异常表。这种修复异常并不是建立地址映射关系,而是修改do_page_fault()返回地址。
-
驱动文件静态编译和动态编译的区别是什么?insmod之后发生了什么?
-
静态加载时,会编译进内核的initcall段,在kernel启动时执行。动态加载,也就是ko的模式,通过insmod动态加载重定位到内核。这两种方式可以在Makefile中通过obj-y或obj-m选项进行选择。好文分析:module_init 底层实现原理
#ifndef MODULE
···
//静态加载
#define module_init(x) __initcall(x);
#define module_exit(x) __exitcall(x);
···
#else /* MODULE */
···
//动态加载
#define module_init(initfn) \
static inline initcall_t __inittest(void) \
{ return initfn; } \
int init_module(void) __attribute__((alias(#initfn)));
#define module_exit(exitfn) \
static inline exitcall_t __exittest(void) \
{ return exitfn; } \
void cleanup_module(void) __attribute__((alias(#exitfn)));
···
#endif
- 是怎么动态加载的呢,对引用的文章进行总结一下就是:
1.驱动程序都会包含 “linux/init.h” 头文件,该头文件中定义了 “module_init” 这个宏,如果我们定义了MODULE这个宏,module_init就会启用动态加载,会通过 alias 对函数指针起别名为 init_module。这里的函数指针就是module_init(fn),我们自己写的fn。注意,这一步之后,通过init_module即可索引fn。
2.编译ko文件时,会生成 xxx_mod.c 文件,init_module 会被传入 xxx_mod.c ,被 this_module 结构体使用
3.this_module结构体会被链接到ko文件中,进而内核在加载ko文件时可以解析 this_module 结构体,得到驱动入口函数等。此过程通过系统调用sys_init_module实现
4.怎么区分是动态还是静态?就是根据宏MODULE,如果是编译动态module,GCC编译时会加入-DMODULE参数(GCC的-D选项用于在编译时定义宏)。 - 那insmod是如何加载.ko模块的呢?
1.首先 insmod 会通过文件系统将 .ko 模块读到用户空间的一块内存中,然后执行系统调用sys_init_module() 解析模组,
2.这时,内核在 vmalloc 区分配与 ko 文件大小相同的内存来暂存ko 文件
3.暂存好之后解析 ko 文件将文件中的各个section 分配到 init 段和 core 段,在 modules 区为 init段(就是module_init这个函数入口所在的段)和 core 段分配内存,并把对应的section 复制到 modules 区最终的运行地址
4.经过 relocate函数地址等操作后,就可以执行ko的init操作了,这样一个 ko 的加载流程就结束了。同时,init段会被释放掉,仅留下core段来运行。
USB驱动热插拔相关
- 内核的处理看这个:Linux–USB驱动开发(二)插入USB后的内核执行程序;物理设备原理看这个:USB 枚举/断开过程
- 总结一下就是:
①USB控制器,可以检测到控制上的电平变换(插入/删除),USB集线器通过中断IN通道,向主机报告有USB设备连接。
②这样主机就通过中断机制知道了有新的设备插入,操作系统加载合适的驱动程序。通过uevent机制通知udev/mdev加载对应的设备
③移除时同理。
关于linux 驱动模型中的uevent机制
- 这篇文章讲了uevent机制的原理,应该是韦东山的:嵌入式Linux——uevent机制:uevent原理分析
- 但是需要对这篇文章进行一下更正,可能作者用的内核版本比较早。在kobject_uevent_env()这个函数中,是否可以使用uevetn helper机制(mdev采用的机制),取决于一个宏CONFIG_UEVENT_HELPER,以下是我使用的linux 4.19内核中的实现:
int kobject_uevent_env(struct kobject *kobj, enum kobject_action action,
char *envp_ext[])
{
...
...
#ifdef CONFIG_UEVENT_HELPER
/* call uevent_helper, usually only enabled during early boot */
if (uevent_helper[0] && !kobj_usermode_filter(kobj)) {
struct subprocess_info *info;
retval = add_uevent_var(env, "HOME=/");
if (retval)
goto exit;
retval = add_uevent_var(env,
"PATH=/sbin:/bin:/usr/sbin:/usr/bin");
if (retval)
goto exit;
retval = init_uevent_argv(env, subsystem);
if (retval)
goto exit;
retval = -ENOMEM;
info = call_usermodehelper_setup(env->argv[0], env->argv,
env->envp, GFP_KERNEL,
NULL, cleanup_uevent_env, env);
if (info) {
retval = call_usermodehelper_exec(info, UMH_NO_WAIT);
env = NULL; /* freed by cleanup_uevent_env */
}
}
#endif
...
...
}
关于mdev/udev,它们的工作原理是什么,有什么区别?
一般ubuntu是udev,嵌入式linux如果用busybox构建根文件系统的话,一般是mdev,我的ubuntu就是udev:

d结尾的进程一般是守护进程 – Linux系统编程(守护进程)
- udev/mdev区别:linux内核之mdev机制和udev机制的区别,守护进程,简单理解为一个脱离控制的进程就行了,会周期的去执行一些操作。一些服务都以守护进程的形式存在,一般系统启动后接着创建,直到关机。


关于netlink机制
- 参考:linux中netlink机制的实例讲解
- 总结一下就是:
1.netlink是一种异步机制,内核和用户态应用之间传递的信息保存在socket的缓存队列中,发送者发送到队列中即可,不需要等待接受者接受
2.支持多播(应该就是广播的意思?这个不太理解),在同一个netlink组中的所有进程,都可以收到消息。内核向用户传递消息时使用了这一机制。
3.netlink支持内核先发起会话,而ioctl或者说/proc观测目录只支持用户先发起请求访问。netlink、/proc、ioctl也是常用的三种内核/用户通信的方法。
3.netlink是全双工通信,内核可以发给用户,用户也可以发给内核。
4.关于netlink的具体使用方法 – Linux netlink socket使用总结
设备模型(待处理)
/sys观测目录(待处理)
/sys文件系统与设备模型强相关,所以需要先整理设备模型,再整理/sys目录,参考:sys文件系统中文件、文件夹与kobject、kset、kobj_type的对应关系
/proc观测目录以及原理待处理)
先放个链接:linux3.10 proc文件系统实现原理
常用的/proc观测节点(待处理)
先来个总览:Procfs (一) /proc/* 文件解析
关于debugfs调试文件系统(待整理)
cat和echo,是怎么实现的?(待处理)
反正最后是调用到了show和store函数中。这个一定要看:(一)总线设备驱动模型 kobject,ktype,kset
dmesg的底层原理
- dmesg 命令背后的实现原理也是通过读取 /dev/kmsg 文件来获取内核消息的。当我们在终端中执行 dmesg 命令时,它会读取/dev/kmsg 文件的内容并将其显示在终端上。
- /dev/kmsg是在何时注册的呢?是内核会为一些特殊内存设备注册一个类,名为mem,并且会在这个类下注册一个字符设备,多个设备节点共享这一个字符设备:
static const struct memdev {
const char *name;
umode_t mode;
const struct file_operations *fops;
fmode_t fmode;
} devlist[] = {
#ifdef CONFIG_DEVMEM
[1] = { "mem", 0, &mem_fops, FMODE_UNSIGNED_OFFSET },
#endif
#ifdef CONFIG_DEVKMEM
[2] = { "kmem", 0, &kmem_fops, FMODE_UNSIGNED_OFFSET },
#endif
[3] = { "null", 0666, &null_fops, 0 },
#ifdef CONFIG_DEVPORT
[4] = { "port", 0, &port_fops, 0 },
#endif
[5] = { "zero", 0666, &zero_fops, 0 },
[7] = { "full", 0666, &full_fops, 0 },
[8] = { "random", 0666, &random_fops, 0 },
[9] = { "urandom", 0666, &urandom_fops, 0 },
#ifdef CONFIG_PRINTK
[11] = { "kmsg", 0644, &kmsg_fops, 0 },
#endif
};

- 除此之外,还有一个观测节点可以观察内核缓冲区,就是/proc/kmsg
1.但是dmesg又不完全等同于/proc/kmsg,前者每次可以打印出环形缓冲区中的所有信息,但是后者只会打印出每次新的环形缓冲区的信息。
2.比如,第一次使用cat /proc/kmsg,会打印出内核启动的所有信息,第二次使用cat /proc/kmsg,就不会出现之前打印的信息,只打印继上次使用cat /proc/kmsg之后的新的信息 - /proc/sys/kernel/printk_xxx,这下面有很多printk_xxx文件,是 Linux 内核的一些控制文件,用于配置内核日志和打印设置。常用的就是修改打印等级,修改是否开启内核缓冲区等等。
添加一个ftrace和perf的使用示例(待处理)
在xx用到的:
- perf record -e cpu-clock -g -p
1.-e 指定要监控的系统信息,这里监控CPU指标
2.-g 这个参数启用了函数级别的调用图记录。这意味着perf会记录每个函数调用的堆栈信息,可以查看具体某个函数所花费的时间以及函数的调用路径。
3.-p 这个参数指定哪个进程
4.还可以加的参数有-F 99,表示每秒采样99次;-- sleep 30,采样时间30s。 - 然后通过
perf script -i xx.data > xx.txt将生成的perf.data转换为perf.txt - 这个txt可以使用三方库生成火焰图
perf底层原理分析
原理基于:Linux性能分析工具合集之——perf(二):原理解析,总结一下:
- Perf 简介 Perf 是用来进行软件性能分析的工具。 通过它,应用程序可以利用 PMU,tracepoint和内核中的特殊计数器(其实这种特殊计数器一般就是PMU)来进行性能统计。
- 当内核运行到这些 tracepoint 时,便会通知 perf。Perf 将 tracepoint 产生的事件记录下来,生成报告
- 许多体系结构都包含PMU(Performance Monitoring Unit)硬件,但是每个架构的使用方法可能不同。这个PMU其实就是一组寄存器,Cortex-A9与Cortex-A53都含有6个随事件增加的32位计数器和1个随处理器时钟周期增加的64位循环计数器。之所以能够检测,是因为这一组寄存器提供了时间(就是CPU指令周期,也就是cycle)、计数等功能。比如说我要查看一段时间内TLB miss率,对于ARM A53来说,就可以通过设置这一组PMU,把一个事件计数器设置为记录TLB miss事件(当TLB miss时会自动给该计数器+1)。至于时间呢,就通过cycle计数器,知道发生了多少个cycle,又知道CPU的主频,就可以得到这些TLB miss事件是在多长时间内发生的。
- tracepoint则是系统软件层面的实现,相当于在函数中插桩。在插桩点会调用我们为这个桩提供的probe函数(钩子函数),这个钩子我们可以自己定义,想让它打印啥就打印啥(当然tracepoint的打印不会打印到console,是打印到内核缓冲区中,类似于dmesg)。
- 如何在内核中插桩,请看贴出来的链接,总结一下就是需要:①声明一个桩函数名;②在你想插桩的地方插上这个桩;③为这个桩函数注册一个probe函数;第①、③点都有相应的内核宏来完成。
为什么delay()会占用CPU,为什么不用定时器
- delay()底层是由while循环实现的,基于BogoMIPS(百万条指令没秒),在kernel启动的时候会计算(估算)这个值。
- 尽量不要用delay,一是不一定准,二是会一直占用CPU。最好将代码设计成可以使用定时器的架构。
kernel中如何访问I/O空间
- 第一种方式,通过ioreamp,先将端口物理地址映射为虚拟地址,再通过readb/writeb,readw/writew,readl/writel以及read_relaxed来操作映射好的虚拟地址。b/w/l表示8/16/32bit地址。relaxed表示不使用内存屏障,这种方式,映射的虚拟地址也是在vmalloc区域映射的。
- 第二种方式,直接操作硬件,通过inb/outb,inl/outl直接操作硬件I/O口,但是不知道怎么实现的。
user与kernel之间使用mmap,用过吗?
- 没用过,看过,在LCD驱动中可能会用,直接通过mmap建立设备内存到用户空间的映射,减少数据的拷贝工作。像串口这种面向流的设备没有任何意义,但是显示、视频等设备很有意义。
- 归根结底,是要在kernel的mmap函数中使用remap_pfn_range(),因为用户空间使用mmap()函数时,不是会传入一个fd吗,如果这个fd实现了.mmap,那么就会调用这个驱动实现的mmap的。
- 然后驱动的mmap会使用remap_pfn_range()来做虚拟地址(使用mmap创建的VMA)与物理地址(比如说LCD的framebuffer地址)的映射
关于LCD驱动的一些信息
-
最后在看一下寄存器 LCDIF_CUR_BUF 和 LCDIF_NEXT_BUF,这两个寄存器分别为当前
帧和下一帧缓冲区,也就是 LCD 显存。一般这两个寄存器保存同一个地址,也就是划分给 LCD
的显存首地址。 -
LCD控制器层面的双缓冲
1.对与LCD控制器层面的双缓冲,指的是LCD控制器具有切换显存GRAM的功能。比如STM32的LTDC外设有一个寄存器CFBAR,即帧缓冲区地址寄存器,我们只需要定义2个帧缓冲区,在需要的时候更改这个寄存器的值,就可以达到双缓冲的效果,当然不要忘了读写指针同步,即需要设置行中断在非可视区(消隐区)更改这个寄存器。不过LTDC具有影子寄存器,设置了并不会马上更新,而是会自动在消隐区更新,由于篇幅的原因,这些内容以及思路在后面的文章会详细说明。这一层面的双缓冲的作用是用来解决画面撕裂的。 -
UI层面的双缓冲
1.而对于UI层面的双缓冲,指的是UI具有2个缓冲区可以渲染图像数据,比如lvgl的双缓冲。在lvgl使用单buffer(单缓冲)的情况下,lvgl渲染完这个buffer后,必须等待主控将整个buffer全部拷入LCD的GRAM后,才可以往这个buffer写入新的数据。其中就需要等待一段时间,而这一段等待时间就会导致UI渲染帧间隔变长,帧率变低。但如果采用双buffer(双缓冲),lvgl渲染完其中一个buffer后,该buffer被拷贝到LCD的GRAM的同时,lvgl还可以在另一个buffer中渲染下一帧数据,这样可以缩短帧间隔,提高UI渲染帧率(但通常需要多核多线程或者DMA的支持)。这么看来,UI层面的双缓冲的作用就很明显了,即提高UI渲染帧率。 -
两者的主要区别在于作用不同,一个是为了解决画面撕裂,一个是为了提高UI渲染帧率。可是这两者加起来不就需要4个缓冲区了吗,这样内存开销太大了。那能不能将2者结合在一起只用2个缓冲区呢,答案是可以的,但是是有前提条件的,对与不同驱动类型的LCD也各不相同,详细内容在这个系列后面的文章中会逐个说明。
对dtb的转换工作,最后的结果如何?
引用一篇博客中的一张图:设备树——dtb格式到struct device node结构体的转换

gpio子系统和pinctl子系统的设备树编写和其他设备不太一样,应该怎么编写?
本质还是原厂提供的GPIO驱动和pinctl驱动是怎样编写的:
- 对于GPIO子系统,我们应该在设备树中这样使用节点:
test {
pinctrl-names = "default";
pinctrl-0 = <&pinctrl_test>;
gpio = <&gpio1 0 GPIO_ACTIVE_LOW>; // gpio属性
}
- 因为对于 I.MX 系列 SOC 而言,pinctrl 驱动程序是通过读取“fsl,pins”属性值来获取 PIN 的配置信息,所以要这么写:
pinctrl_test: testgrp {
fsl,pins = <
MX6UL_PAD_GPIO1_IO00__GPIO1_IO00 config /*config 是具体设置值*/
>;
};
软终端,tasklet,工作队列的区别
- 所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保其数据结构。
- tasklet是软终端的特殊实现,同一个CPU上,只有同一个tasklet能运行。
- 软中断是在编译期间静态分配的,不像tasklet那样能动态地注册或者注销。
- 一个注册的软中断只有在标记后才会执行,中断处理程序会在返回前标记它的软中断,使其在稍后执行。在下列地方,会遍历寻找待处理的软中断并且执行:
①从中断处理程序返回后
②在ksoftirqd内核线程中
③在那些主动执行检查软中断的代码中
内核其他模块零散知识
radix tree(基数树)的优势以及在内核中的应用场景
- 基数树这种数据结构的原理:高级数据结构与算法 | 基数树(Radix Tree)。总结一下:
1.在基数树之前,使用的是字典树。这种数据结构的提出,是为了解决key-value键值对匹配的搜索问题的。使用字典树可以有效的解决key-value的搜索问题。
2.但是字典树存在一个问题,就是层数太高,因为字典树的每一个结点只能保存一个字母,如果单词都很长的话(key很长,以单词作key为例,实际上内核的基数树是以一个整型作key),字典树就会很高,节点也比较多。
3.基数树解决了这个问题,怎么解决的看上面链接。 - 在内核中,一般在使用它的key-value属性时,key会使用index,value则根据不同的用途指向不同的对象。比如说:
1.对于struct irq_desc(虚拟中断号virq对应的结构体),由于整个内核的virq是公用的,所以使用一个radix tree来扩展和维护,其中key就是virq的号码,value就是对应的struct irq_desc
2.对于i2c_adapter,使用了一个radix tree来维护。其实这个我是搞不明白的,一般也就5~6个adapter了不得了吧。key是adapter序号,value就指向adapter
3.struct address_space中,使用一棵radix tree来维护该文件的页缓存。这个很合理,可能会有很多缓存页,找起来会很费劲。key就是页帧号,value就是对应的struct page页。 - 既然key一般为index,也就是说都是数字。对于key为字符串时,很容易将节点拆成一个一个的字母。那对于一个long类型的index怎么办呢?linux的做法是分簇。比如说每6bit分成一个簇,一个簇可以组成2^6 = 64种情况,就相当于可以表示64种"字母"。难以理解的话就看下:Linux 内核之radix tree(基数树) 图文介绍,在这里贴一下老哥画的图:

假设key值等于0x840FF, 其二进制按照6bit一簇可以写成,000010-000100 -000011 -111111,从左到右的index值分别为2, 4,3, 63。那么根据key值0x840FF找到value的过程就只需要4步:
①第一步,在最上层的节点A中找到index为2的slot,其slot[2]指针指向第二层节点中的节点B。
②第二步,在节点B中找到index为4的slot,其slot[4]指针指向第三层节点中的节点C。
③第三步,在节点C中找到index为3的slot,其slot[3]指针指向第三层节点中的节点D。
④第四步,在节点D中找到index为63的slot,其slot[63]指针指向叶子节点item E。 - 所以有64bit,分簇的思想就是相当于把一个key拆分成一个个字母。对于CONFIG_BASE_SMALL,如果有这个config,就是4个子节点,否则6个:
#define RADIX_TREE_MAP_SHIFT XA_CHUNK_SHIFT
#define XA_CHUNK_SHIFT (CONFIG_BASE_SMALL ? 4 : 6)
- 更详细的讲解在这里:Linux Radix tree简介,贴一张老哥的图:

硬件设备相关
嵌入式设备的启动过程是什么样
参考:
- 2-EMMC启动及各分区文件生成过程 描述了嵌入式设备的启动流程,以及SD卡启动和EMMC启动的区别,boot放在哪里等等,非常好
1.EMMC的硬件分区通用模型就是可以划分为四个区域的分区:BOOT0,BOOT1,RPMB,USERDATA区
2.一般BOOT0,BOOT1存放的是启动内容,嵌入式系统的启动与x86电脑的启动类似,请看:玄铁处理器的Linux移植(二)—U-Boot SPL - 对于ARM芯片来说,启动流程一般是这样的:BL0->BL1->BL2->kernel,与x86不同
1.BL0对应ROM代码,一般我们无法修改,主要作用就是初始化ISRAM和EMMC,然后判断硬件的启动方式(可能是通过某些引脚来判断),根据启动方式去不同的存储设备中加载BL1
2.BL1在TDA4-VH中,对应的就是Uboot-spl,这个就不多介绍了
3.BL2对应的就是uboot
关于emmc的RPMB分区与BOOT分区
- RPMB原理介绍 ---- eMMC安全方案—RPMB(Replay Protected Memory Block)
- 如何修改boot0/boot1区的大小 – eMMC分区管理,提到BOOT0/BOOT1分区大小可以修改,一般最大可以修改为 255 x 128 KB = 32640 KB = 31.875 MB大小,大约32MB
- 一般情况下,Boot Area Partition 的大小是128KB的倍数(没错,RPMB分区也基于BOOT这个值),EMMC中默认为 4 MB,即 RPMB_SIZE_MULT 为 32,部分芯片厂家会提供改写 RPMB_SIZE_MULT 的功能来改变 RPMB Partition 的容量大小。RPMB_SIZE_MULT 最大可以为 128,即 Boot Area Partition 的最大容量大小可以为 128 x 128 KB = 16384 KB = 16 MB
- BOOT分区没什么好说的,对RPMB的保护机制做一个总结:
1.RPMB使用对称密钥身份验证,其中主机和设备都使用相同的身份验证密钥(此密钥也称为“共享密钥”)。其工作方式:
①RPMB身份验证密钥信息首先由主机编程到eMMC设备(这必须在安全环境中进行,通常在生产线上安装rpmb key)。
②然后,主机和设备都使用身份验证密钥对涉及RPMB区域的读写消息进行签名和身份验证,类似SSH
③对消息进行签名涉及到一个消息认证码(MAC),它是使用HMAC SHA-256算法计算的(简单来讲,就是通过秘钥计算一个256bit的MAC值)。
④RPMB还有防止重放攻击这个功能,通过一个计数器writer counter实现,每写入一次就加一。RPMB的写操作的加密需要使用这个wrtier counter计数器,防止重放攻击。 - 具体的读写过程,参考 – RPMB原理介绍
- 什么是重放攻击 – 什么是计算机安全领域的重放攻击。重放攻击就是欺骗服务端,执行某一项服务。在了解了这个之后,我认为RPMB的读服务是不保护重放攻击的,就算有人欺骗EMMC执行了一次读取,但是读取的数据是加密过的,所以你也不知道是啥。但是RPMB的写服务是要保护重放攻击的,防止有人恶意篡改RPMB分区数据。
inux软件分区的注册/块设备驱动(比如UDA区的GPT分区):
EMMC的GPT分区管理
GPT分区管理划分的是软件分区,但是:
- 每个软件分区都有自己的文件系统和superblock,每一个分区的第一个block中会记录superblock – Linux文件系统之二:硬盘分区partition的组织和管理
异构核间通信实现
- 首先,TDA4核间通信是基于TI提供的Mailbox机制,本质是共享内存+中断。
- 首先介绍下Mailbox机制:TDA4 IPC 原理
- 这篇文章,对TDA4核间通信进行了一个实验(没启用IPC,跟reboot一样mcu域通过轮询来查询共享内存),这说明了这种方法的劣势所在:TDA4核间通信
- 这篇文章,对TDA4的Mailbox讲解的更细致一点:TDA4VM/VH 芯片硬件 mailbox
- mailxbox产生的中断通过INTR IN_INTR[447:384]输入到NAVSS0中。NAVSS0又通过OUTL_INTR输出到各个核中,NAVSS0相当于是一个复杂外设,相当于一个片外中断控制器 – TDA4VM/VH 芯片 NAVSS0,其中MAILBOX0也并不直接作为某一个芯片域的外设,而是集成在 NAVSS0 模块下。

MAILBOX0 可生成的48个中断,由INTR_IN[439:392] 捕获。对于 INTR_ROUTER0 的某一个中断输入,我们可以将该中断输入信号绑定到某一指定的 INTR_ROUTER0 的中断输出信号上,实现中断路由功能。这样就可以将MailBox的中断路由到不同的核上了,过程就是:MailBox触发中断---->通过NAVSS0的中断输入,输入到NAVSS0中---->经过NAVSS0的路由机制,从NAVSS0的输出再输出出去---->NAVSS0的输出连接到哪个核上都是固定的。 - 涉及到具体的实现过程就是:MAILBOX0共实现了12个邮箱,每一个邮箱都可以产生4个不同的中断,所以,每一个邮箱都可以为4个处理器提供核间通信。每一个邮箱都实现了两类中断:队列接收消息中断 + 队列未满中断,每一个邮箱拥有16个队列,每一个队列可以单独使能或失能上述两类中断,接收的处理器可以读取 MAILBOX_MESSAGE_[0:15], 实现从邮箱的指定队列读取消息。
- 所以要实现通信,可以开启队列接受消息中断。将邮箱0的队列0作为接受队列连到core0上,将邮箱1的队列1作为接受队列连到core1上,那么我core0想通知core1,就往队列1中写消息,触发中断通知core1读数据就行了。
关于升级固件的制作方式
- 固件升级是将一个大包固件,拆成一个一个的小包固件,将小包进行一个一个的下载。小包存储的位置是EMMC UDA区的某几个GPT分区(有些放在BOOT0区,比如uboot,有些不需要下载,比如GPT-coredump区)。
- 因为每个GPT分区都有自己的文件系统(也有可能有的没有设置文件系统,看需求),所以制作小包固件镜像的时候,要使用特定的工具,按照特定的文件系统制作镜像(一般制作工具可以用开源的,或者原厂提供的)。有篇博客做了个实验,在高通平台上新增一个GPT分区,设置该GPT分区的文件系统,然后制作对应的镜像:Linux 如何在emmc增加分区《Rice linux 学习开发》
- 对于有文件系统的GPT partiton,就可以直接挂载到某个目录下了,kernel可以对其文件读写。
- 镜像的制作,就是中台的事了,也就是说,出包的工作肯定由中台来做,一般需要根据原厂提供的工具制作相应的镜像来制作,需要考虑的无非就是包中需要存在哪些文件/文件夹?要使用哪种文件系统?等等。镜像img文件可以简单理解为一个磁盘,可以存放二进制数据,可以进行分区,可以建立文件系统等操作。
为什么有了CRC之后还需要验签
- CRC是用来校验小包固件是否出错,是否是上位机传输下来的固件,检测传输过程中有没有出问题。而且CRC得除数,也就是生成多项式,是固定的…一直不知道这个点,尬住了。
- 验签用来校验是否是该厂商提供的包,而不是其他人伪造的固件。
EEP驱动为什么使用1M的i2c速率,为什么不用400K的?不同速率有什么影响?
- 不同速率影响,最大的考虑点就是你的设备和控制器支不支持这个速率,现在一般有100k标准模式,400k快速模式,1M快速模式plus,3.4M高速模式,还有个5M的单向通信模式
- 为什么项目的EEP用1M呢?是因为项目用的EEP支持1M,项目用的EEP是M24m01/M24256/M24512,这几款都支持1M i2c通信,区别就是容量不同 – 意法半导体发表1MHz双线串行总线EEPROM存储器芯片
LCD常用的接口?
通用知识
coredump保存了哪些数据?
- Core Dump文件主要包含了用户空间的内存信息,包括用户空间栈、代码段、数据段和堆等。然而,出于安全和隔离的考虑,Core Dump文件通常不包含内核空间栈的信息
- 保存的数据可以通过echo “core-%e-%p-%s-%t” > /proc/sys/kernel/core_pattern进行修改。也可以针对单独的进程进行修改,通过echo “core-%e-%p-%s-%t” > /proc/pid/coredump_filter。甚至可以修改转存的路径已经core文件名。
- coredump的原理就是系统调用、异常、中断等陷入内核空间的机制,在从内核返回到用户空间时,会调用do_signal()->get_signal()处理信号(在系统调用那里我也分析过)。会产生coredump的信号包括:SIGQUIT、SIGILL、SIGTRAP、SIGABRT、SIGFPE、SIGSEGV、SIGBUS、SIGSYS、SIGXCPU、SIGXFSZ
- 首先执行ulimit -c unlimited,打开coredump功能。出现coredump后,会在当前进程的工作目录下产生一个core文件(默认文件名为core),使用xx-linux-gdb ./你执行的进程elf文件名 core命令,会显示一些头信息,然后就可以进行调试:https://www.cnblogs.com/arnoldlu/p/9633254.html#core_gdb。
- 链接:coredump介绍链接:https://www.cnblogs.com/arnoldlu/p/11160510.html#do_signal
反汇编
链接:https://blog.youkuaiyun.com/xi_xix_i/article/details/134030023?spm=1001.2014.3001.5501
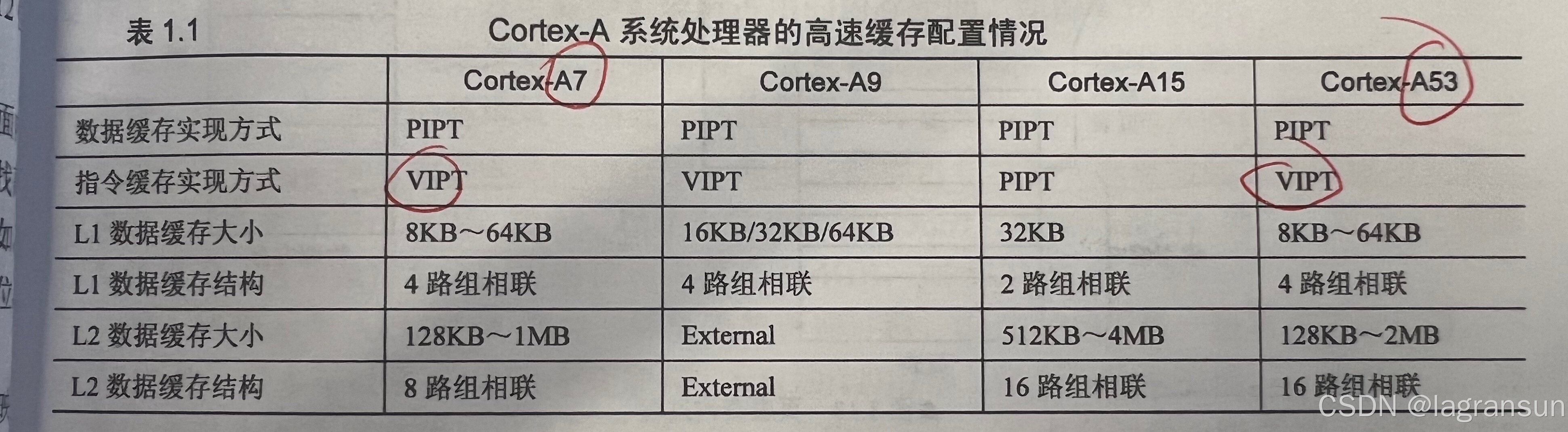
cache/cache 一致性
- cortextA7/cortex-A53的缓存类型都是PIPT(通过物理地址寻找cache缓存),此时物理地址的高位部分是TAG域(用来与cache行对应的TAG进行比较),中间一部分是索引域(索引高速缓存的第几行),低位部分是偏移量(一路缓存行32B,表示在缓存行中的偏移)
- cortextA7/cortex-A53L1大小:8KB~64KB,4路组相连。如果配置成32KB,那么一路就是8KB,缓存行大小为32B那么就有8KB/32B = 256个缓存行。
- 一致性协议:MESI,M(修改,Modified),E(独占,Exclusive),S(共享,Shared),I(失效,Invalid)
- 有的时候为了防止高速缓存伪共享,需要将结构体中变量进行缓存行对齐(使某一个变量独占一个缓存行,32B),内核中很多结构体都是用了这种方式,对一些多线程共享并且常操作的结构体经常进行对齐。
- 有空在这里找个高速缓存伪共享例子
用户空间调malloc分配20M的整个流程
- 先说一下malloc()的分配流程,glibc的malloc会在小于128KB时有brk(),大于128KB时用mmap(),关于这俩系统调用,先不考虑。

- 当使用brk()时,只会把堆区(堆区是有个VMA来表示的)的brk向上推,下次访问这个地址时,缺页中断异常中检测该地址确实在这个VMA中(因为把堆区这个VMA扩大了),但是没分配,所以分配物理页。使用mmap()时,则直接申请一个私有匿名映射就OK了,这样会新建一个VMA。
- 使用free释放时,brk()扩大的堆区VMA不一定被释放,因为malloc()库自己封装了一个内存池,先存着,防止下次再申请。但是使用mmap()申请的内存会被释放。
- 所以回到这一点,分配20MB的内存,直接就是用mmap申请了一个私有匿名映射。
示波器的使用方法
访问野指针报错的原理是什么?
- 请看上一条,对于不同的野指针,可能有不同的情况,但是归根结底是触发了缺页异常(没有页表项/页表项权限不对),然后在缺页异常处理中,判断出该虚拟地址没有对应的VMA,或者说对应的VMA权限不对。
访问空指针为什么会报错呢?
- 访问空指针,其实就是访问了一个不可读写的页表项!,而且不只是0地址,按说那个4KB大小的地址,都是不可访问的!确实不可访问,而且已经看懂了怎么能让程序可以访问NULL指针。
缺页为什么不会coredump?
- 如果指的是触发了缺页中断,那是很可能coredump的,有一些错误会在缺页异常中检测出来,返回对应的SIG信号,如果信号不好的话就会coredump
- 如果指的是缺页之后正常处理,那肯定不会coredump,
访问野指针,也是异常,为什么这个时候系统没有崩溃?
- 这个不好说,有两种野指针不会崩溃,但是有一种野指针会崩溃,还是得往缺页异常的本质上去靠拢。
先申请一个20字节的memory,然后往里面写入200字节的数据,会coredump吗?
- 不会,试过了。
gdb调试的原理?使用了哪些系统调用?不同指令的执行原理是怎么样的?
宏内核和微内核什么区别?
- 首先,得分析一下什么叫内核?内核就是操作系统的核心组件,它是连接硬件和软件的关键纽带。内核负责管理和控制计算机的各种硬件资源,为上层应用程序提供统一的接口和服务。总的来说,内核就是对下负责管理硬件资源,对上为应用程序提供服务。
- 宏内核是一种将操作系统的大部分功能全部集成到单一的内核程序中的内核设计方式,在这种设计中,内核包含了进程管理、内存管理、文件系统、设备驱动程序等多种核心功能。这些模块只有处于内核态下才可以运行。
- 宏内核操作系统的优缺点
优点:
①高性能: 宏内核将操作系统的所有功能集成在一个单一的大内核中,减少了模块之间的通信开销,提高了整体性能。
②简单架构:宏内核的设计相对简单,代码量较小,便于理解和维护。
③函数丰富:宏内核包含完整的操作系统功能,可以直接为应用程序提供各种服务和系统调用。
④稳定性高:由于功能集中,出错概率降低,系统稳定性较高。
缺点:
①缺乏模块化:宏内核将所有功能集成在一起,缺乏良好的模块化设计,难以扩展和维护。
②内核体积大:由于功能集中,内核代码量大,容易出现冗余和膨胀。
③可靠性差:一个组件的错误可能会影响整个内核,降低系统可靠性。
④缺乏灵活性:由于功能集成在一起,很难对内核进行有选择性的修改或裁剪。这一点我个人认为就是冗余导致的,一个模块的实现经常依赖于其他模块,比如中断线程化,驱动模块的实现要依赖于调度模块。 - 微内核则和宏内核结构相反,它将系统的核心功能精简到最小,内核只提供最核心的功能,比如任务调度、中断处理等。将其他非核心功能移出,作为独立的服务进程运行在用户态。并以C/S(客户端/服务器)模型为应用程序提供服务。
- 微内核中定义了一种进程间通信的机制------消息。当应用程序请求相关服务时,会向微内核发送一条与此服务对应的消息,微内核再把这条消息发送给相关的服务进程,接着服务进程会完成相关的服务。这就是QNX中的消息,QNX中的一切仿佛都是消息机制
- 我们举一个应用程序读取一个文件的例子。首先,应用程序调用文件系统API,比如open()函数,请求打开一个文件。操作系统内核识别这是一个文件系统相关的请求,便将其转发给负责文件系统的服务进程。文件系统服务进程接收到打开文件的请求,根据文件路径在磁盘上查找对应的文件数据块,并将文件的元数据信息返回给内核。内核将文件元数据信息返回给应用程序,比如文件描述符、文件大小等。*在这里,文件系统作为一个服务进程,运行在用户态,而不是像linux一样,将虚拟文件系统/文件系统作为内核祖先放在内核态运行
- 除此之外还有很多例子,我觉得QNX的网络协议栈就是作为一种运行在用户态的服务进程,不像linux一样是运行在内核中的。
- 微内核操作系统的优缺点:
优点
①高可靠性和可扩展性:关键内核功能最小化,减少内核代码的复杂度和错误概率。各服务进程相互隔离,一个服务进程的故障不会影响整个系统。可以根据需求有选择地集成所需的服务模块,提高系统的可定制性。
②高安全性: 内核与服务进程间的特权级隔离,提高了系统的安全性。可以有针对性地增加可信服务模块,满足关键系统的安全需求。
③高实时性: 关键实时任务可直接在内核中运行,不受其他服务模块的影响。内核功能最小化,上下文切换开销较小。
④良好的可移植性: 微内核结构清晰,便于移植到不同硬件平台。服务模块相对独立,便于跨平台移植。
缺点:
①性能损耗:服务进程间的通信会带来一定的性能开销。部分功能从内核空间移到用户空间会影响系统性能。
②设计复杂度:微内核设计需要解决进程间通信、资源管理等复杂问题。需要仔细权衡哪些功能放在内核中,哪些放在用户空间。

















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









