



 本文详细解析了StableDiffusion1.5模型的网络结构,特别关注了Unet部分,包括CrossAttnDownBlock2D和CrossAttnUpBlock2D的变化,以及如何融入CLIP技术。作者解释了时间ID的使用和训练技巧。
本文详细解析了StableDiffusion1.5模型的网络结构,特别关注了Unet部分,包括CrossAttnDownBlock2D和CrossAttnUpBlock2D的变化,以及如何融入CLIP技术。作者解释了时间ID的使用和训练技巧。
强烈推荐先看本人的这篇
Stable Diffusion1.5网络结构-超详细原创-优快云博客
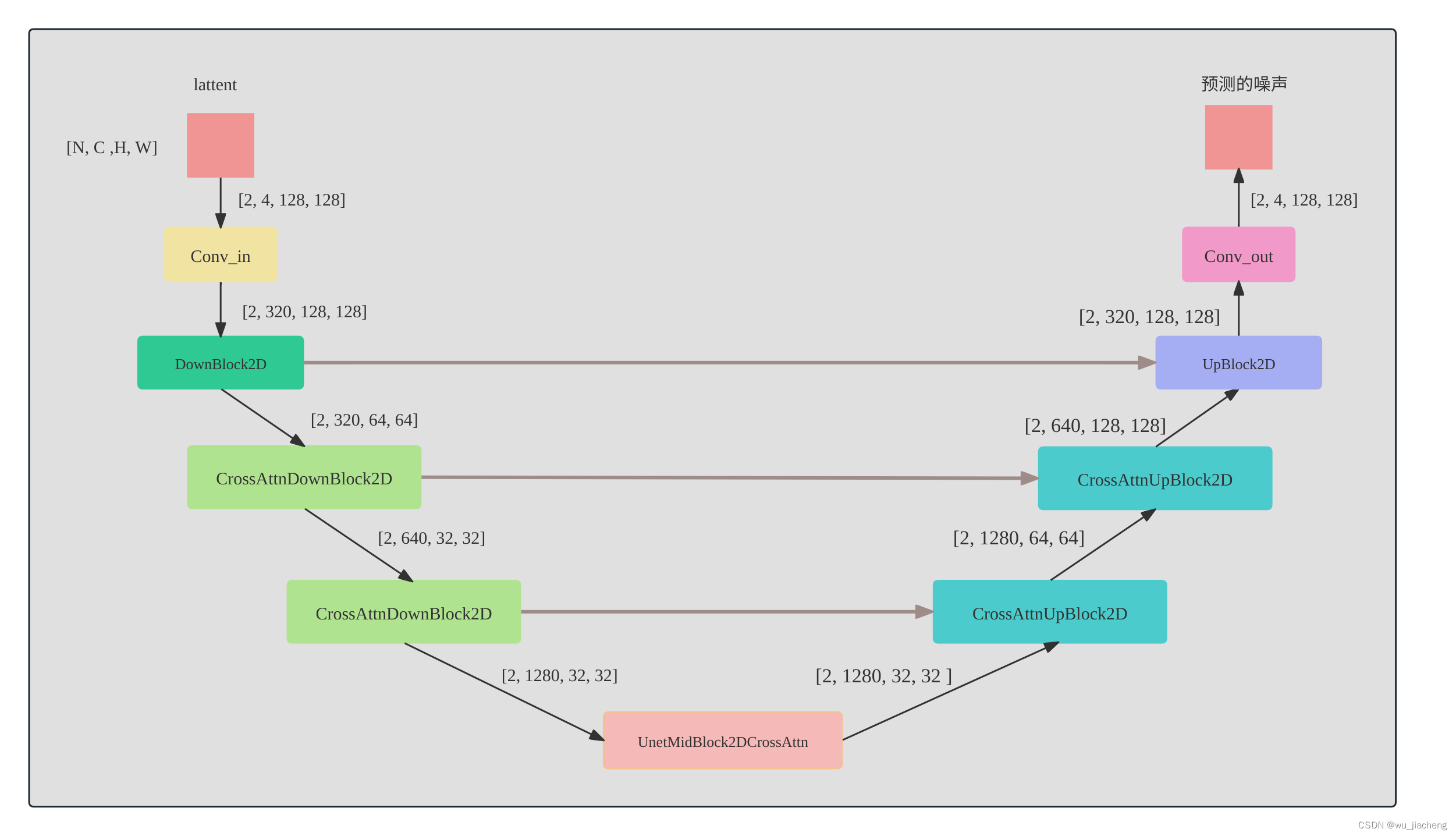
1 Unet
1.1 详细整体结构

1.2 缩小版整体结构
以生成图像1024x1024为例,与SD1.5的3个CrossAttnDownBlock2D和CrossAttnUpBlock2D相比,SDXL只有2个,但SDXL的CrossAttnDownBlock2D模块有了更多的Transformer模块,且只进行了两次下采样,具体的往下看
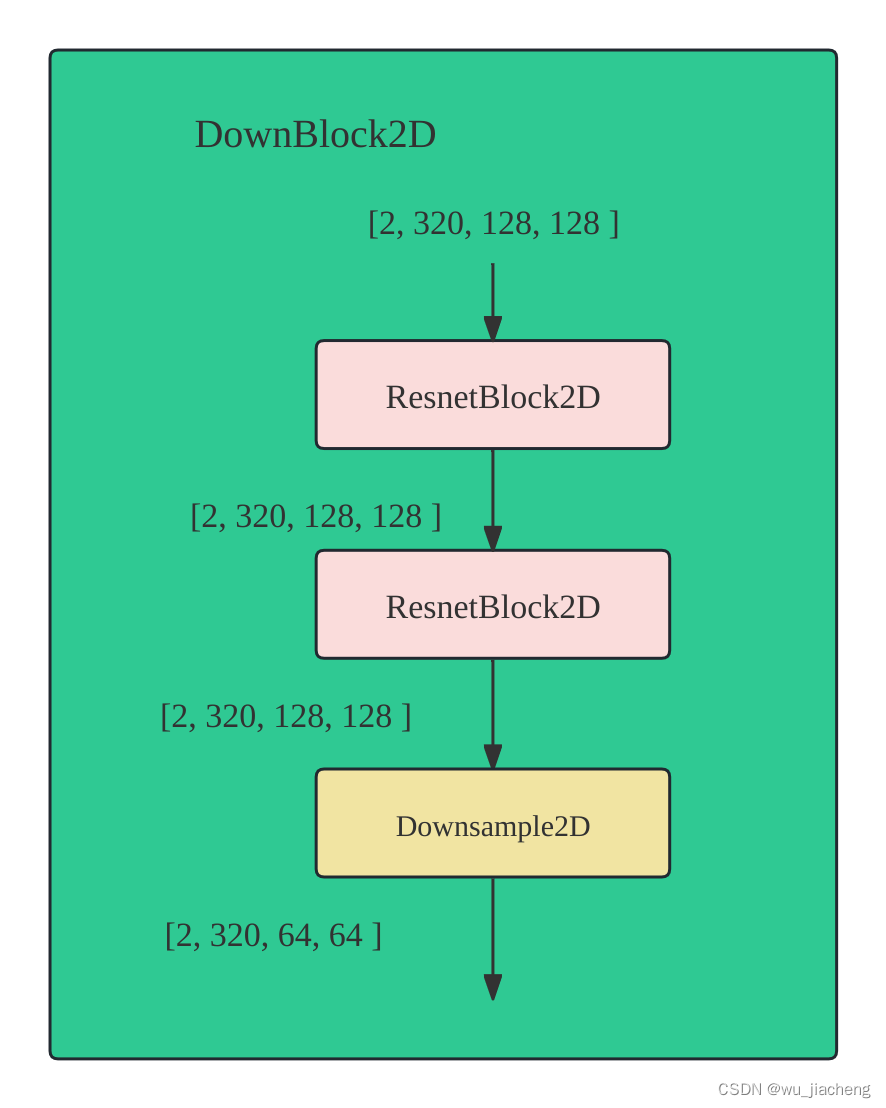
1.2.1 DownBlock2D
1.2.1.1 ResBolck2D
和SD1.5不一样的是,多了time_id这个输入,表示origin_size, target_size,以及裁剪坐标,比如图中的time_id=[[1024, 1024, 0, 0, 1024, 1024],[1024, 1024, 0, 0, 1024, 1024]]
有一半是负向提示词,以[1024, 1024, 0, 0, 1024, 1024],为例,两个[1024, 1024]表示origin_size, target_size,[0, 0]是裁剪坐标,这是SDXL在训练的时候用了一些trick,把原始输入图像和目标图像的大小,以及裁剪坐标也作为条件参与训练
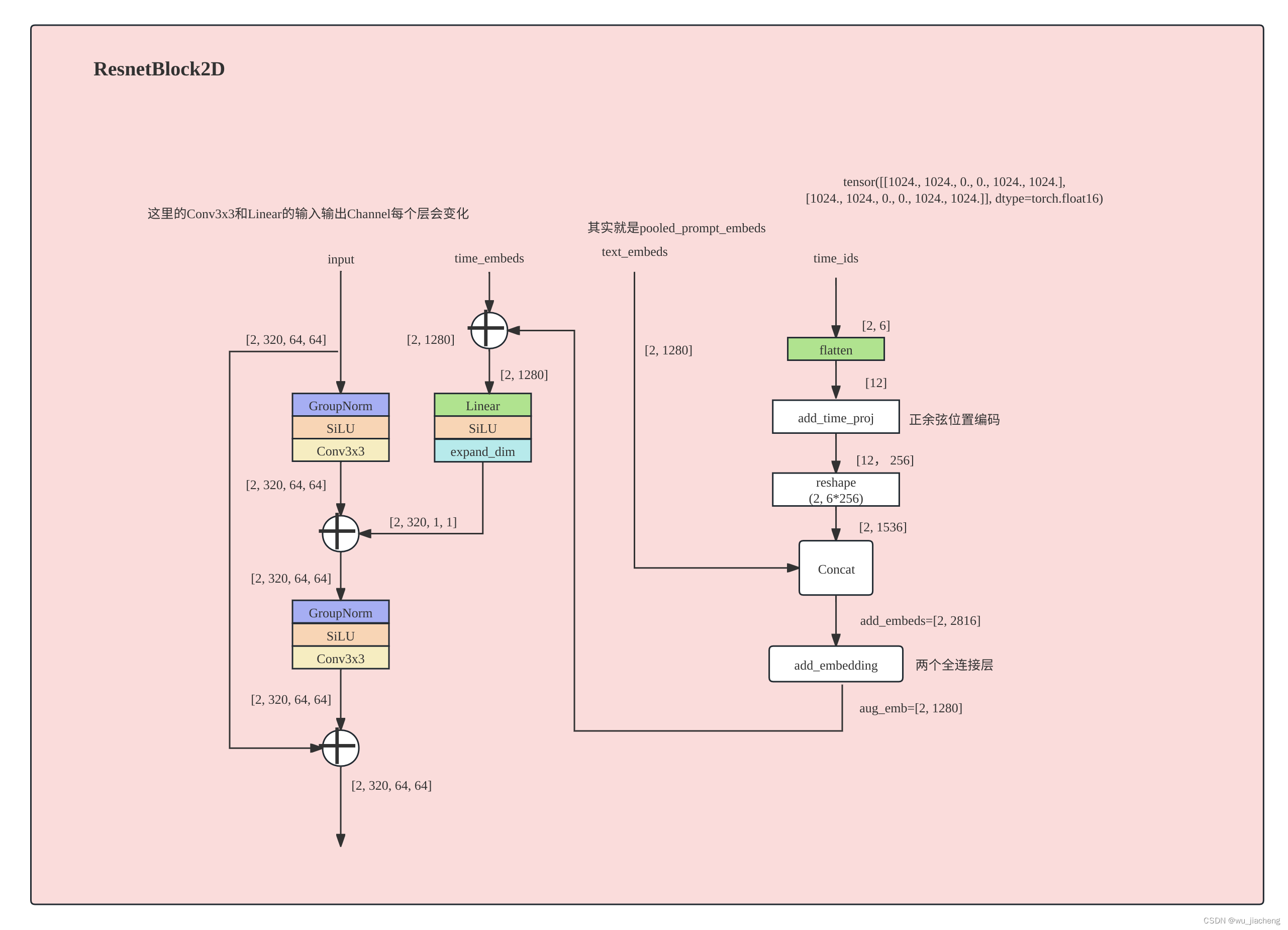
Downsample2D通过步长为2的卷积进行下采样
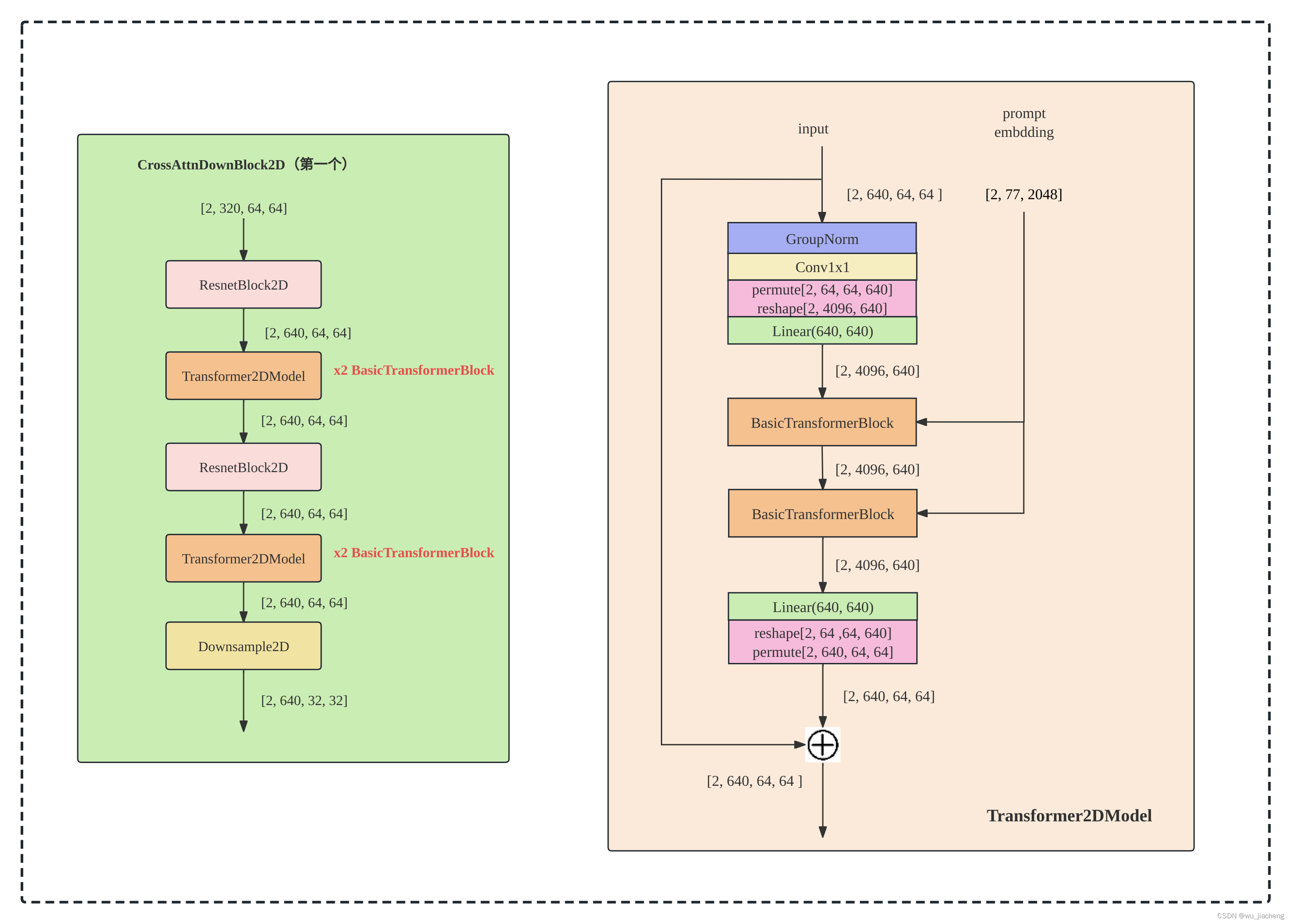
1.2.2 CrossAttnDownBlock2D
CrossAttnDownBlock2D_1
CrossAttnDownBlock2D_1表示第一个CrossAttnDownBlock2D,它的Transformer2DModel有两个BasicTransformerBlock,而SD1.5的Transformer2DModel只有一个BasicTransformerBlock
CrossAttnDownBlock2D_2
CrossAttnDownBlock2D_2表示第2个CrossAttnDownBlock2D,它的Transformer2DModel有10个BasicTransformerBlock

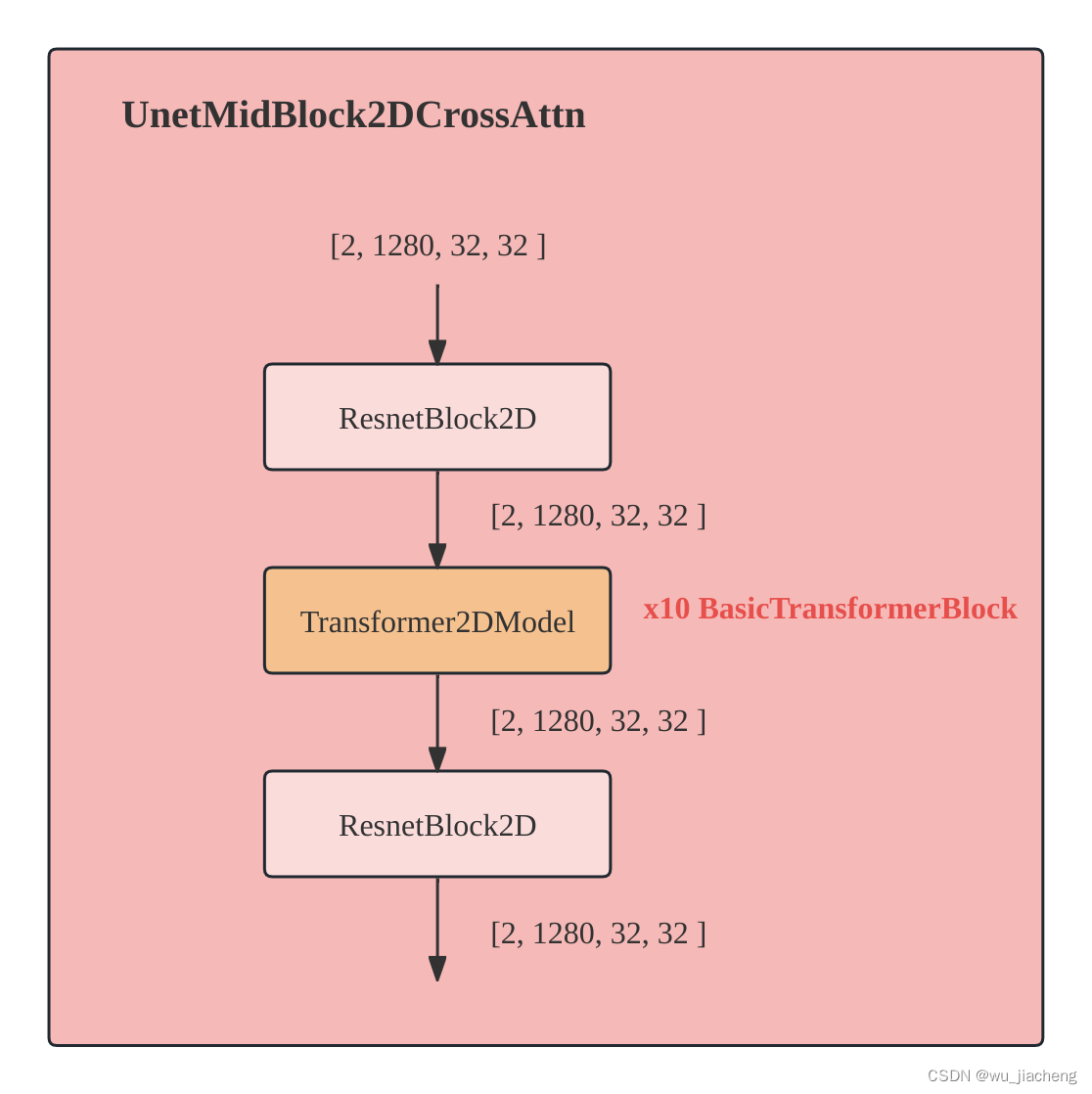
1.2.3 UnetMidBlock2DCrossAttn
其中的Transformer2DModel有10个BasicTransformerBlock
1.2.4 CrossAttnUpBlock2D
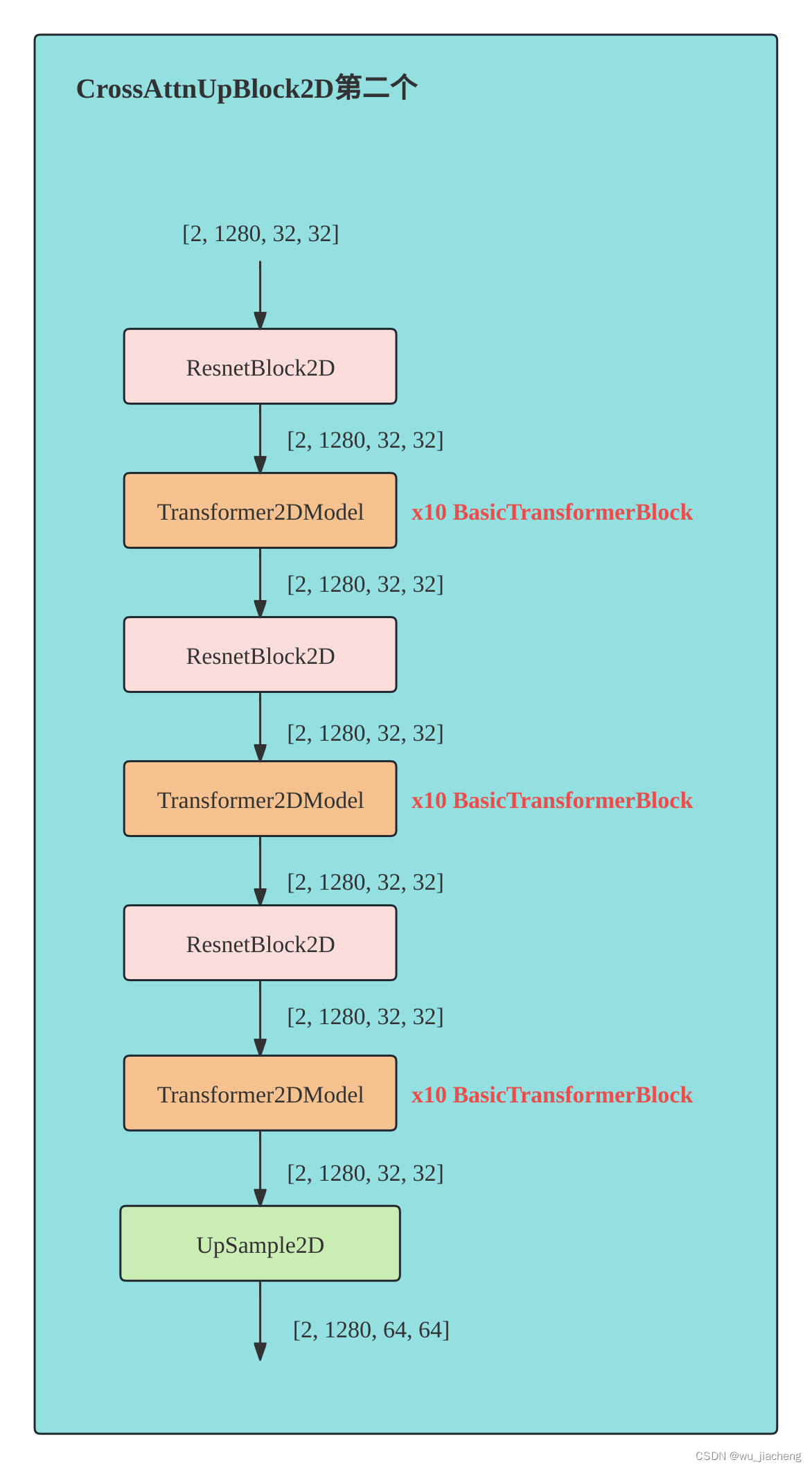
CrossAttnUpBlock2D_2
CrossAttnUpBlock2D_2表示第2个CrossAttnUpBlock2D,它的Transformer2DModel有10个BasicTransformerBlock,UpSample2D和SD1.5结构一致
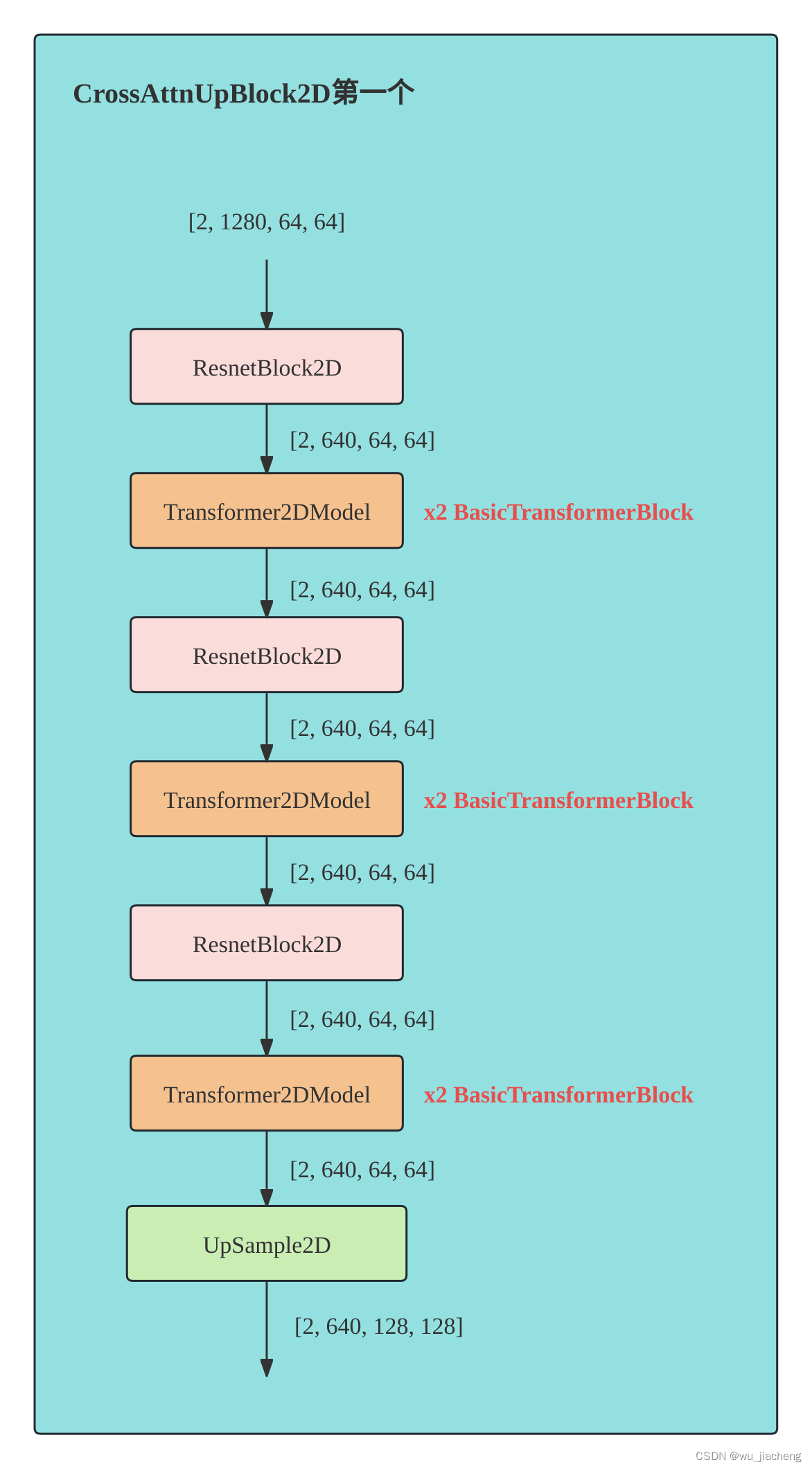
CrossAttnUpBlock2D_1
CrossAttnUpBlock2D_1表示第21个CrossAttnUpBlock2D,它的Transformer2DModel有2个BasicTransformerBlock
未完待续


















 1463
1463









 到【灌水乐园】发言
到【灌水乐园】发言







